 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefCrowd: Grounding the Target in Crowd with Referring Expressions
Paper and Code

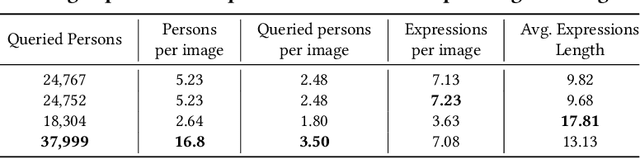

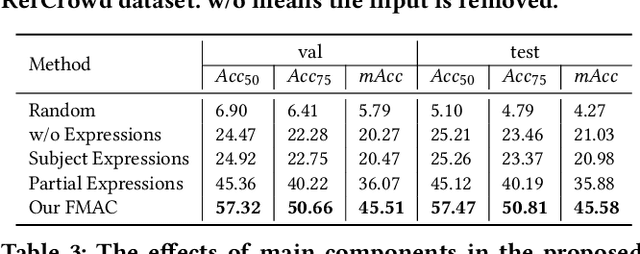
Crowd understanding has aroused the widespread interest in vision domain due to its important practical significance. Unfortunately, there is no effort to explore crowd understanding in multi-modal domain that bridges natural language and computer vision. Referring expression comprehension (REF) is such a representative multi-modal task. Current REF studies focus more on grounding the target object from multiple distinctive categories in general scenarios. It is difficult to applied to complex real-world crowd understanding. To fill this gap, we propose a new challenging dataset, called RefCrowd, which towards looking for the target person in crowd with referring expressions. It not only requires to sufficiently mine the natural language information, but also requires to carefully focus on subtle differences between the target and a crowd of persons with similar appearance, so as to realize the fine-grained mapping from language to vision. Furthermore, we propose a Fine-grained Multi-modal Attribute Contrastive Network (FMAC) to deal with REF in crowd understanding. It first decomposes the intricate visual and language features into attribute-aware multi-modal features, and then captures discriminative but robustness fine-grained attribute features to effectively distinguish these subtle differences between similar persons. The proposed method outperforms existing state-of-the-art (SoTA) methods on our RefCrowd dataset and existing REF datasets. In addition, we implement an end-to-end REF toolbox for the deeper research in multi-modal domain. Our dataset and code can be available at: \url{https://qiuheqian.github.io/datasets/refcrowd/}.