 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Graph Transformer for Deepfake Detection
Jul 27, 2023Deepfake detection methods have shown promising results in recognizing forgeries within a given dataset, where training and testing take place on the in-distribution dataset. However, their performance deteriorates significantly when presented with unseen samples. As a result, a reliable deepfake detection system must remain impartial to forgery types, appearance, and quality for guaranteed generalizable detection performance. Despite various attempts to enhance cross-dataset generalization, the problem remains challenging, particularly when testing against common post-processing perturbations, such as video compression or blur. Hence, this study introduces a deepfake detection framework, leveraging a self-supervised pre-training model that delivers exceptional generalization ability, withstanding common corruptions and enabling feature explainability. The framework comprises three key components: a feature extractor based on vision Transformer architecture that is pre-trained via self-supervised contrastive learning methodology, a graph convolution network coupled with a Transformer discriminator, and a graph Transformer relevancy map that provides a better understanding of manipulated regions and further explains the model's decision. To assess the effectiveness of the proposed framework, several challenging experiments are conducted, including in-data distribution performance, cross-dataset, cross-manipulation generalization, and robustness against common post-production perturbations. The results achieved demonstrate the remarkable effectiveness of the proposed deepfake detection framework, surpassing the current state-of-the-art approaches.
Deep Biological Pathway Informed Pathology-Genomic Multimodal Survival Prediction
Jan 06, 2023The integration of multi-modal data, such as pathological images and genomic data, is essential for understanding cancer heterogeneity and complexity for personalized treatments, as well as for enhancing survival predictions. Despite the progress made in integrating pathology and genomic data, most existing methods cannot mine the complex inter-modality relations thoroughly. Additionally, identifying explainable features from these models that govern preclinical discovery and clinical prediction is crucial for cancer diagnosis, prognosis, and therapeutic response studies. We propose PONET- a novel biological pathway-informed pathology-genomic deep model that integrates pathological images and