 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPWOOD: Sparse Partial Weakly-Supervised Oriented Object Detection
Feb 03, 2026A consistent trend throughout the research of oriented object detection has been the pursuit of maintaining comparable performance with fewer and weaker annotations. This is particularly crucial in the remote sensing domain, where the dense object distribution and a wide variety of categories contribute to prohibitively high costs. Based on the supervision level, existing oriented object detection algorithms can be broadly grouped into fully supervised, semi-supervised, and weakly supervised methods. Within the scope of this work, we further categorize them to include sparsely supervised and partially weakly-supervised methods. To address the challenges of large-scale labeling, we introduce the first Sparse Partial Weakly-Supervised Oriented Object Detection framework, designed to efficiently leverage only a few sparse weakly-labeled data and plenty of unlabeled data. Our framework incorporates three key innovations: (1) We design a Sparse-annotation-Orientation-and-Scale-aware Student (SOS-Student) model to separate unlabeled objects from the background in a sparsely-labeled setting, and learn orientation and scale information from orientation-agnostic or scale-agnostic weak annotations. (2) We construct a novel Multi-level Pseudo-label Filtering strategy that leverages the distribution of model predictions, which is informed by the model's multi-layer predictions. (3) We propose a unique sparse partitioning approach, ensuring equal treatment for each category. Extensive experiments on the DOTA and DIOR datasets show that our framework achieves a significant performance gain over traditional oriented object detection methods mentioned above, offering a highly cost-effective solution. Our code is publicly available at https://github.com/VisionXLab/SPWOOD.
Qwen3Guard Technical Report
Oct 16, 2025As large language models (LLMs) become more capable and widely used, ensuring the safety of their outputs is increasingly critical. Existing guardrail models, though useful in static evaluation settings, face two major limitations in real-world applications: (1) they typically output only binary "safe/unsafe" labels, which can be interpreted inconsistently across diverse safety policies, rendering them incapable of accommodating varying safety tolerances across domains; and (2) they require complete model outputs before performing safety checks, making them fundamentally incompatible with streaming LLM inference, thereby preventing timely intervention during generation and increasing exposure to harmful partial outputs. To address these challenges, we present Qwen3Guard, a series of multilingual safety guardrail models with two specialized variants: Generative Qwen3Guard, which casts safety classification as an instruction-following task to enable fine-grained tri-class judgments (safe, controversial, unsafe); and Stream Qwen3Guard, which introduces a token-level classification head for real-time safety monitoring during incremental text generation. Both variants are available in three sizes (0.6B, 4B, and 8B parameters) and support up to 119 languages and dialects, providing comprehensive, scalable, and low-latency safety moderation for global LLM deployments. Evaluated across English, Chinese, and multilingual benchmarks, Qwen3Guard achieves state-of-the-art performance in both prompt and response safety classification. All models are released under the Apache 2.0 license for public use.
Learning Patient Static Information from Time-series EHR and an Approach for Safeguarding Privacy and Fairness
Sep 20, 2023



Recent work in machine learning for healthcare has raised concerns about patient privacy and algorithmic fairness. For example, previous work has shown that patient self-reported race can be predicted from medical data that does not explicitly contain racial information. However, the extent of data identification is unknown, and we lack ways to develop models whose outcomes are minimally affected by such information. Here we systematically investigated the ability of time-series electronic health record data to predict patient static information. We found that not only the raw time-series data, but also learned representations from machine learning models, can be trained to predict a variety of static information with area under the receiver operating characteristic curve as high as 0.851 for biological sex, 0.869 for binarized age and 0.810 for self-reported race. Such high predictive performance can be extended to a wide range of comorbidity factors and exists even when the model was trained for different tasks, using different cohorts, using different model architectures and databases. Given the privacy and fairness concerns these findings pose, we develop a variational autoencoder-based approach that learns a structured latent space to disentangle patient-sensitive attributes from time-series data. Our work thoroughly investigates the ability of machine learning models to encode patient static information from time-series electronic health records and introduces a general approach to protect patient-sensitive attribute information for downstream tasks.
Segmentation of Tubular Structures Using Iterative Training with Tailored Samples
Sep 15, 2023We propose a minimal path method to simultaneously compute segmentation masks and extract centerlines of tubular structures with line-topology. Minimal path methods are commonly used for the segmentation of tubular structures in a wide variety of applications. Recent methods use features extracted by CNNs, and often outperform methods using hand-tuned features. However, for CNN-based methods, the samples used for training may be generated inappropriately, so that they can be very different from samples encountered during inference. We approach this discrepancy by introducing a novel iterative training scheme, which enables generating better training samples specifically tailored for the minimal path methods without changing existing annotations. In our method, segmentation masks and centerlines are not determined after one another by post-processing, but obtained using the same steps. Our method requires only very few annotated training images. Comparison with seven previous approaches on three public datasets, including satellite images and medical images, shows that our method achieves state-of-the-art results both for segmentation masks and centerlines.
From CNN to Transformer: A Review of Medical Image Segmentation Models
Aug 10, 2023



