 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Hybrid Lightweight Representations Learning: Its Application to Visual Tracking
Paper and Code
May 23, 2022
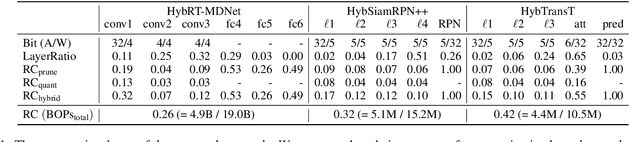
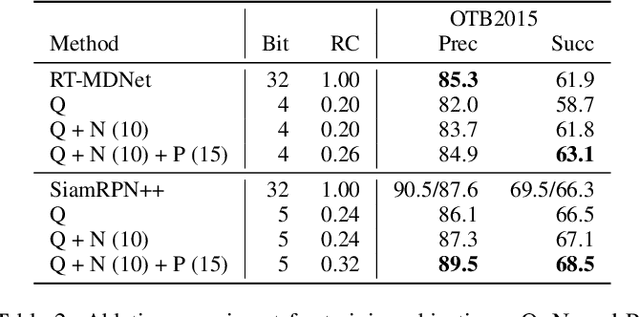
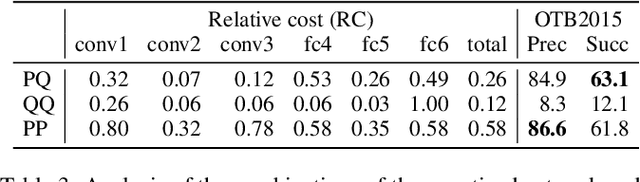
This paper presents a novel hybrid representation learning framework for streaming data, where an image frame in a video is modeled by an ensemble of two distinct deep neural networks; one is a low-bit quantized network and the other is a lightweight full-precision network. The former learns coarse primary information with low cost while the latter conveys residual information for high fidelity to original representations. The proposed parallel architecture is effective to maintain complementary information since fixed-point arithmetic can be utilized in the quantized network and the lightweight model provides precise representations given by a compact channel-pruned network. We incorporate the hybrid representation technique into an online visual tracking task, where deep neural networks need to handle temporal variations of target appearances in real-time. Compared to the state-of-the-art real-time trackers based on conventional deep neural networks, our tracking algorithm demonstrates competitive accuracy on the standard benchmarks with a small fraction of computational cost and memory footprint.