genomic data not only to improve survival prediction but also to identify genes and pathways that cause different survival rates in patients. Empirical results on six of The Cancer Genome Atlas (TCGA) datasets show that our proposed method achieves superior predictive performance and reveals meaningful biological interpretations. The proposed method establishes insight into how to train biologically informed deep networks on multimodal biomedical data which will have general applicability for understanding diseases and predicting response and resistance to treatment.
Generating Adversarial Examples with an Optimized Quality
Jun 30, 2020
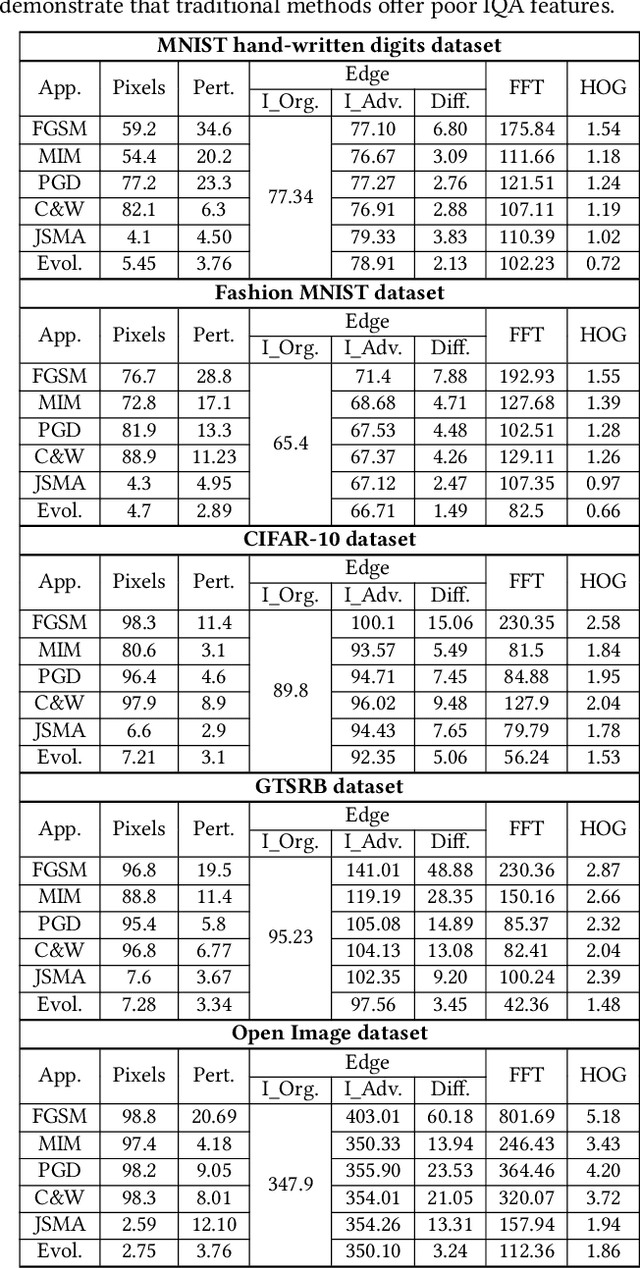
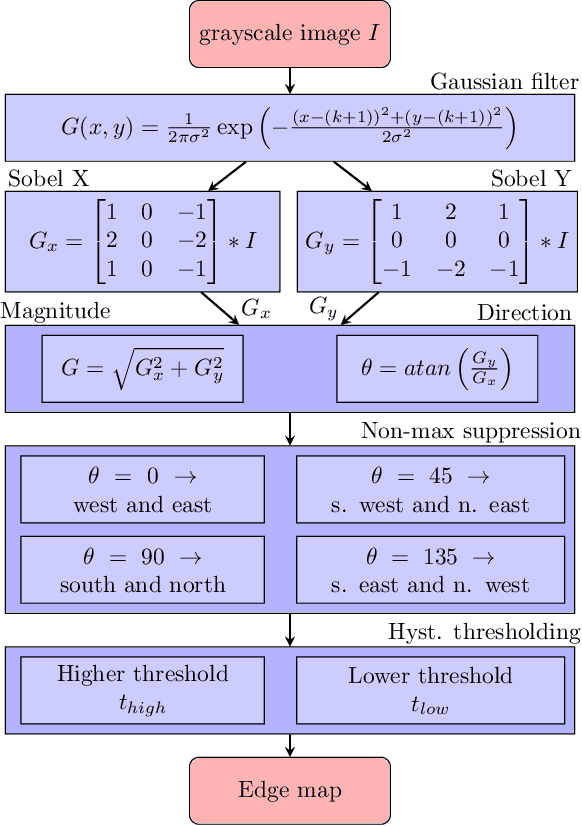
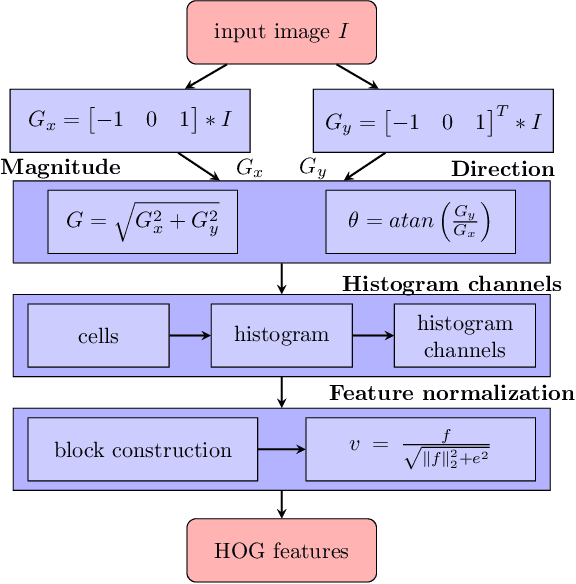
Deep learning models are widely used in a range of application areas, such as computer vision, computer security, etc. However, deep learning models are vulnerable to Adversarial Examples (AEs),carefully crafted samples to deceive those models. Recent studies have introduced new adversarial attack methods, but, to the best of our knowledge, none provided guaranteed quality for the crafted examples as part of their creation, beyond simple quality measures such as Misclassification Rate (MR). In this paper, we incorporateImage Quality Assessment (IQA) metrics into the design and generation process of AEs. We propose an evolutionary-based single- and multi-objective optimization approaches that generate AEs with high misclassification rate and explicitly improve the quality, thus indistinguishability, of the samples, while perturbing only a limited number of pixels. In particular, several IQA metrics, including edge analysis, Fourier analysis, and feature descriptors, are leveraged into the process of generating AEs. Unique characteristics of the evolutionary-based algorithm enable us to simultaneously optimize the misclassification rate and the IQA metrics of the AEs. In order to evaluate the performance of the proposed method, we conduct intensive experiments on different well-known benchmark datasets(MNIST, CIFAR, GTSRB, and Open Image Dataset V5), while considering various objective optimization configurations. The results obtained from our experiments, when compared with the exist-ing attack methods, validate our initial hypothesis that the use ofIQA metrics within generation process of AEs can substantially improve their quality, while maintaining high misclassification rate.Finally, transferability and human perception studies are provided, demonstrating acceptable performance.
