 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes Synthetic Data Make Large Language Models More Efficient?
Oct 11, 2023Natural Language Processing (NLP) has undergone transformative changes with the advent of deep learning methodologies. One challenge persistently confronting researchers is the scarcity of high-quality, annotated datasets that drive these models. This paper explores the nuances of synthetic data generation in NLP, with a focal point on template-based question generation. By assessing its advantages, including data augmentation potential and the introduction of structured variety, we juxtapose these benefits against inherent limitations, such as the risk of overfitting and the constraints posed by pre-defined templates. Drawing from empirical evaluations, we demonstrate the impact of template-based synthetic data on the performance of modern transformer models. We conclude by emphasizing the delicate balance required between synthetic and real-world data, and the future trajectories of integrating synthetic data in model training pipelines. The findings aim to guide NLP practitioners in harnessing synthetic data's potential, ensuring optimal model performance in diverse applications.
Can pruning make Large Language Models more efficient?
Oct 06, 2023Transformer models have revolutionized natural language processing with their unparalleled ability to grasp complex contextual relationships. However, the vast number of parameters in these models has raised concerns regarding computational efficiency, environmental impact, and deployability on resource-limited platforms. To address these challenges, this paper investigates the application of weight pruning-a strategic reduction of model parameters based on their significance-as an optimization strategy for Transformer architectures. Through extensive experimentation, we explore various pruning methodologies, highlighting their impact on model performance, size, and computational demands. Our findings suggest that with judicious selection of pruning hyperparameters, significant reductions in model size are attainable without considerable compromise on performance. Moreover, when coupled with post-pruning fine-tuning strategies, some pruned models even exhibit enhanced generalization capabilities. This work seeks to bridge the gap between model efficiency and performance, paving the way for more scalable and environmentally responsible deep learning applications.
Can a student Large Language Model perform as well as it's teacher?
Oct 03, 2023The burgeoning complexity of contemporary deep learning models, while achieving unparalleled accuracy, has inadvertently introduced deployment challenges in resource-constrained environments. Knowledge distillation, a technique aiming to transfer knowledge from a high-capacity "teacher" model to a streamlined "student" model, emerges as a promising solution to this dilemma. This paper provides a comprehensive overview of the knowledge distillation paradigm, emphasizing its foundational principles such as the utility of soft labels and the significance of temperature scaling. Through meticulous examination, we elucidate the critical determinants of successful distillation, including the architecture of the student model, the caliber of the teacher, and the delicate balance of hyperparameters. While acknowledging its profound advantages, we also delve into the complexities and challenges inherent in the process. Our exploration underscores knowledge distillation's potential as a pivotal technique in optimizing the trade-off between model performance and deployment efficiency.
Do Generative Large Language Models need billions of parameters?
Sep 12, 2023This paper presents novel systems and methodologies for the development of efficient large language models (LLMs). It explores the trade-offs between model size, performance, and computational resources, with the aim of maximizing the efficiency of these AI systems. The research explores novel methods that allow different parts of the model to share parameters, reducing the total number of unique parameters required. This approach ensures that the model remains compact without sacrificing its ability to learn and represent complex language structures. This study provides valuable insights and tools for creating more efficient and effective LLMs, contributing to a more sustainable and accessible future for AI language modeling.
Framework for 2D Ad placements in LinearTV
Dec 05, 2022



Virtual Product placement(VPP) is the advertising technique of digitally placing a branded object into the scene of a movie or TV show. This type of advertising provides the ability for brands to reach consumers without interrupting the viewing experience with a commercial break, as the products are seen in the background or as props. Despite this being a billion-dollar industry, ad rendering technique is currently executed at post production stage, manually either with the help of VFx artists or through semi-automated solutions. In this paper, we demonstrate a fully automated framework to digitally place 2-D ads in linear TV cooking shows captured using single-view camera with small camera movements. Without access to full video or production camera configuration, this framework performs the following tasks (i) identifying empty space for 2-D ad placement (ii) kitchen scene understanding (iii) occlusion handling (iv) ambient lighting and (v) ad tracking.
Alexa, Predict My Flight Delay
Aug 21, 2022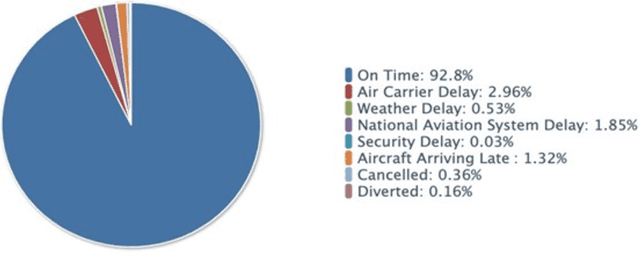
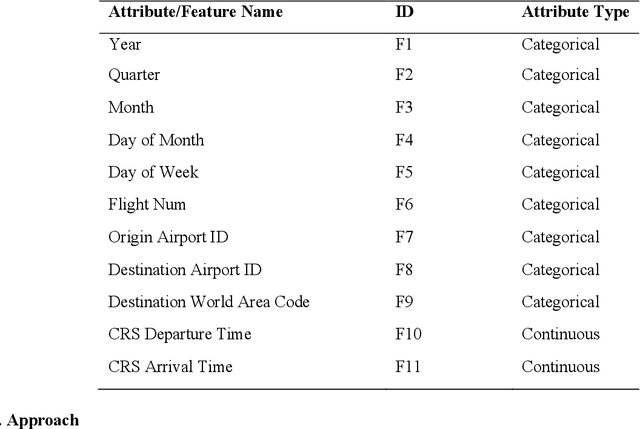

