 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSINet: Rotation-Scale Invariant Network for Online Visual Tracking
Nov 18, 2020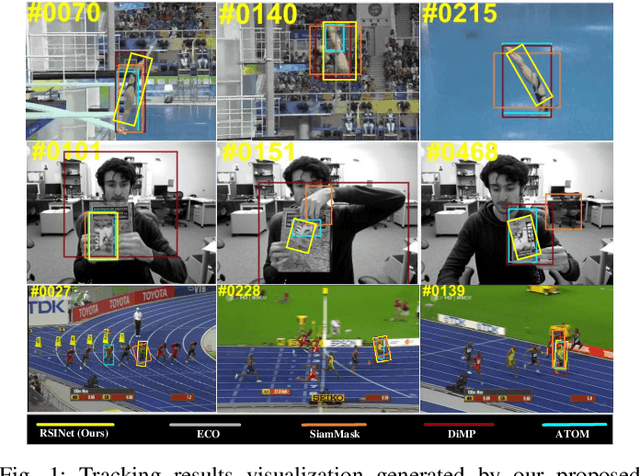
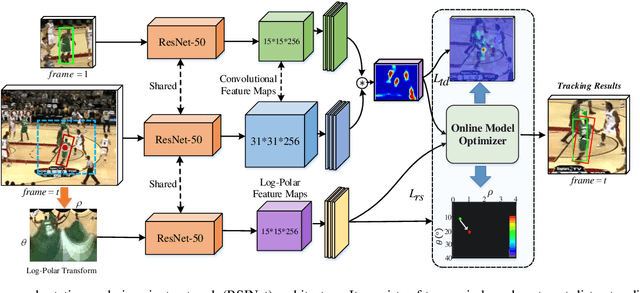
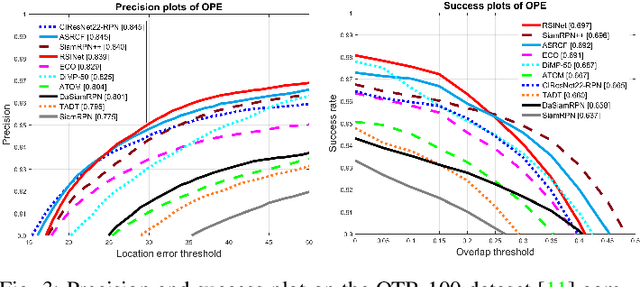
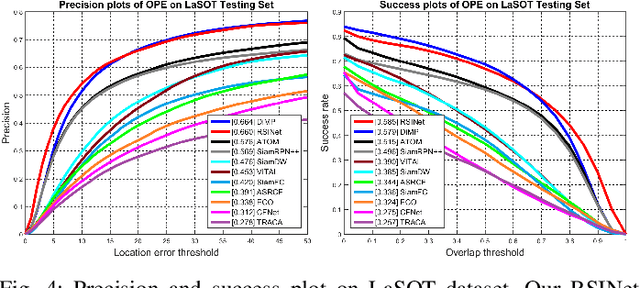
Most Siamese network-based trackers perform the tracking process without model update, and cannot learn targetspecific variation adaptively. Moreover, Siamese-based trackers infer the new state of tracked objects by generating axis-aligned bounding boxes, which contain extra background noise, and are unable to accurately estimate the rotation and scale transformation of moving objects, thus potentially reducing tracking performance. In this paper, we propose a novel Rotation-Scale Invariant Network (RSINet) to address the above problem. Our RSINet tracker consists of a target-distractor discrimination branch and a rotation-scale estimation branch, the rotation and scale knowledge can be explicitly learned by a multi-task learning method in an end-to-end manner. In addtion, the tracking model is adaptively optimized and updated under spatio-temporal energy control, which ensures model stability and reliability, as well as high tracking efficiency. Comprehensive experiments on OTB-100, VOT2018, and LaSOT benchmarks demonstrate that our proposed RSINet tracker yields new state-of-the-art performance compared with recent trackers, while running at real-time speed about 45 FPS.
Transfer Learning Based on AdaBoost for Feature Selection from Multiple ConvNet Layer Features
Mar 25, 2016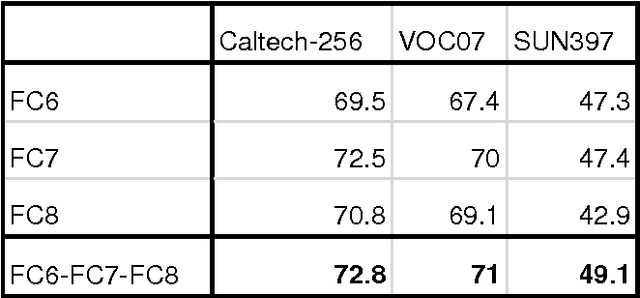
Convolutional Networks (ConvNets) are powerful models that learn hierarchies of visual features, which could also be used to obtain image representations for transfer learning. The basic pipeline for transfer learning is to first train a ConvNet on a large dataset (source task) and then use feed-forward units activation of the trained ConvNet as image representation for smaller datasets (target task). Our key contribution is to demonstrate superior performance of multiple ConvNet layer features over single ConvNet layer features. Combining multiple ConvNet layer features will result in more complex feature space with some features being repetitive. This requires some form of feature selection. We use AdaBoost with single stumps to implicitly select only distinct features that are useful towards classification from concatenated ConvNet features. Experimental results show that using multiple ConvNet layer activation features instead of single ConvNet layer features consistently will produce superior performance. Improvements becomes significant as we increase the distance between source task and the target task.