 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Action Detection in Video Surveillance using Sub-Action Descriptor with Multi-CNN
Paper and Code
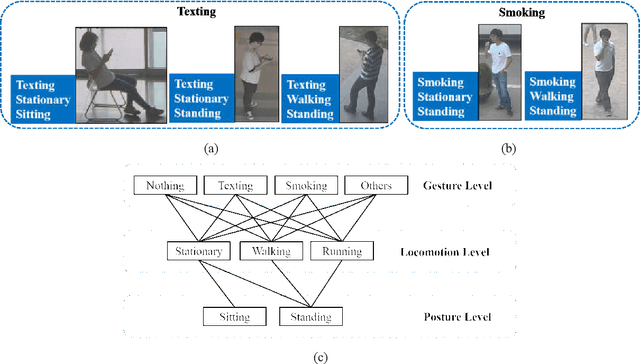

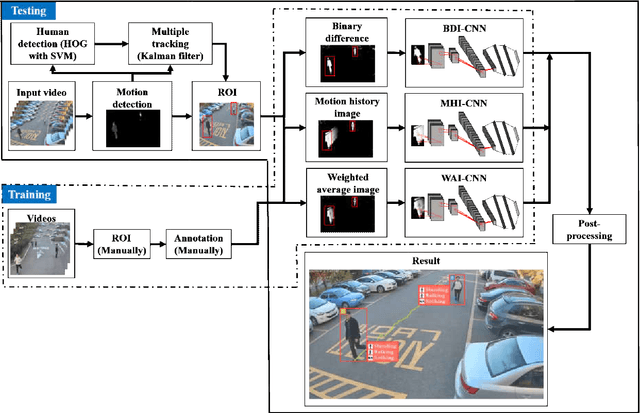
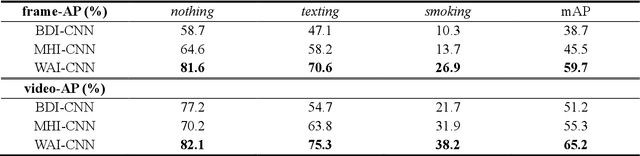
When we say a person is texting, can you tell the person is walking or sitting? Emphatically, no. In order to solve this incomplete representation problem, this paper presents a sub-action descriptor for detailed action detection. The sub-action descriptor consists of three levels: the posture, the locomotion, and the gesture level. The three levels give three sub-action categories for one action to address the representation problem. The proposed action detection model simultaneously localizes and recognizes the actions of multiple individuals in video surveillance using appearance-based temporal features with multi-CNN. The proposed approach achieved a mean average precision (mAP) of 76.6% at the frame-based and 83.5% at the video-based measurement on the new large-scale ICVL video surveillance dataset that the authors introduce and make available to the community with this paper. Extensive experiments on the benchmark KTH dataset demonstrate that the proposed approach achieved better performance, which in turn boosts the action recognition performance over the state-of-the-art. The action detection model can run at around 25 fps on the ICVL and more than 80 fps on the KTH dataset, which is suitable for real-time surveillance applications.