 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrioritizing Informative Features and Examples for Deep Learning from Noisy Data
Paper and Code

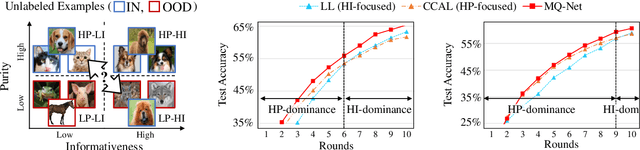
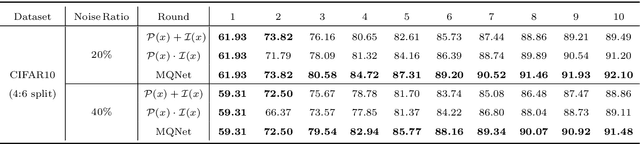
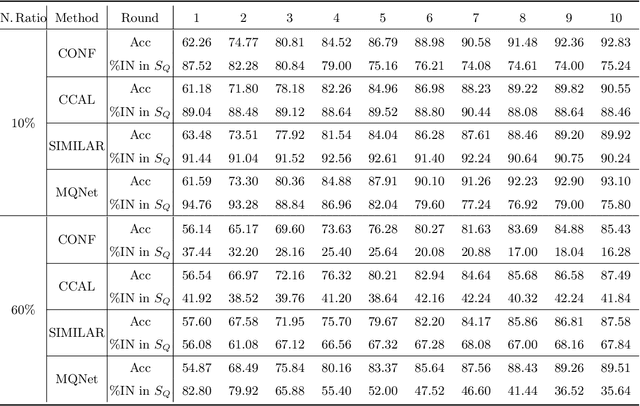
In this dissertation, we propose a systemic framework that prioritizes informative features and examples to enhance each stage of the development process. Specifically, we prioritize informative features and examples and improve the performance of feature learning, data labeling, and data selection. We first propose an approach to extract only informative features that are inherent to solving a target task by using auxiliary out-of-distribution data. We deactivate the noise features in the target distribution by using that in the out-of-distribution data. Next, we introduce an approach that prioritizes informative examples from unlabeled noisy data in order to reduce the labeling cost of active learning. In order to solve the purity-information dilemma, where an attempt to select informative examples induces the selection of many noisy examples, we propose a meta-model that finds the best balance between purity and informativeness. Lastly, we suggest an approach that prioritizes informative examples from labeled noisy data to preserve the performance of data selection. For labeled image noise data, we propose a data selection method that considers the confidence of neighboring samples to maintain the performance of the state-of-the-art Re-labeling models. For labeled text noise data, we present an instruction selection method that takes diversity into account for ranking the quality of instructions with prompting, thereby enhancing the performance of aligned large language models. Overall, our unified framework induces the deep learning development process robust to noisy data, thereby effectively mitigating noisy features and examples in real-world applications.