 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Automatic Evaluation Methods based on a Decoder-based LLM for Text Generation
Paper and Code
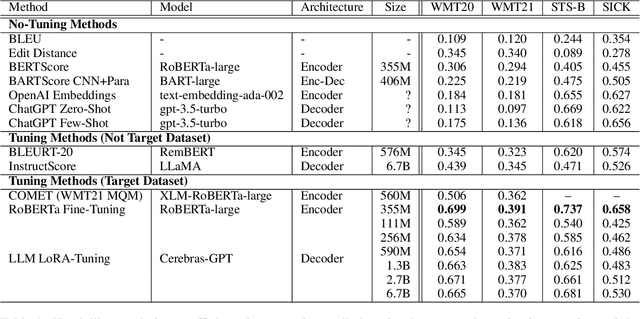
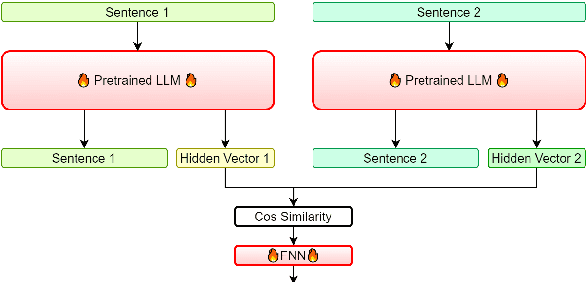

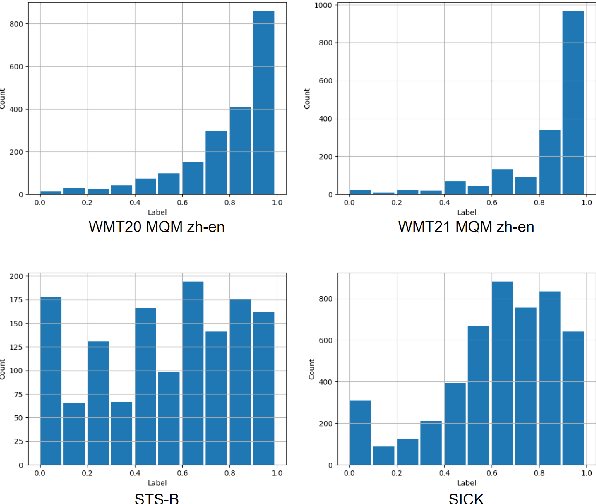
Automatic evaluation of text generation is essential for improving the accuracy of generation tasks. In light of the current trend towards increasingly larger decoder-based language models, we investigate automatic evaluation methods based on such models for text generation. This paper compares various methods, including tuning with encoder-based models and large language models under equal conditions, on two different tasks, machine translation evaluation and semantic textual similarity, in two languages, Japanese and English. Experimental results show that compared to the tuned encoder-based models, the tuned decoder-based models perform poorly. The analysis of the causes for this suggests that the decoder-based models focus on surface word sequences and do not capture meaning. It is also revealed that in-context learning of very large decoder-based models such as ChatGPT makes it difficult to identify fine-grained semantic differences.