Medical image segmentation is an important step in medical image analysis, especially as a crucial prerequisite for efficient disease diagnosis and treatment. The use of deep learning for image segmentation has become a prevalent trend. The widely adopted approach currently is U-Net and its variants. Additionally, with the remarkable success of pre-trained models in natural language processing tasks, transformer-based models like TransUNet have achieved desirable performance on multiple medical image segmentation datasets. In this paper, we conduct a survey of the most representative four medical image segmentation models in recent years. We theoretically analyze the characteristics of these models and quantitatively evaluate their performance on two benchmark datasets (i.e., Tuberculosis Chest X-rays and ovarian tumors). Finally, we discuss the main challenges and future trends in medical image segmentation. Our work can assist researchers in the related field to quickly establish medical segmentation models tailored to specific regions.
Learning to See Through with Events
Dec 05, 2022
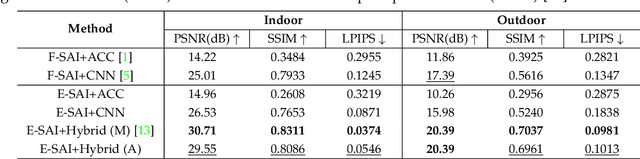
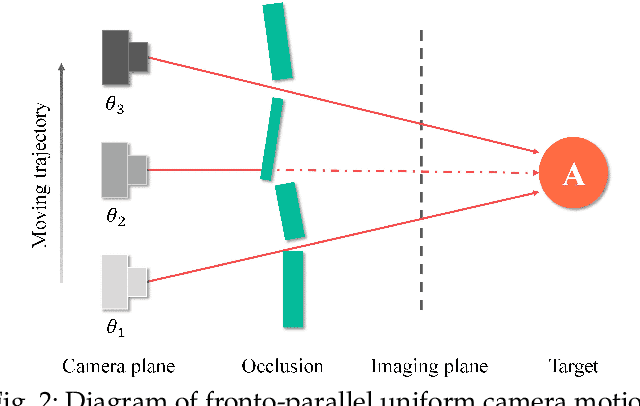
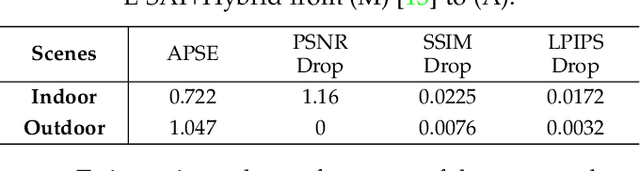
Although synthetic aperture imaging (SAI) can achieve the seeing-through effect by blurring out off-focus foreground occlusions while recovering in-focus occluded scenes from multi-view images, its performance is often deteriorated by dense occlusions and extreme lighting conditions. To address the problem, this paper presents an Event-based SAI (E-SAI) method by relying on the asynchronous events with extremely low latency and high dynamic range acquired by an event camera. Specifically, the collected events are first refocused by a Refocus-Net module to align in-focus events while scattering out off-focus ones. Following that, a hybrid network composed of spiking neural networks (SNNs) and convolutional neural networks (CNNs) is proposed to encode the spatio-temporal information from the refocused events and reconstruct a visual image of the occluded targets. Extensive experiments demonstrate that our proposed E-SAI method can achieve remarkable performance in dealing with very dense occlusions and extreme lighting conditions and produce high-quality images from pure events. Codes and datasets are available at https://dvs-whu.cn/projects/esai/.
Progressive Minimal Path Method with Embedded CNN
Apr 05, 2022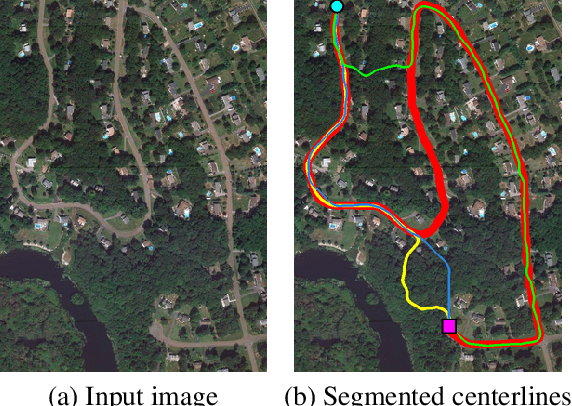