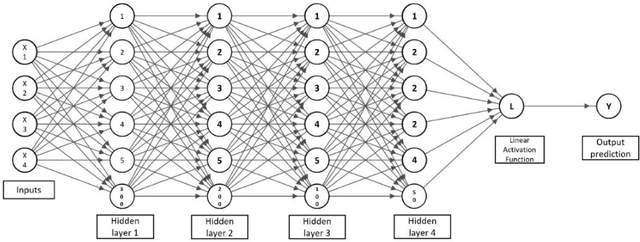
Airlines are critical today for carrying people and commodities on time. Any delay in the schedule of these planes can potentially disrupt the business and trade of thousands of employees at any given time. Therefore, precise flight delay prediction is beneficial for the aviation industry and passenger travel. Recent research has focused on using artificial intelligence algorithms to predict the possibility of flight delays. Earlier prediction algorithms were designed for a specific air route or airfield. Many present flight delay prediction algorithms rely on tiny samples and are challenging to understand, allowing almost no room for machine learning implementation. This research study develops a flight delay prediction system by analyzing data from domestic flights inside the United States of America. The proposed models learn about the factors that cause flight delays and cancellations and the link between departure and arrival delays.
Knock, knock. Who's there? -- Identifying football player jersey numbers with synthetic data
Apr 04, 2022


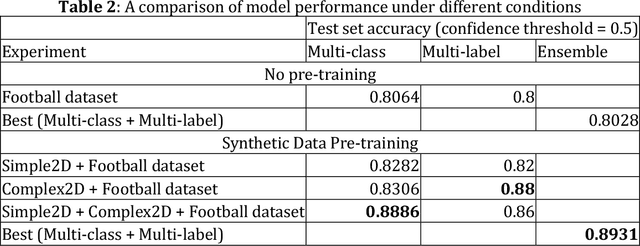
Automatic player identification is an essential and complex task in sports video analysis. Different strategies have been devised over the years, but identification based on jersey numbers is one of the most common approaches given its versatility and relative simplicity. However, automatic detection of jersey numbers is still challenging due to changing camera angles, low video resolution, small object size in wide-range shots and transient changes in the player's posture and movement. In this paper we present a novel approach for jersey number identification in a small, highly imbalanced dataset from the Seattle Seahawks practice videos. Our results indicate that simple models can achieve an acceptable performance on the jersey number detection task and that synthetic data can improve the performance dramatically (accuracy increase of ~9% overall, ~18% on low frequency numbers) making our approach achieve state of the art results.
Zero-Shot Open-Book Question Answering
Nov 22, 2021



Open book question answering is a subset of question answering tasks where the system aims to find answers in a given set of documents (open-book) and common knowledge about a topic. This article proposes a solution for answering natural language questions from a corpus of Amazon Web Services (AWS) technical documents with no domain-specific labeled data (zero-shot). These questions can have yes-no-none answers, short answers, long answers, or any combination of the above. This solution comprises a two-step architecture in which a retriever finds the right document and an extractor finds the answers in the retrieved document. We are introducing a new test dataset for open-book QA based on real customer questions on AWS technical documentation. After experimenting with several information retrieval systems and extractor models based on extractive language models, the solution attempts to find the yes-no-none answers and text answers in the same pass. The model is trained on the The Stanford Question Answering Dataset - SQuAD (Rajpurkaret al., 2016) and Natural Questions (Kwiatkowski et al., 2019) datasets. We were able to achieve 49% F1 and 39% exact match score (EM) end-to-end with no domain-specific training.