 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Automatic Evaluation Methods based on a Decoder-based LLM for Text Generation
Oct 17, 2023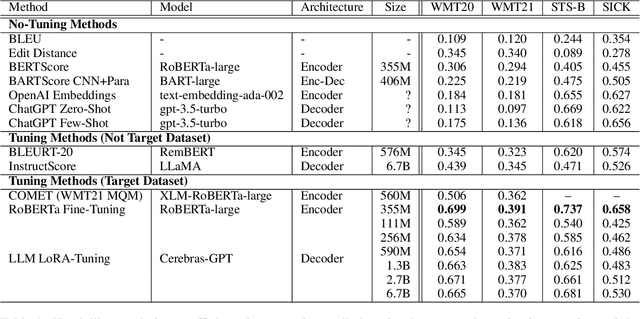
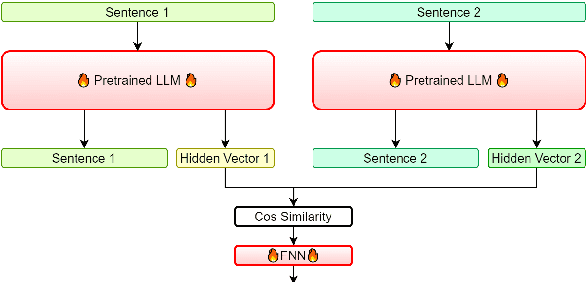

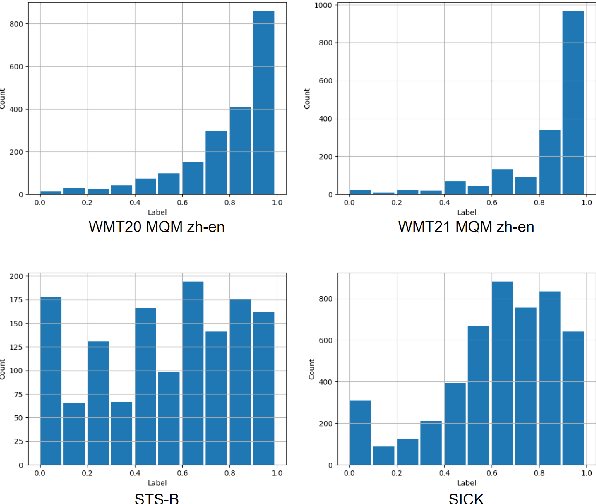
Automatic evaluation of text generation is essential for improving the accuracy of generation tasks. In light of the current trend towards increasingly larger decoder-based language models, we investigate automatic evaluation methods based on such models for text generation. This paper compares various methods, including tuning with encoder-based models and large language models under equal conditions, on two different tasks, machine translation evaluation and semantic textual similarity, in two languages, Japanese and English. Experimental results show that compared to the tuned encoder-based models, the tuned decoder-based models perform poorly. The analysis of the causes for this suggests that the decoder-based models focus on surface word sequences and do not capture meaning. It is also revealed that in-context learning of very large decoder-based models such as ChatGPT makes it difficult to identify fine-grained semantic differences.
Building a Personalized Dialogue System with Prompt-Tuning
Jun 11, 2022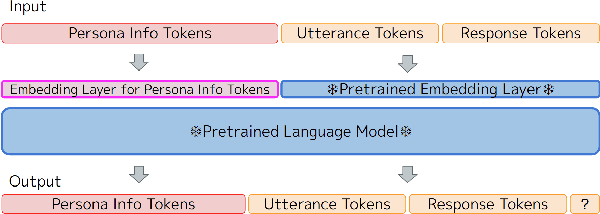
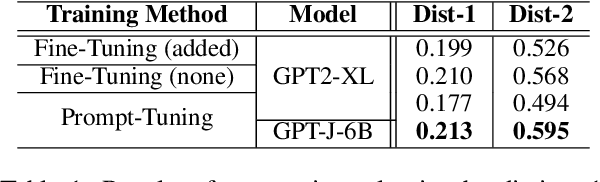
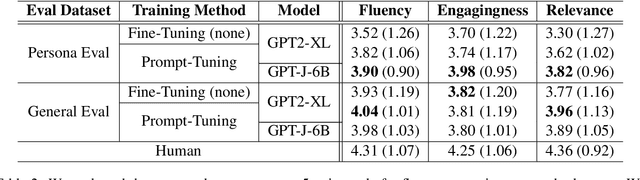
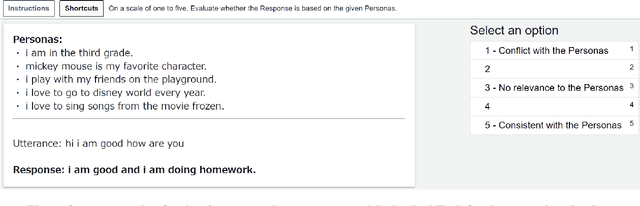
Dialogue systems without consistent responses are not fascinating. In this study, we build a dialogue system that can respond based on a given character setting (persona) to bring consistency. Considering the trend of the rapidly increasing scale of language models, we propose an approach that uses prompt-tuning, which has low learning costs, on pre-trained large-scale language models. The results of automatic and manual evaluations in English and Japanese show that it is possible to build a dialogue system with more natural and personalized responses using less computational resources than fine-tuning.