 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting and Controlling LLM Reasoning through Integrated Policy Gradient
Feb 03, 2026Large language models (LLMs) demonstrate strong reasoning abilities in solving complex real-world problems. Yet, the internal mechanisms driving these complex reasoning behaviors remain opaque. Existing interpretability approaches targeting reasoning either identify components (e.g., neurons) correlated with special textual patterns, or rely on human-annotated contrastive pairs to derive control vectors. Consequently, current methods struggle to precisely localize complex reasoning mechanisms or capture sequential influence from model internal workings to the reasoning outputs. In this paper, built on outcome-oriented and sequential-influence-aware principles, we focus on identifying components that have sequential contribution to reasoning behavior where outcomes are cumulated by long-range effects. We propose Integrated Policy Gradient (IPG), a novel framework that attributes reasoning behaviors to model's inner components by propagating compound outcome-based signals such as post reasoning accuracy backward through model inference trajectories. Empirical evaluations demonstrate that our approach achieves more precise localization and enables reliable modulation of reasoning behaviors (e.g., reasoning capability, reasoning strength) across diverse reasoning models.
MedCT: A Clinical Terminology Graph for Generative AI Applications in Healthcare
Jan 11, 2025



We introduce the world's first clinical terminology for the Chinese healthcare community, namely MedCT, accompanied by a clinical foundation model MedBERT and an entity linking model MedLink. The MedCT system enables standardized and programmable representation of Chinese clinical data, successively stimulating the development of new medicines, treatment pathways, and better patient outcomes for the populous Chinese community. Moreover, the MedCT knowledge graph provides a principled mechanism to minimize the hallucination problem of large language models (LLMs), therefore achieving significant levels of accuracy and safety in LLM-based clinical applications. By leveraging the LLMs' emergent capabilities of generativeness and expressiveness, we were able to rapidly built a production-quality terminology system and deployed to real-world clinical field within three months, while classical terminologies like SNOMED CT have gone through more than twenty years development. Our experiments show that the MedCT system achieves state-of-the-art (SOTA) performance in semantic matching and entity linking tasks, not only for Chinese but also for English. We also conducted a longitudinal field experiment by applying MedCT and LLMs in a representative spectrum of clinical tasks, including electronic health record (EHR) auto-generation and medical document search for diagnostic decision making. Our study shows a multitude of values of MedCT for clinical workflows and patient outcomes, especially in the new genre of clinical LLM applications. We present our approach in sufficient engineering detail, such that implementing a clinical terminology for other non-English societies should be readily reproducible. We openly release our terminology, models and algorithms, along with real-world clinical datasets for the development.
Let's Focus on Neuron: Neuron-Level Supervised Fine-tuning for Large Language Model
Mar 18, 2024



Large Language Models (LLMs) are composed of neurons that exhibit various behaviors and roles, which become increasingly diversified as models scale. Recent studies have revealed that not all neurons are active across different datasets, and this sparsity correlates positively with the task-specific ability, leading to advancements in model pruning and training efficiency. Traditional fine-tuning methods engage all parameters of LLMs, which is computationally expensive and may not be necessary. In contrast, Parameter-Efficient Fine-Tuning (PEFT) approaches aim to minimize the number of trainable parameters, yet they still operate at a relatively macro scale (e.g., layer-level). We introduce Neuron-Level Fine-Tuning (NeFT), a novel approach that refines the granularity of parameter training down to the individual neuron, enabling more precise and computationally efficient model updates. The experimental results show that NeFT not only exceeded the performance of full-parameter fine-tuning and PEFT but also provided insights into the analysis of neurons.
Predictive Control for Chasing a Ground Vehicle using a UAV
May 22, 2019

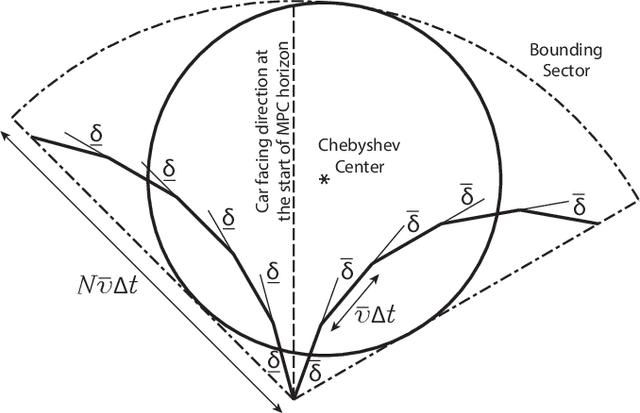
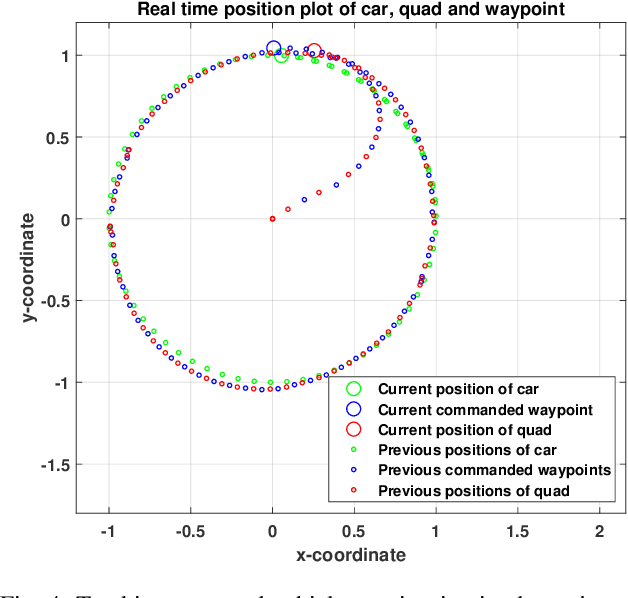
We propose a high-level planner for a multirotor to chase a ground vehicle, while simultaneously respecting various state and input constraints. Assuming a minimal kinematic model for the ground vehicle, we use data collected online to generate predictions for our planner within a model predictive control framework. Our solution is demonstrated, both via simulations and experiments on a stable quadcopter platform.