 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCF-VC: Mitigate Catastrophic Forgetting in Class-Incremental Learning for Multimodal Video Captioning
Feb 27, 2024



To address the problem of catastrophic forgetting due to the invisibility of old categories in sequential input, existing work based on relatively simple categorization tasks has made some progress. In contrast, video captioning is a more complex task in multimodal scenario, which has not been explored in the field of incremental learning. After identifying this stability-plasticity problem when analyzing video with sequential input, we originally propose a method to Mitigate Catastrophic Forgetting in class-incremental learning for multimodal Video Captioning (MCF-VC). As for effectively maintaining good performance on old tasks at the macro level, we design Fine-grained Sensitivity Selection (FgSS) based on the Mask of Linear's Parameters and Fisher Sensitivity to pick useful knowledge from old tasks. Further, in order to better constrain the knowledge characteristics of old and new tasks at the specific feature level, we have created the Two-stage Knowledge Distillation (TsKD), which is able to learn the new task well while weighing the old task. Specifically, we design two distillation losses, which constrain the cross modal semantic information of semantic attention feature map and the textual information of the final outputs respectively, so that the inter-model and intra-model stylized knowledge of the old class is retained while learning the new class. In order to illustrate the ability of our model to resist forgetting, we designed a metric CIDER_t to detect the stage forgetting rate. Our experiments on the public dataset MSR-VTT show that the proposed method significantly resists the forgetting of previous tasks without replaying old samples, and performs well on the new task.
GRSDet: Learning to Generate Local Reverse Samples for Few-shot Object Detection
Dec 29, 2023



Few-shot object detection (FSOD) aims to achieve object detection only using a few novel class training data. Most of the existing methods usually adopt a transfer-learning strategy to construct the novel class distribution by transferring the base class knowledge. However, this direct way easily results in confusion between the novel class and other similar categories in the decision space. To address the problem, we propose generating local reverse samples (LRSamples) in Prototype Reference Frames to adaptively adjust the center position and boundary range of the novel class distribution to learn more discriminative novel class samples for FSOD. Firstly, we propose a Center Calibration Variance Augmentation (CCVA) module, which contains the selection rule of LRSamples, the generator of LRSamples, and augmentation on the calibrated distribution centers. Specifically, we design an intra-class feature converter (IFC) as the generator of CCVA to learn the selecting rule. By transferring the knowledge of IFC from the base training to fine-tuning, the IFC generates plentiful novel samples to calibrate the novel class distribution. Moreover, we propose a Feature Density Boundary Optimization (FDBO) module to adaptively adjust the importance of samples depending on their distance from the decision boundary. It can emphasize the importance of the high-density area of the similar class (closer decision boundary area) and reduce the weight of the low-density area of the similar class (farther decision boundary area), thus optimizing a clearer decision boundary for each category. We conduct extensive experiments to demonstrate the effectiveness of our proposed method. Our method achieves consistent improvement on the Pascal VOC and MS COCO datasets based on DeFRCN and MFDC baselines.
RefCrowd: Grounding the Target in Crowd with Referring Expressions
Jun 16, 2022
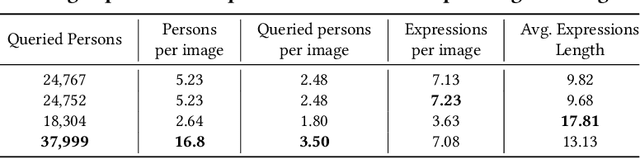

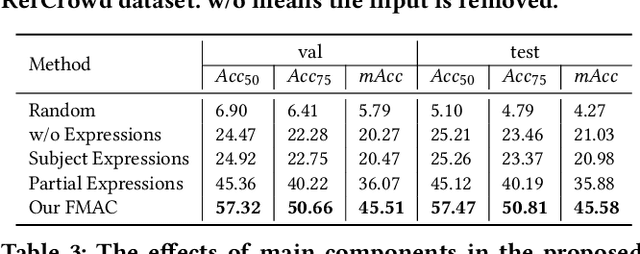
Crowd understanding has aroused the widespread interest in vision domain due to its important practical significance. Unfortunately, there is no effort to explore crowd understanding in multi-modal domain that bridges natural language and computer vision. Referring expression comprehension (REF) is such a representative multi-modal task. Current REF studies focus more on grounding the target object from multiple distinctive categories in general scenarios. It is difficult to applied to complex real-world crowd understanding. To fill this gap, we propose a new challenging dataset, called RefCrowd, which towards looking for the target person in crowd with referring expressions. It not only requires to sufficiently mine the natural language information, but also requires to carefully focus on subtle differences between the target and a crowd of persons with similar appearance, so as to realize the fine-grained mapping from language to vision. Furthermore, we propose a Fine-grained Multi-modal Attribute Contrastive Network (FMAC) to deal with REF in crowd understanding. It first decomposes the intricate visual and language features into attribute-aware multi-modal features, and then captures discriminative but robustness fine-grained attribute features to effectively distinguish these subtle differences between similar persons. The proposed method outperforms existing state-of-the-art (SoTA) methods on our RefCrowd dataset and existing REF datasets. In addition, we implement an end-to-end REF toolbox for the deeper research in multi-modal domain. Our dataset and code can be available at: \url{https://qiuheqian.github.io/datasets/refcrowd/}.