 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiHa: Introducing Hierarchical Harmonic Decomposition to Implicit Neural Compression for Atmospheric Data
Nov 09, 2024



The rapid development of large climate models has created the requirement of storing and transferring massive atmospheric data worldwide. Therefore, data compression is essential for meteorological research, but an efficient compression scheme capable of keeping high accuracy with high compressibility is still lacking. As an emerging technique, Implicit Neural Representation (INR) has recently acquired impressive momentum and demonstrates high promise for compressing diverse natural data. However, the INR-based compression encounters a bottleneck due to the sophisticated spatio-temporal properties and variability. To address this issue, we propose Hierarchical Harmonic decomposition implicit neural compression (HiHa) for atmospheric data. HiHa firstly segments the data into multi-frequency signals through decomposition of multiple complex harmonic, and then tackles each harmonic respectively with a frequency-based hierarchical compression module consisting of sparse storage, multi-scale INR and iterative decomposition sub-modules. We additionally design a temporal residual compression module to accelerate compression by utilizing temporal continuity. Experiments depict that HiHa outperforms both mainstream compressors and other INR-based methods in both compression fidelity and capabilities, and also demonstrate that using compressed data in existing data-driven models can achieve the same accuracy as raw data.
Smooth Q-learning: Accelerate Convergence of Q-learning Using Similarity
Jun 02, 2021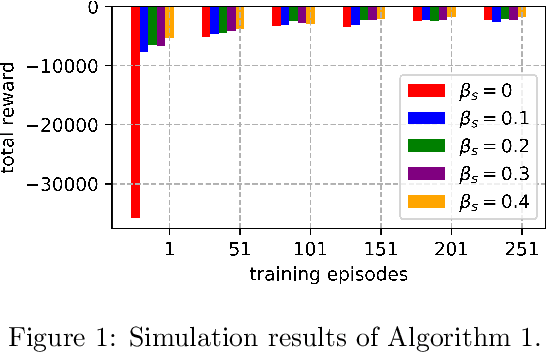
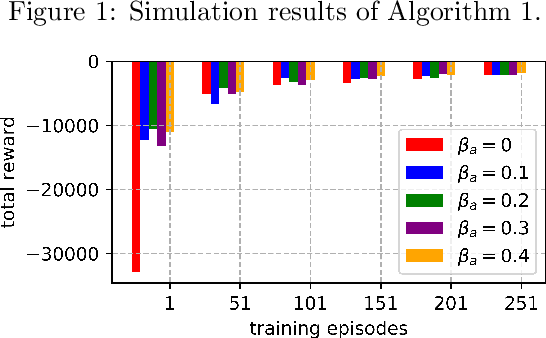
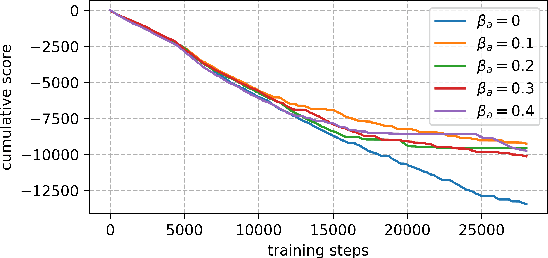
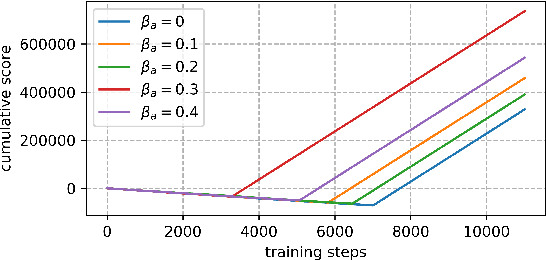
An improvement of Q-learning is proposed in this paper. It is different from classic Q-learning in that the similarity between different states and actions is considered in the proposed method. During the training, a new updating mechanism is used, in which the Q value of the similar state-action pairs are updated synchronously. The proposed method can be used in combination with both tabular Q-learning function and deep Q-learning. And the results of numerical examples illustrate that compared to the classic Q-learning, the proposed method has a significantly better performance.