 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNext-Scale Autoregressive Models for Text-to-Motion Generation
Apr 04, 2026Autoregressive (AR) models offer stable and efficient training, but standard next-token prediction is not well aligned with the temporal structure required for text-conditioned motion generation. We introduce MoScale, a next-scale AR framework that generates motion hierarchically from coarse to fine temporal resolutions. By providing global semantics at the coarsest scale and refining them progressively, MoScale establishes a causal hierarchy better suited for long-range motion structure. To improve robustness under limited text-motion data, we further incorporate cross-scale hierarchical refinement for improving per-scale initial predictions and in-scale temporal refinement for selective bidirectional re-prediction. MoScale achieves SOTA text-to-motion performance with high training efficiency, scales effectively with model size, and generalizes zero-shot to diverse motion generation and editing tasks.
Building Audio-Visual Digital Twins with Smartphones
Dec 11, 2025Digital twins today are almost entirely visual, overlooking acoustics-a core component of spatial realism and interaction. We introduce AV-Twin, the first practical system that constructs editable audio-visual digital twins using only commodity smartphones. AV-Twin combines mobile RIR capture and a visual-assisted acoustic field model to efficiently reconstruct room acoustics. It further recovers per-surface material properties through differentiable acoustic rendering, enabling users to modify materials, geometry, and layout while automatically updating both audio and visuals. Together, these capabilities establish a practical path toward fully modifiable audio-visual digital twins for real-world environments.
Resounding Acoustic Fields with Reciprocity
Oct 23, 2025Achieving immersive auditory experiences in virtual environments requires flexible sound modeling that supports dynamic source positions. In this paper, we introduce a task called resounding, which aims to estimate room impulse responses at arbitrary emitter location from a sparse set of measured emitter positions, analogous to the relighting problem in vision. We leverage the reciprocity property and introduce Versa, a physics-inspired approach to facilitating acoustic field learning. Our method creates physically valid samples with dense virtual emitter positions by exchanging emitter and listener poses. We also identify challenges in deploying reciprocity due to emitter/listener gain patterns and propose a self-supervised learning approach to address them. Results show that Versa substantially improve the performance of acoustic field learning on both simulated and real-world datasets across different metrics. Perceptual user studies show that Versa can greatly improve the immersive spatial sound experience. Code, dataset and demo videos are available on the project website: https://waves.seas.upenn.edu/projects/versa.
Quantifying Itch and its Impact on Sleep Using Machine Learning and Radio Signals
Jan 09, 2025



Chronic itch affects 13% of the US population, is highly debilitating, and underlies many medical conditions. A major challenge in clinical care and new therapeutics development is the lack of an objective measure for quantifying itch, leading to reliance on subjective measures like patients' self-assessment of itch severity. In this paper, we show that a home radio device paired with artificial intelligence (AI) can concurrently capture scratching and evaluate its impact on sleep quality by analyzing radio signals bouncing in the environment. The device eliminates the need for wearable sensors or skin contact, enabling monitoring of chronic itch over extended periods at home without burdening patients or interfering with their skin condition. To validate the technology, we conducted an observational clinical study of chronic pruritus patients, monitored at home for one month using both the radio device and an infrared camera. Comparing the output of the device to ground truth data from the camera demonstrates its feasibility and accuracy (ROC AUC = 0.997, sensitivity = 0.825, specificity = 0.997). The results reveal a significant correlation between scratching and low sleep quality, manifested as a reduction in sleep efficiency (R = 0.6, p < 0.001) and an increase in sleep latency (R = 0.68, p < 0.001). Our study underscores the potential of passive, long-term, at-home monitoring of chronic scratching and its sleep implications, offering a valuable tool for both clinical care of chronic itch patients and pharmaceutical clinical trials.
Acoustic Volume Rendering for Neural Impulse Response Fields
Nov 09, 2024



Realistic audio synthesis that captures accurate acoustic phenomena is essential for creating immersive experiences in virtual and augmented reality. Synthesizing the sound received at any position relies on the estimation of impulse response (IR), which characterizes how sound propagates in one scene along different paths before arriving at the listener's position. In this paper, we present Acoustic Volume Rendering (AVR), a novel approach that adapts volume rendering techniques to model acoustic impulse responses. While volume rendering has been successful in modeling radiance fields for images and neural scene representations, IRs present unique challenges as time-series signals. To address these challenges, we introduce frequency-domain volume rendering and use spherical integration to fit the IR measurements. Our method constructs an impulse response field that inherently encodes wave propagation principles and achieves state-of-the-art performance in synthesizing impulse responses for novel poses. Experiments show that AVR surpasses current leading methods by a substantial margin. Additionally, we develop an acoustic simulation platform, AcoustiX, which provides more accurate and realistic IR simulations than existing simulators. Code for AVR and AcoustiX are available at https://zitonglan.github.io/avr.
Enabling Visual Recognition at Radio Frequency
May 29, 2024



