 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVGA: Vision GUI Assistant -- Minimizing Hallucinations through Image-Centric Fine-Tuning
Paper and Code
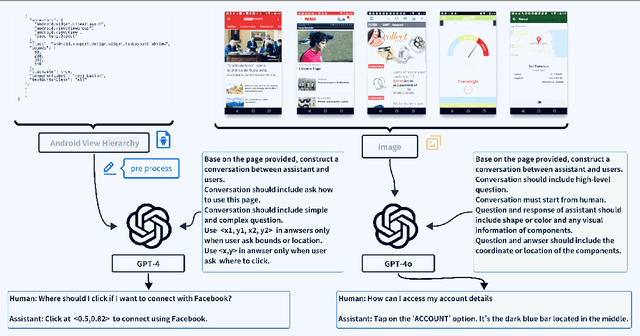
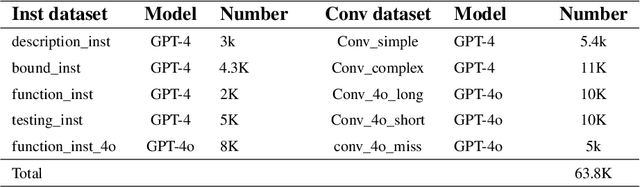

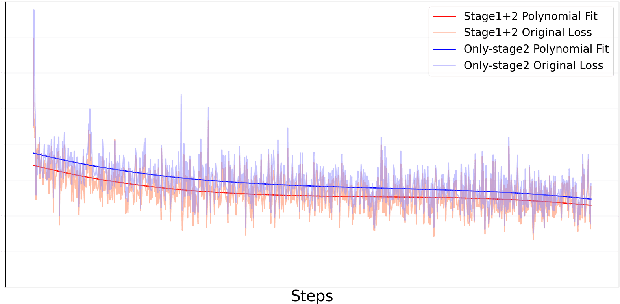
Recent advances in Large Vision-Language Models (LVLMs) have significantly improve performance in image comprehension tasks, such as formatted charts and rich-content images. Yet, Graphical User Interface (GUI) pose a greater challenge due to their structured format and detailed textual information. Existing LVLMs often overly depend on internal knowledge and neglect image content, resulting in hallucinations and incorrect responses in GUI comprehension.To address these issues, we introduce VGA, a fine-tuned model designed for comprehensive GUI understanding. Our model aims to enhance the interpretation of visual data of GUI and reduce hallucinations. We first construct a Vision Question Answering (VQA) dataset of 63.8k high-quality examples with our propose Referent Method, which ensures the model's responses are highly depend on visual content within the image. We then design a two-stage fine-tuning method called Foundation and Advanced Comprehension (FAC) to enhance both the model's ability to extract information from image content and alignment with human intent. Experiments show that our approach enhances the model's ability to extract information from images and achieves state-of-the-art results in GUI understanding tasks. Our dataset and fine-tuning script will be released soon.