 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTigerBot: An Open Multilingual Multitask LLM
Dec 15, 2023
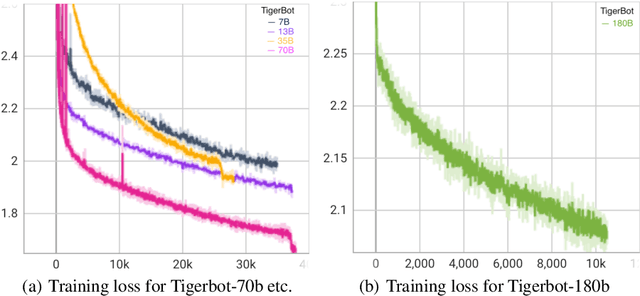
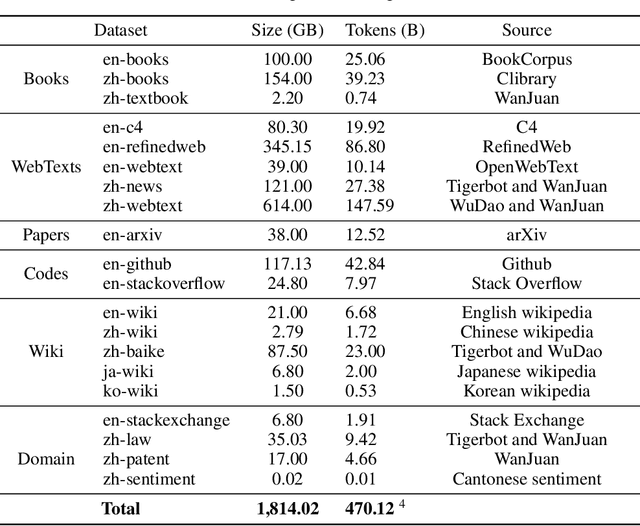
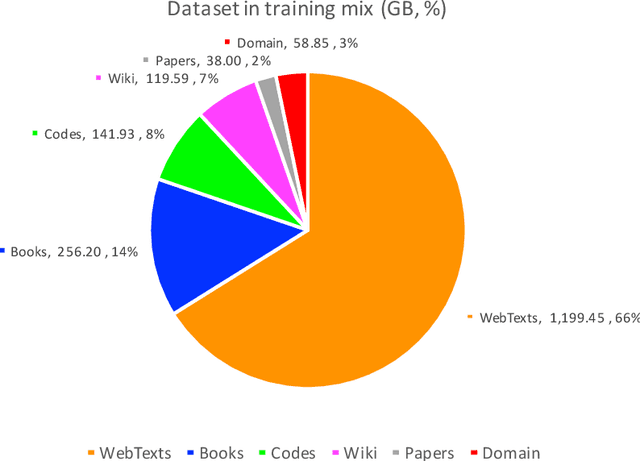
We release and introduce the TigerBot family of large language models (LLMs), consisting of base and chat models, sized from 7, 13, 70 and 180 billion parameters. We develop our models embarking from Llama-2 and BLOOM, and push the boundary further in data, training algorithm, infrastructure, and application tools. Our models yield meaningful performance gain over SOTA open-source models, e.g., Llama-2, specifically 6% gain in English and 20% gain in Chinese. TigerBot model family also achieves leading performance in major academic and industrial benchmarks and leaderboards. We believe that TigerBot represents just a snapshot of lightning-fast progression in LLM open-source community. Therefore, we are thrilled to give back by publicly releasing our models and reporting our approach behind, with additional emphases on building SOTA LLMs in a democratized way and making LLMs of use in real-world applications.