This paper introduces PanoRadar, a novel RF imaging system that brings RF resolution close to that of LiDAR, while providing resilience against conditions challenging for optical signals. Our LiDAR-comparable 3D imaging results enable, for the first time, a variety of visual recognition tasks at radio frequency, including surface normal estimation, semantic segmentation, and object detection. PanoRadar utilizes a rotating single-chip mmWave radar, along with a combination of novel signal processing and machine learning algorithms, to create high-resolution 3D images of the surroundings. Our system accurately estimates robot motion, allowing for coherent imaging through a dense grid of synthetic antennas. It also exploits the high azimuth resolution to enhance elevation resolution using learning-based methods. Furthermore, PanoRadar tackles 3D learning via 2D convolutions and addresses challenges due to the unique characteristics of RF signals. Our results demonstrate PanoRadar's robust performance across 12 buildings.
Seeing Through Clouds in Satellite Images
Jun 15, 2021
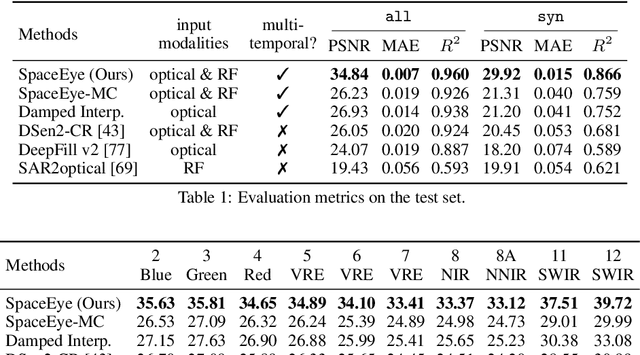


This paper presents a neural-network-based solution to recover pixels occluded by clouds in satellite images. We leverage radio frequency (RF) signals in the ultra/super-high frequency band that penetrate clouds to help reconstruct the occluded regions in multispectral images. We introduce the first multi-modal multi-temporal cloud removal model. Our model uses publicly available satellite observations and produces daily cloud-free images. Experimental results show that our system significantly outperforms baselines by 8dB in PSNR. We also demonstrate use cases of our system in digital agriculture, flood monitoring, and wildfire detection. We will release the processed dataset to facilitate future research.
Making the Invisible Visible: Action Recognition Through Walls and Occlusions
Sep 20, 2019
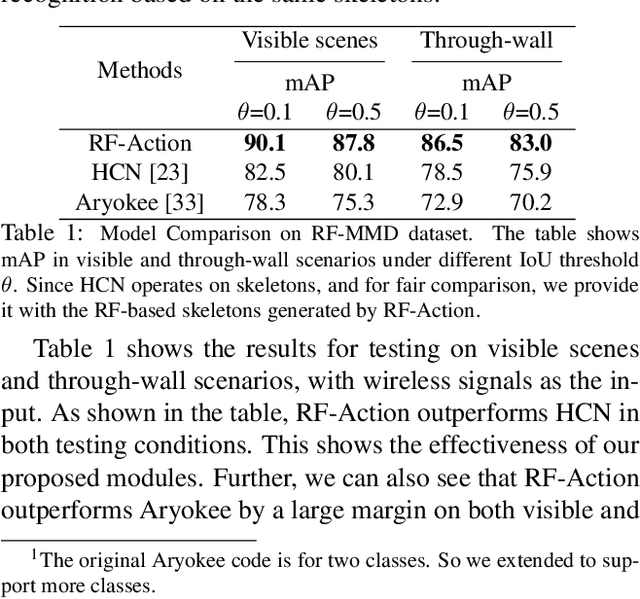


