 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Water Quality using Quantum Machine Learning: The Case of the Umgeni Catchment (U20A) Study Region
Nov 27, 2024In this study, we consider a real-world application of QML techniques to study water quality in the U20A region in Durban, South Africa. Specifically, we applied the quantum support vector classifier (QSVC) and quantum neural network (QNN), and we showed that the QSVC is easier to implement and yields a higher accuracy. The QSVC models were applied for three kernels: Linear, polynomial, and radial basis function (RBF), and it was shown that the polynomial and RBF kernels had exactly the same performance. The QNN model was applied using different optimizers, learning rates, noise on the circuit components, and weight initializations were considered, but the QNN persistently ran into the dead neuron problem. Thus, the QNN was compared only by accraucy and loss, and it was shown that with the Adam optimizer, the model has the best performance, however, still less than the QSVC.
Integrative Approaches in Cybersecurity and AI
Aug 12, 2024In recent years, the convergence of cybersecurity, artificial intelligence (AI), and data management has emerged as a critical area of research, driven by the increasing complexity and interdependence of modern technological ecosystems. This paper provides a comprehensive review and analysis of integrative approaches that harness AI techniques to enhance cybersecurity frameworks and optimize data management practices. By exploring the synergies between these domains, we identify key trends, challenges, and future directions that hold the potential to revolutionize the way organizations protect, analyze, and leverage their data. Our findings highlight the necessity of cross-disciplinary strategies that incorporate AI-driven automation, real-time threat detection, and advanced data analytics to build more resilient and adaptive security architectures.
Does Synthetic Data Make Large Language Models More Efficient?
Oct 11, 2023Natural Language Processing (NLP) has undergone transformative changes with the advent of deep learning methodologies. One challenge persistently confronting researchers is the scarcity of high-quality, annotated datasets that drive these models. This paper explores the nuances of synthetic data generation in NLP, with a focal point on template-based question generation. By assessing its advantages, including data augmentation potential and the introduction of structured variety, we juxtapose these benefits against inherent limitations, such as the risk of overfitting and the constraints posed by pre-defined templates. Drawing from empirical evaluations, we demonstrate the impact of template-based synthetic data on the performance of modern transformer models. We conclude by emphasizing the delicate balance required between synthetic and real-world data, and the future trajectories of integrating synthetic data in model training pipelines. The findings aim to guide NLP practitioners in harnessing synthetic data's potential, ensuring optimal model performance in diverse applications.
Can pruning make Large Language Models more efficient?
Oct 06, 2023Transformer models have revolutionized natural language processing with their unparalleled ability to grasp complex contextual relationships. However, the vast number of parameters in these models has raised concerns regarding computational efficiency, environmental impact, and deployability on resource-limited platforms. To address these challenges, this paper investigates the application of weight pruning-a strategic reduction of model parameters based on their significance-as an optimization strategy for Transformer architectures. Through extensive experimentation, we explore various pruning methodologies, highlighting their impact on model performance, size, and computational demands. Our findings suggest that with judicious selection of pruning hyperparameters, significant reductions in model size are attainable without considerable compromise on performance. Moreover, when coupled with post-pruning fine-tuning strategies, some pruned models even exhibit enhanced generalization capabilities. This work seeks to bridge the gap between model efficiency and performance, paving the way for more scalable and environmentally responsible deep learning applications.
Can a student Large Language Model perform as well as it's teacher?
Oct 03, 2023The burgeoning complexity of contemporary deep learning models, while achieving unparalleled accuracy, has inadvertently introduced deployment challenges in resource-constrained environments. Knowledge distillation, a technique aiming to transfer knowledge from a high-capacity "teacher" model to a streamlined "student" model, emerges as a promising solution to this dilemma. This paper provides a comprehensive overview of the knowledge distillation paradigm, emphasizing its foundational principles such as the utility of soft labels and the significance of temperature scaling. Through meticulous examination, we elucidate the critical determinants of successful distillation, including the architecture of the student model, the caliber of the teacher, and the delicate balance of hyperparameters. While acknowledging its profound advantages, we also delve into the complexities and challenges inherent in the process. Our exploration underscores knowledge distillation's potential as a pivotal technique in optimizing the trade-off between model performance and deployment efficiency.
