 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSVBench: Evaluation of Video Generation Models on Social Reasoning
Dec 25, 2025Recent text-to-video generation models exhibit remarkable progress in visual realism, motion fidelity, and text-video alignment, yet they remain fundamentally limited in their ability to generate socially coherent behavior. Unlike humans, who effortlessly infer intentions, beliefs, emotions, and social norms from brief visual cues, current models tend to render literal scenes without capturing the underlying causal or psychological logic. To systematically evaluate this gap, we introduce the first benchmark for social reasoning in video generation. Grounded in findings from developmental and social psychology, our benchmark organizes thirty classic social cognition paradigms into seven core dimensions, including mental-state inference, goal-directed action, joint attention, social coordination, prosocial behavior, social norms, and multi-agent strategy. To operationalize these paradigms, we develop a fully training-free agent-based pipeline that (i) distills the reasoning mechanism of each experiment, (ii) synthesizes diverse video-ready scenarios, (iii) enforces conceptual neutrality and difficulty control through cue-based critique, and (iv) evaluates generated videos using a high-capacity VLM judge across five interpretable dimensions of social reasoning. Using this framework, we conduct the first large-scale study across seven state-of-the-art video generation systems. Our results reveal substantial performance gaps: while modern models excel in surface-level plausibility, they systematically fail in intention recognition, belief reasoning, joint attention, and prosocial inference.
Yume: An Interactive World Generation Model
Jul 23, 2025

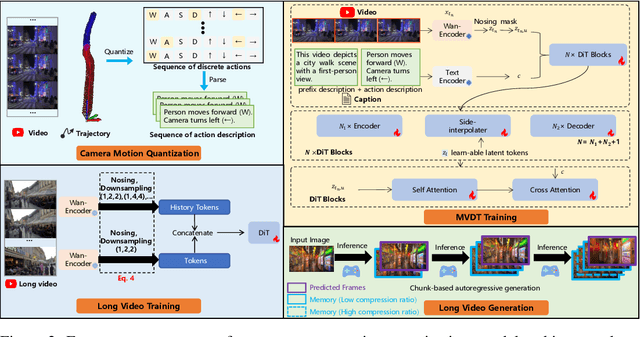

Yume aims to use images, text, or videos to create an interactive, realistic, and dynamic world, which allows exploration and control using peripheral devices or neural signals. In this report, we present a preview version of \method, which creates a dynamic world from an input image and allows exploration of the world using keyboard actions. To achieve this high-fidelity and interactive video world generation, we introduce a well-designed framework, which consists of four main components, including camera motion quantization, video generation architecture, advanced sampler, and model acceleration. First, we quantize camera motions for stable training and user-friendly interaction using keyboard inputs. Then, we introduce the Masked Video Diffusion Transformer~(MVDT) with a memory module for infinite video generation in an autoregressive manner. After that, training-free Anti-Artifact Mechanism (AAM) and Time Travel Sampling based on Stochastic Differential Equations (TTS-SDE) are introduced to the sampler for better visual quality and more precise control. Moreover, we investigate model acceleration by synergistic optimization of adversarial distillation and caching mechanisms. We use the high-quality world exploration dataset \sekai to train \method, and it achieves remarkable results in diverse scenes and applications. All data, codebase, and model weights are available on https://github.com/stdstu12/YUME. Yume will update monthly to achieve its original goal. Project page: https://stdstu12.github.io/YUME-Project/.
T3M: Text Guided 3D Human Motion Synthesis from Speech
Aug 23, 2024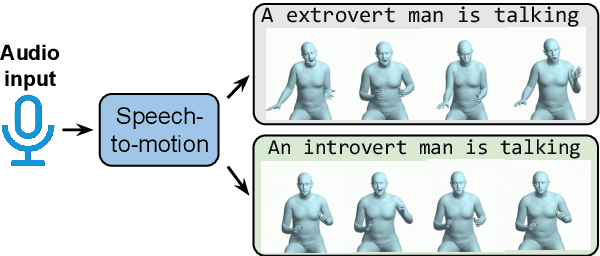
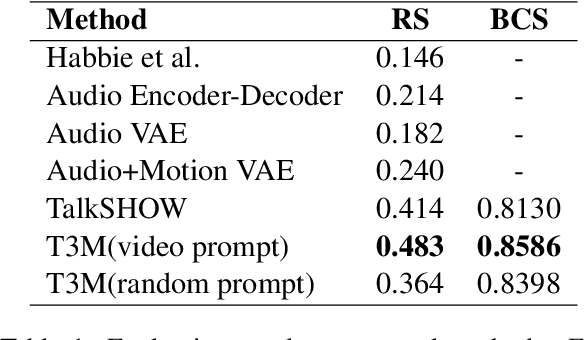
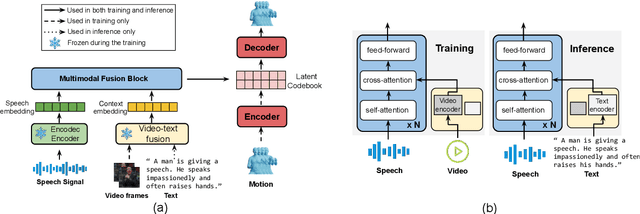
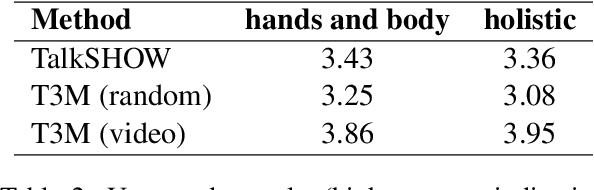
Speech-driven 3D motion synthesis seeks to create lifelike animations based on human speech, with potential uses in virtual reality, gaming, and the film production. Existing approaches reply solely on speech audio for motion generation, leading to inaccurate and inflexible synthesis results. To mitigate this problem, we introduce a novel text-guided 3D human motion synthesis method, termed \textit{T3M}. Unlike traditional approaches, T3M allows precise control over motion synthesis via textual input, enhancing the degree of diversity and user customization. The experiment results demonstrate that T3M can greatly outperform the state-of-the-art methods in both quantitative metrics and qualitative evaluations. We have publicly released our code at \href{https://github.com/Gloria2tt/T3M.git}{https://github.com/Gloria2tt/T3M.git}
Data Adaptive Traceback for Vision-Language Foundation Models in Image Classification
Jul 11, 2024Vision-language foundation models have been incredibly successful in a wide range of downstream computer vision tasks using adaptation methods. However, due to the high cost of obtaining pre-training datasets, pairs with weak image-text correlation in the data exist in large numbers. We call them weak-paired samples. Due to the limitations of these weak-paired samples, the pre-training model are unable to mine all the knowledge from pre-training data. The existing adaptation methods do not consider the missing knowledge, which may lead to crucial task-related knowledge for the downstream tasks being ignored. To address this issue, we propose a new adaptation framework called Data Adaptive Traceback (DAT). Specifically, we utilize a zero-shot-based method to extract the most downstream task-related subset of the pre-training data to enable the downstream tasks. Furthermore, we adopt a pseudo-label-based semi-supervised technique to reuse the pre-training images and a vision-language contrastive learning method to address the confirmation bias issue in semi-supervised learning. We conduct extensive experiments that show our proposed DAT approach meaningfully improves various benchmark datasets performance over traditional adaptation methods by simply.