Understanding people's actions and interactions typically depends on seeing them. Automating the process of action recognition from visual data has been the topic of much research in the computer vision community. But what if it is too dark, or if the person is occluded or behind a wall? In this paper, we introduce a neural network model that can detect human actions through walls and occlusions, and in poor lighting conditions. Our model takes radio frequency (RF) signals as input, generates 3D human skeletons as an intermediate representation, and recognizes actions and interactions of multiple people over time. By translating the input to an intermediate skeleton-based representation, our model can learn from both vision-based and RF-based datasets, and allow the two tasks to help each other. We show that our model achieves comparable accuracy to vision-based action recognition systems in visible scenarios, yet continues to work accurately when people are not visible, hence addressing scenarios that are beyond the limit of today's vision-based action recognition.
Bidirectional Inference Networks: A Class of Deep Bayesian Networks for Health Profiling
Feb 06, 2019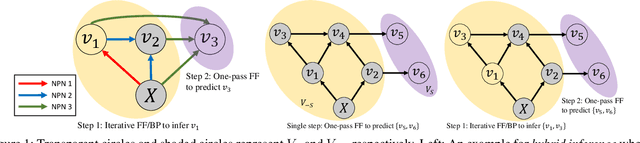
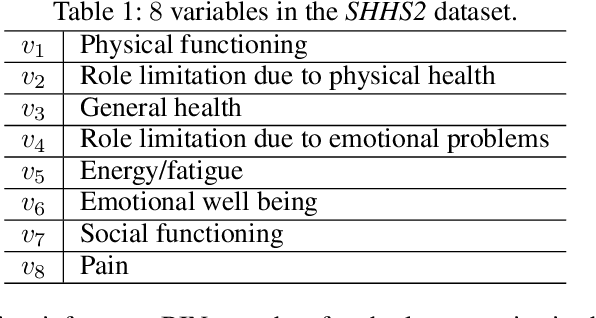
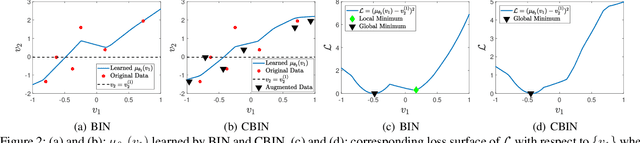
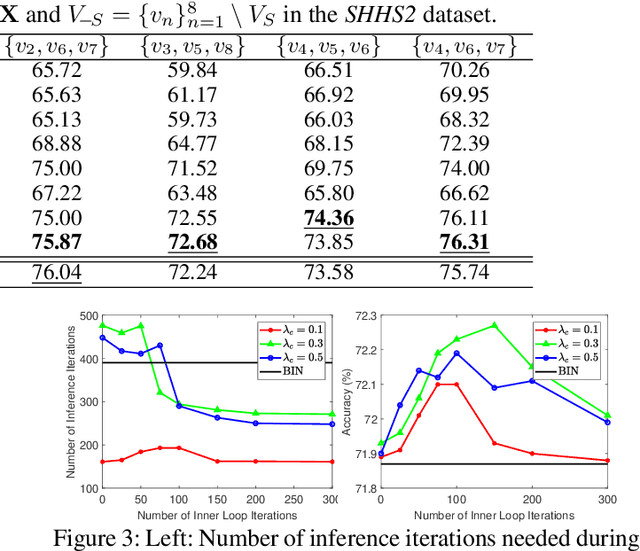
We consider the problem of inferring the values of an arbitrary set of variables (e.g., risk of diseases) given other observed variables (e.g., symptoms and diagnosed diseases) and high-dimensional signals (e.g., MRI images or EEG). This is a common problem in healthcare since variables of interest often differ for different patients. Existing methods including Bayesian networks and structured prediction either do not incorporate high-dimensional signals or fail to model conditional dependencies among variables. To address these issues, we propose bidirectional inference networks (BIN), which stich together multiple probabilistic neural networks, each modeling a conditional dependency. Predictions are then made via iteratively updating variables using backpropagation (BP) to maximize corresponding posterior probability. Furthermore, we extend BIN to composite BIN (CBIN), which involves the iterative prediction process in the training stage and improves both accuracy and computational efficiency by adaptively smoothing the optimization landscape. Experiments on synthetic and real-world datasets (a sleep study and a dermatology dataset) show that CBIN is a single model that can achieve state-of-the-art performance and obtain better accuracy in most inference tasks than multiple models each specifically trained for a different task.
Predictive Encoding of Contextual Relationships for Perceptual Inference, Interpolation and Prediction
Apr 16, 2015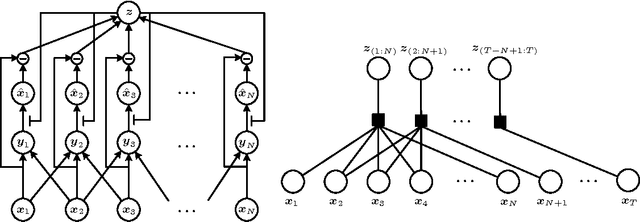



We propose a new neurally-inspired model that can learn to encode the global relationship context of visual events across time and space and to use the contextual information to modulate the analysis by synthesis process in a predictive coding framework. The model learns latent contextual representations by maximizing the predictability of visual events based on local and global contextual information through both top-down and bottom-up processes. In contrast to standard predictive coding models, the prediction error in this model is used to update the contextual representation but does not alter the feedforward input for the next layer, and is thus more consistent with neurophysiological observations. We establish the computational feasibility of this model by demonstrating its ability in several aspects. We show that our model can outperform state-of-art performances of gated Boltzmann machines (GBM) in estimation of contextual information. Our model can also interpolate missing events or predict future events in image sequences while simultaneously estimating contextual information. We show it achieves state-of-art performances in terms of prediction accuracy in a variety of tasks and possesses the ability to interpolate missing frames, a function that is lacking in GBM.