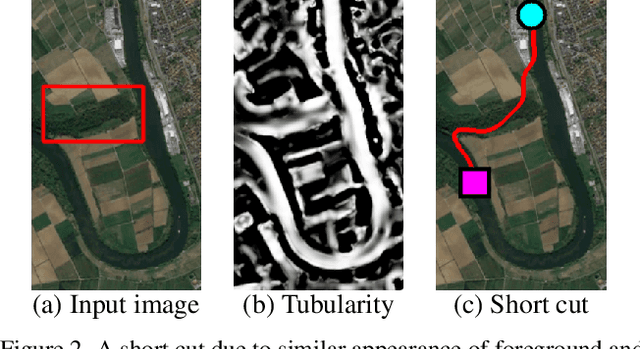

We propose Path-CNN, a method for the segmentation of centerlines of tubular structures by embedding convolutional neural networks (CNNs) into the progressive minimal path method. Minimal path methods are widely used for topology-aware centerline segmentation, but usually these methods rely on weak, hand-tuned image features. In contrast, CNNs use strong image features which are learned automatically from images. But CNNs usually do not take the topology of the results into account, and often require a large amount of annotations for training. We integrate CNNs into the minimal path method, so that both techniques benefit from each other: CNNs employ learned image features to improve the determination of minimal paths, while the minimal path method ensures the correct topology of the segmented centerlines, provides strong geometric priors to increase the performance of CNNs, and reduces the amount of annotations for the training of CNNs significantly. Our method has lower hardware requirements than many recent methods. Qualitative and quantitative comparison with other methods shows that Path-CNN achieves better performance, especially when dealing with tubular structures with complex shapes in challenging environments.
Smooth Q-learning: Accelerate Convergence of Q-learning Using Similarity
Jun 02, 2021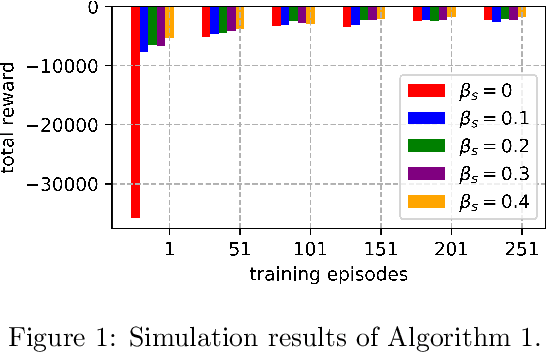
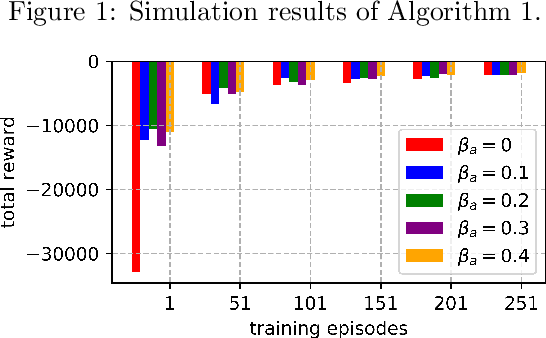
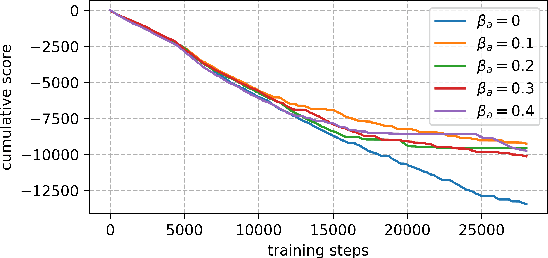
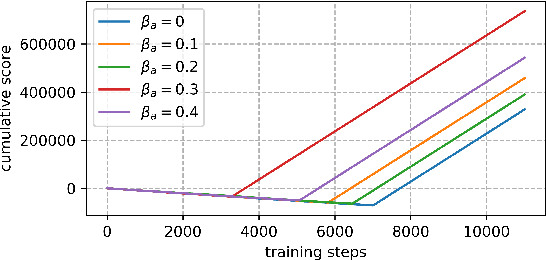
An improvement of Q-learning is proposed in this paper. It is different from classic Q-learning in that the similarity between different states and actions is considered in the proposed method. During the training, a new updating mechanism is used, in which the Q value of the similar state-action pairs are updated synchronously. The proposed method can be used in combination with both tabular Q-learning function and deep Q-learning. And the results of numerical examples illustrate that compared to the classic Q-learning, the proposed method has a significantly better performance.
Event-based Synthetic Aperture Imaging with a Hybrid Network
Mar 30, 2021
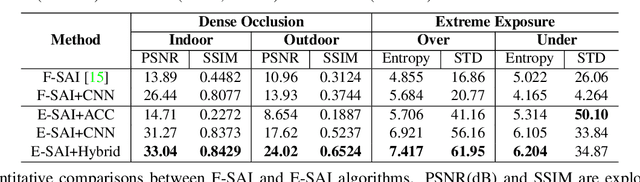


Synthetic aperture imaging (SAI) is able to achieve the see through effect by blurring out the off-focus foreground occlusions and reconstructing the in-focus occluded targets from multi-view images. However, very dense occlusions and extreme lighting conditions may bring significant disturbances to the SAI based on conventional frame-based cameras, leading to performance degeneration. To address these problems, we propose a novel SAI system based on the event camera which can produce asynchronous events with extremely low latency and high dynamic range. Thus, it can eliminate the interference of dense occlusions by measuring with almost continuous views, and simultaneously tackle the over/under exposure problems. To reconstruct the occluded targets, we propose a hybrid encoder-decoder network composed of spiking neural networks (SNNs) and convolutional neural networks (CNNs). In the hybrid network, the spatio-temporal information of the collected events is first encoded by SNN layers, and then transformed to the visual image of the occluded targets by a style-transfer CNN decoder. Through experiments, the proposed method shows remarkable performance in dealing with very dense occlusions and extreme lighting conditions, and high quality visual images can be reconstructed using pure event data.