 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScene Co-pilot: Procedural Text to Video Generation with Human in the Loop
Nov 26, 2024Video generation has achieved impressive quality, but it still suffers from artifacts such as temporal inconsistency and violation of physical laws. Leveraging 3D scenes can fundamentally resolve these issues by providing precise control over scene entities. To facilitate the easy generation of diverse photorealistic scenes, we propose Scene Copilot, a framework combining large language models (LLMs) with a procedural 3D scene generator. Specifically, Scene Copilot consists of Scene Codex, BlenderGPT, and Human in the loop. Scene Codex is designed to translate textual user input into commands understandable by the 3D scene generator. BlenderGPT provides users with an intuitive and direct way to precisely control the generated 3D scene and the final output video. Furthermore, users can utilize Blender UI to receive instant visual feedback. Additionally, we have curated a procedural dataset of objects in code format to further enhance our system's capabilities. Each component works seamlessly together to support users in generating desired 3D scenes. Extensive experiments demonstrate the capability of our framework in customizing 3D scenes and video generation.
Mitigating Dialogue Hallucination for Large Multi-modal Models via Adversarial Instruction Tuning
Mar 15, 2024
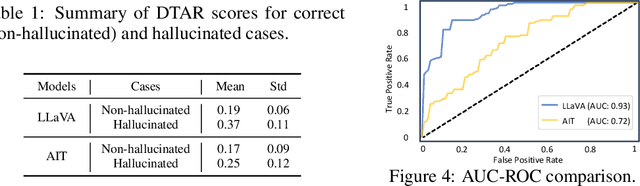
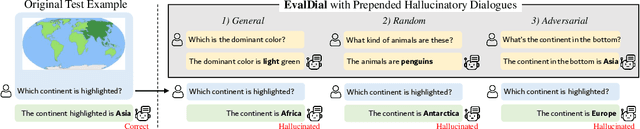
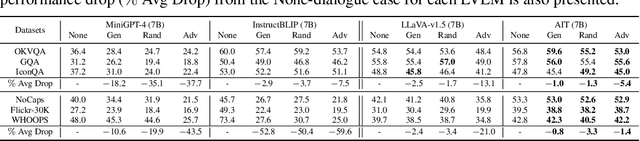
Mitigating hallucinations of Large Multi-modal Models(LMMs) is crucial to enhance their reliability for general-purpose assistants. This paper shows that such hallucinations of LMMs can be significantly exacerbated by preceding user-system dialogues. To precisely measure this, we first present an evaluation benchmark by extending popular multi-modal benchmark datasets with prepended hallucinatory dialogues generated by our novel Adversarial Question Generator, which can automatically generate image-related yet adversarial dialogues by adopting adversarial attacks on LMMs. On our benchmark, the zero-shot performance of state-of-the-art LMMs dropped significantly for both the VQA and Captioning tasks. Next, we further reveal this hallucination is mainly due to the prediction bias toward preceding dialogues rather than visual content. To reduce this bias, we propose Adversarial Instruction Tuning that robustly fine-tunes LMMs on augmented multi-modal instruction-following datasets with hallucinatory dialogues. Extensive experiments show that our proposed approach successfully reduces dialogue hallucination while maintaining or even improving performance.