Do Generative Large Language Models need billions of parameters?
Sep 12, 2023This paper presents novel systems and methodologies for the development of efficient large language models (LLMs). It explores the trade-offs between model size, performance, and computational resources, with the aim of maximizing the efficiency of these AI systems. The research explores novel methods that allow different parts of the model to share parameters, reducing the total number of unique parameters required. This approach ensures that the model remains compact without sacrificing its ability to learn and represent complex language structures. This study provides valuable insights and tools for creating more efficient and effective LLMs, contributing to a more sustainable and accessible future for AI language modeling.
Harnessing the Power of Decision Trees to Detect IoT Malware
Jan 28, 2023


Due to its simple installation and connectivity, the Internet of Things (IoT) is susceptible to malware attacks. Being able to operate autonomously. As IoT devices have become more prevalent, they have become the most tempting targets for malware. Weak, guessable, or hard-coded passwords, and a lack of security measures contribute to these vulnerabilities along with insecure network connections and outdated update procedures. To understand IoT malware, current methods and analysis ,using static methods, are ineffective. The field of deep learning has made great strides in recent years due to their tremendous data mining, learning, and expression capabilities, cybersecurity has enjoyed tremendous growth in recent years. As a result, malware analysts will not have to spend as much time analyzing malware. In this paper, we propose a novel detection and analysis method that harnesses the power and simplicity of decision trees. The experiments are conducted using a real word dataset, MaleVis which is a publicly available dataset. Based on the results, we show that our proposed approach outperforms existing state-of-the-art solutions in that it achieves 97.23% precision and 95.89% recall in terms of detection and classification. A specificity of 96.58%, F1-score of 96.40%, an accuracy of 96.43.
New Approach to Malware Detection Using Optimized Convolutional Neural Network
Jan 26, 2023



Cyber-crimes have become a multi-billion-dollar industry in the recent years. Most cybercrimes/attacks involve deploying some type of malware. Malware that viciously targets every industry, every sector, every enterprise and even individuals has shown its capabilities to take entire business organizations offline and cause significant financial damage in billions of dollars annually. Malware authors are constantly evolving in their attack strategies and sophistication and are developing malware that is difficult to detect and can lay dormant in the background for quite some time in order to evade security controls. Given the above argument, Traditional approaches to malware detection are no longer effective. As a result, deep learning models have become an emerging trend to detect and classify malware. This paper proposes a new convolutional deep learning neural network to accurately and effectively detect malware with high precision. This paper is different than most other papers in the literature in that it uses an expert data science approach by developing a convolutional neural network from scratch to establish a baseline of the performance model first, explores and implements an improvement model from the baseline model, and finally it evaluates the performance of the final model. The baseline model initially achieves 98% accurate rate but after increasing the depth of the CNN model, its accuracy reaches 99.183 which outperforms most of the CNN models in the literature. Finally, to further solidify the effectiveness of this CNN model, we use the improved model to make predictions on new malware samples within our dataset.
