 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive Encoding of Contextual Relationships for Perceptual Inference, Interpolation and Prediction
Paper and Code
Apr 16, 2015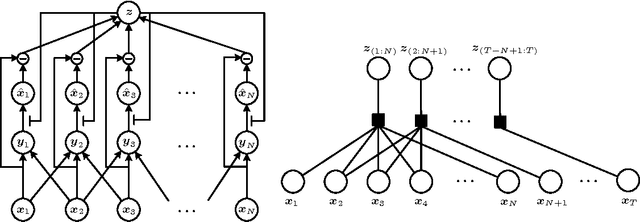



We propose a new neurally-inspired model that can learn to encode the global relationship context of visual events across time and space and to use the contextual information to modulate the analysis by synthesis process in a predictive coding framework. The model learns latent contextual representations by maximizing the predictability of visual events based on local and global contextual information through both top-down and bottom-up processes. In contrast to standard predictive coding models, the prediction error in this model is used to update the contextual representation but does not alter the feedforward input for the next layer, and is thus more consistent with neurophysiological observations. We establish the computational feasibility of this model by demonstrating its ability in several aspects. We show that our model can outperform state-of-art performances of gated Boltzmann machines (GBM) in estimation of contextual information. Our model can also interpolate missing events or predict future events in image sequences while simultaneously estimating contextual information. We show it achieves state-of-art performances in terms of prediction accuracy in a variety of tasks and possesses the ability to interpolate missing frames, a function that is lacking in GBM.