 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinority-Oriented Vicinity Expansion with Attentive Aggregation for Video Long-Tailed Recognition
Paper and Code


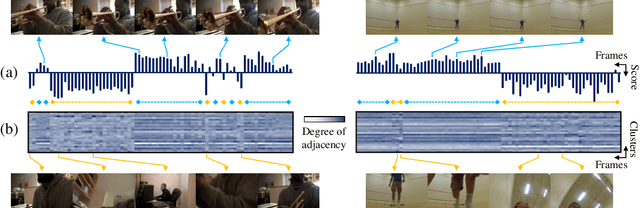
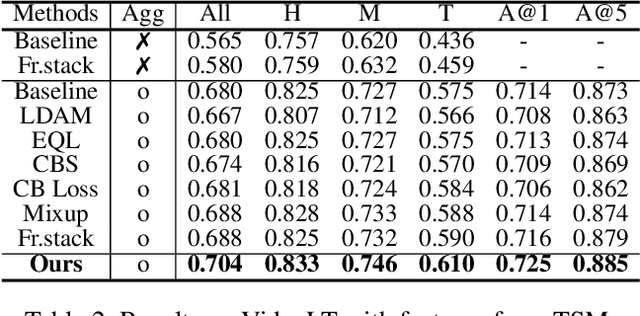
A dramatic increase in real-world video volume with extremely diverse and emerging topics naturally forms a long-tailed video distribution in terms of their categories, and it spotlights the need for Video Long-Tailed Recognition (VLTR). In this work, we summarize the challenges in VLTR and explore how to overcome them. The challenges are: (1) it is impractical to re-train the whole model for high-quality features, (2) acquiring frame-wise labels requires extensive cost, and (3) long-tailed data triggers biased training. Yet, most existing works for VLTR unavoidably utilize image-level features extracted from pretrained models which are task-irrelevant, and learn by video-level labels. Therefore, to deal with such (1) task-irrelevant features and (2) video-level labels, we introduce two complementary learnable feature aggregators. Learnable layers in each aggregator are to produce task-relevant representations, and each aggregator is to assemble the snippet-wise knowledge into a video representative. Then, we propose Minority-Oriented Vicinity Expansion (MOVE) that explicitly leverages the class frequency into approximating the vicinity distributions to alleviate (3) biased training. By combining these solutions, our approach achieves state-of-the-art results on large-scale VideoLT and synthetically induced Imbalanced-MiniKinetics200. With VideoLT features from ResNet-50, it attains 18% and 58% relative improvements on head and tail classes over the previous state-of-the-art method, respectively.