Robust Natural Language Processing: Recent Advances, Challenges, and Future Directions
Jan 03, 2022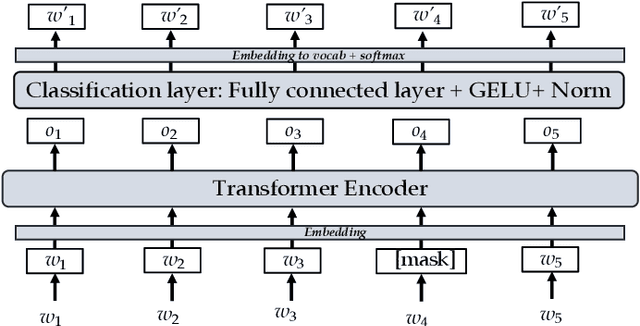
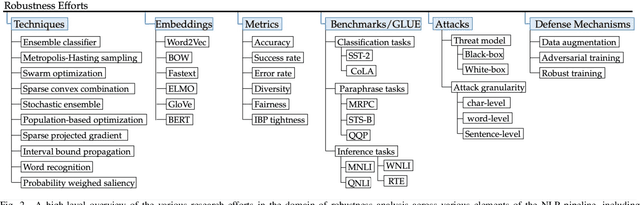
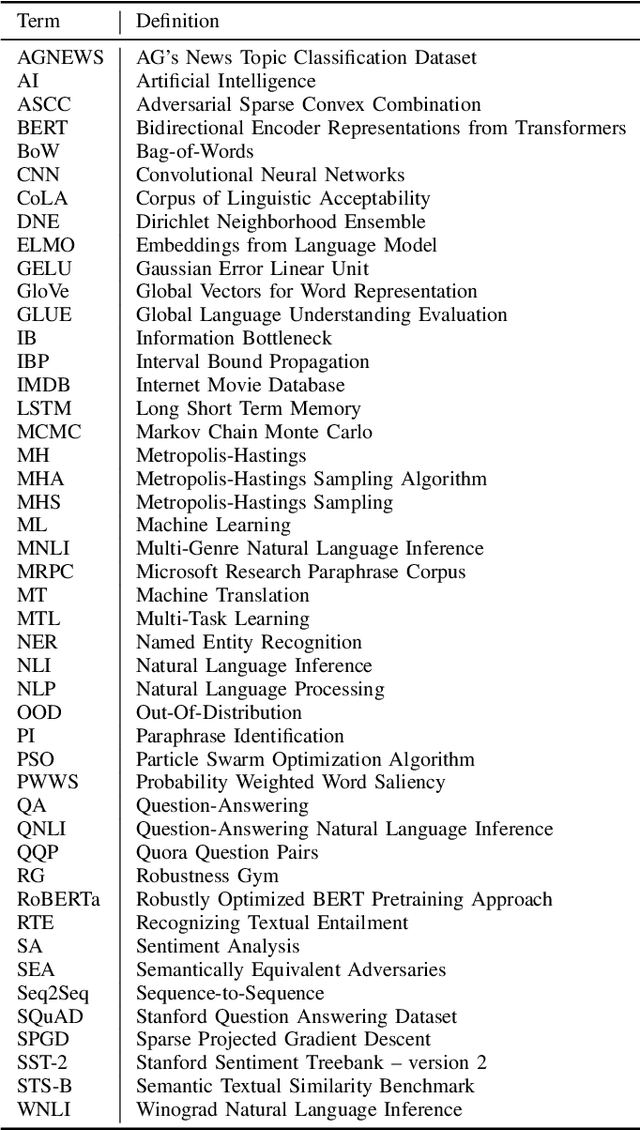
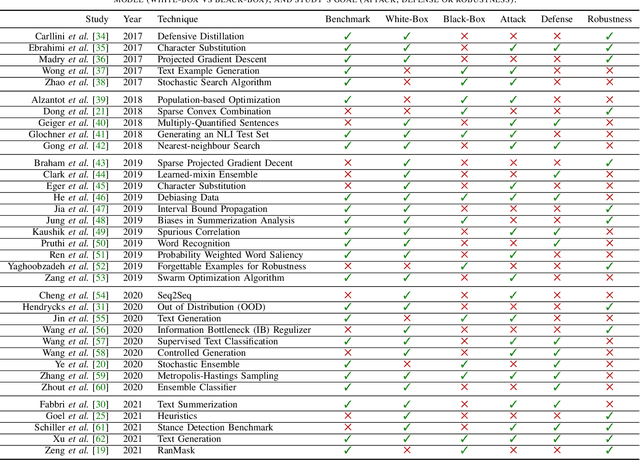
Recent natural language processing (NLP) techniques have accomplished high performance on benchmark datasets, primarily due to the significant improvement in the performance of deep learning. The advances in the research community have led to great enhancements in state-of-the-art production systems for NLP tasks, such as virtual assistants, speech recognition, and sentiment analysis. However, such NLP systems still often fail when tested with adversarial attacks. The initial lack of robustness exposed troubling gaps in current models' language understanding capabilities, creating problems when NLP systems are deployed in real life. In this paper, we present a structured overview of NLP robustness research by summarizing the literature in a systemic way across various dimensions. We then take a deep-dive into the various dimensions of robustness, across techniques, metrics, embeddings, and benchmarks. Finally, we argue that robustness should be multi-dimensional, provide insights into current research, identify gaps in the literature to suggest directions worth pursuing to address these gaps.