 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCatch-Up Mix: Catch-Up Class for Struggling Filters in CNN
Jan 24, 2024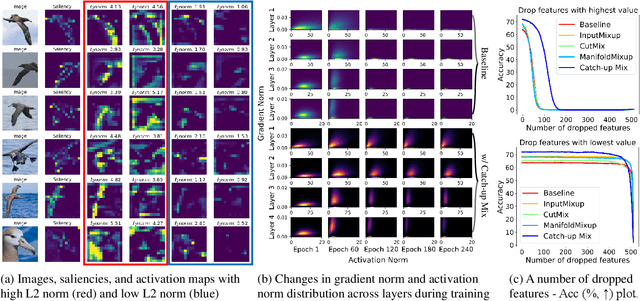
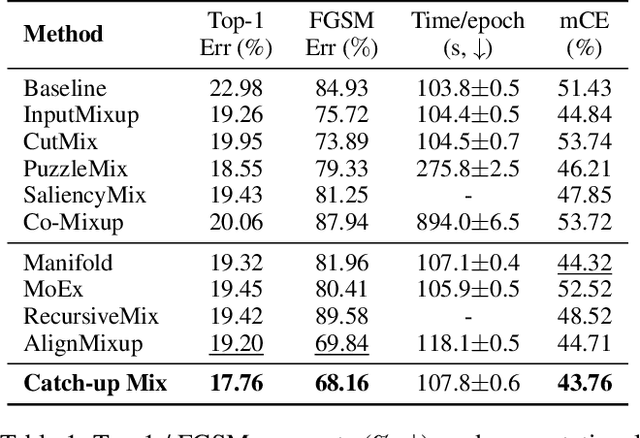
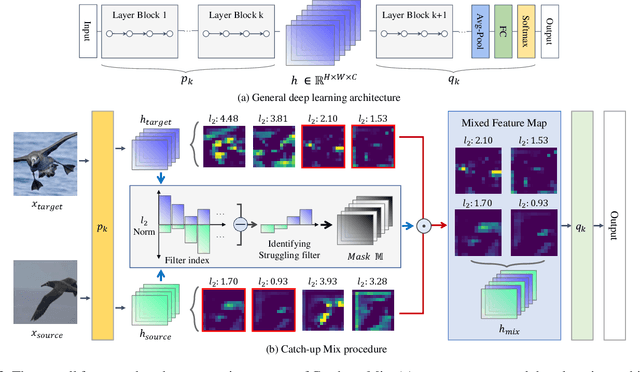
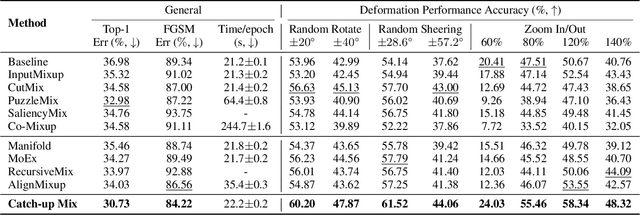
Deep learning has made significant advances in computer vision, particularly in image classification tasks. Despite their high accuracy on training data, deep learning models often face challenges related to complexity and overfitting. One notable concern is that the model often relies heavily on a limited subset of filters for making predictions. This dependency can result in compromised generalization and an increased vulnerability to minor variations. While regularization techniques like weight decay, dropout, and data augmentation are commonly used to address this issue, they may not directly tackle the reliance on specific filters. Our observations reveal that the heavy reliance problem gets severe when slow-learning filters are deprived of learning opportunities due to fast-learning filters. Drawing inspiration from image augmentation research that combats over-reliance on specific image regions by removing and replacing parts of images, our idea is to mitigate the problem of over-reliance on strong filters by substituting highly activated features. To this end, we present a novel method called Catch-up Mix, which provides learning opportunities to a wide range of filters during training, focusing on filters that may lag behind. By mixing activation maps with relatively lower norms, Catch-up Mix promotes the development of more diverse representations and reduces reliance on a small subset of filters. Experimental results demonstrate the superiority of our method in various vision classification datasets, providing enhanced robustness.