COPYCAT: Practical Adversarial Attacks on Visualization-Based Malware Detection
Sep 20, 2019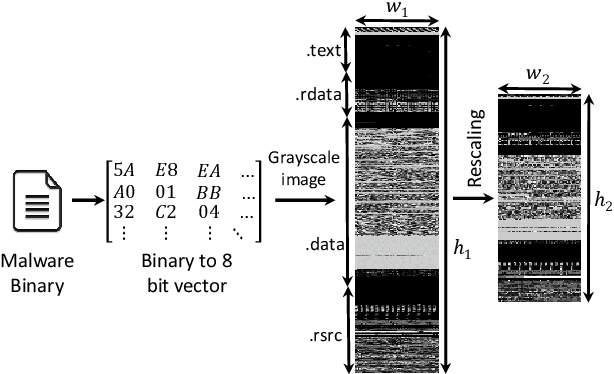


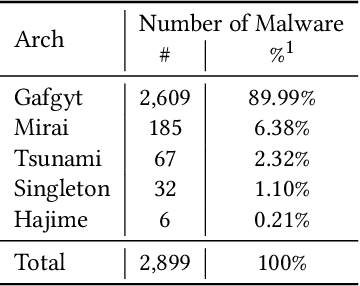
Despite many attempts, the state-of-the-art of adversarial machine learning on malware detection systems generally yield unexecutable samples. In this work, we set out to examine the robustness of visualization-based malware detection system against adversarial examples (AEs) that not only are able to fool the model, but also maintain the executability of the original input. As such, we first investigate the application of existing off-the-shelf adversarial attack approaches on malware detection systems through which we found that those approaches do not necessarily maintain the functionality of the original inputs. Therefore, we proposed an approach to generate adversarial examples, COPYCAT, which is specifically designed for malware detection systems considering two main goals; achieving a high misclassification rate and maintaining the executability and functionality of the original input. We designed two main configurations for COPYCAT, namely AE padding and sample injection. While the first configuration results in untargeted misclassification attacks, the sample injection configuration is able to force the model to generate a targeted output, which is highly desirable in the malware attribution setting. We evaluate the performance of COPYCAT through an extensive set of experiments on two malware datasets, and report that we were able to generate adversarial samples that are misclassified at a rate of 98.9% and 96.5% with Windows and IoT binary datasets, respectively, outperforming the misclassification rates in the literature. Most importantly, we report that those AEs were executable unlike AEs generated by off-the-shelf approaches. Our transferability study demonstrates that the generated AEs through our proposed method can be generalized to other models.
Examining Adversarial Learning against Graph-based IoT Malware Detection Systems
Feb 15, 2019
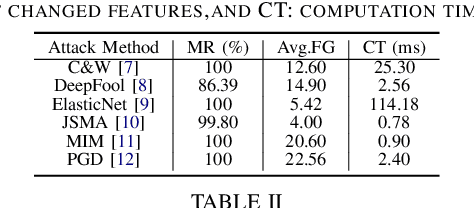

The main goal of this study is to investigate the robustness of graph-based Deep Learning (DL) models used for Internet of Things (IoT) malware classification against Adversarial Learning (AL). We designed two approaches to craft adversarial IoT software, including Off-the-Shelf Adversarial Attack (OSAA) methods, using six different AL attack approaches, and Graph Embedding and Augmentation (GEA). The GEA approach aims to preserve the functionality and practicality of the generated adversarial sample through a careful embedding of a benign sample to a malicious one. Our evaluations demonstrate that OSAAs are able to achieve a misclassification rate (MR) of 100%. Moreover, we observed that the GEA approach is able to misclassify all IoT malware samples as benign.