Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCensored Sampling of Diffusion Models Using 3 Minutes of Human Feedback
Jul 06, 2023
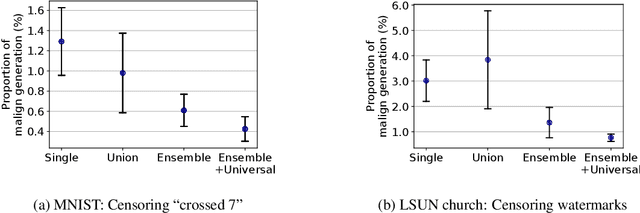
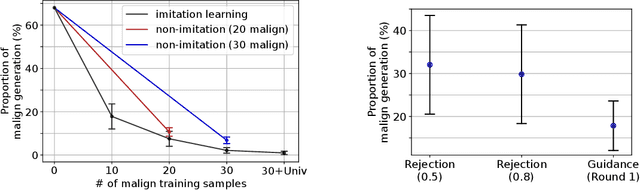
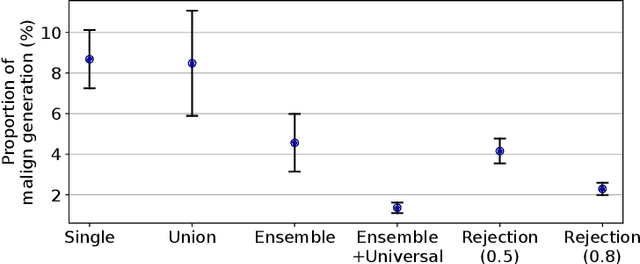
Diffusion models have recently shown remarkable success in high-quality image generation. Sometimes, however, a pre-trained diffusion model exhibits partial misalignment in the sense that the model can generate good images, but it sometimes outputs undesirable images. If so, we simply need to prevent the generation of the bad images, and we call this task censoring. In this work, we present censored generation with a pre-trained diffusion model using a reward model trained on minimal human feedback. We show that censoring can be accomplished with extreme human feedback efficiency and that labels generated with a mere few minutes of human feedback are sufficient. Code available at: https://github.com/tetrzim/diffusion-human-feedback.
Via