 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScan Clusters, Not Pixels: A Cluster-Centric Paradigm for Efficient Ultra-high-definition Image Restoration
Feb 25, 2026Ultra-High-Definition (UHD) image restoration is trapped in a scalability crisis: existing models, bound to pixel-wise operations, demand unsustainable computation. While state space models (SSMs) like Mamba promise linear complexity, their pixel-serial scanning remains a fundamental bottleneck for the millions of pixels in UHD content. We ask: must we process every pixel to understand the image? This paper introduces C$^2$SSM, a visual state space model that breaks this taboo by shifting from pixel-serial to cluster-serial scanning. Our core discovery is that the rich feature distribution of a UHD image can be distilled into a sparse set of semantic centroids via a neural-parameterized mixture model. C$^2$SSM leverages this to reformulate global modeling into a novel dual-path process: it scans and reasons over a handful of cluster centers, then diffuses the global context back to all pixels through a principled similarity distribution, all while a lightweight modulator preserves fine details. This cluster-centric paradigm achieves a decisive leap in efficiency, slashing computational costs while establishing new state-of-the-art results across five UHD restoration tasks. More than a solution, C$^2$SSM charts a new course for efficient large-scale vision: scan clusters, not pixels.
SAR-GTR: Attributed Scattering Information Guided SAR Graph Transformer Recognition Algorithm
May 13, 2025Utilizing electromagnetic scattering information for SAR data interpretation is currently a prominent research focus in the SAR interpretation domain. Graph Neural Networks (GNNs) can effectively integrate domain-specific physical knowledge and human prior knowledge, thereby alleviating challenges such as limited sample availability and poor generalization in SAR interpretation. In this study, we thoroughly investigate the electromagnetic inverse scattering information of single-channel SAR and re-examine the limitations of applying GNNs to SAR interpretation. We propose the SAR Graph Transformer Recognition Algorithm (SAR-GTR). SAR-GTR carefully considers the attributes and characteristics of different electromagnetic scattering parameters by distinguishing the mapping methods for discrete and continuous parameters, thereby avoiding information confusion and loss. Furthermore, the GTR combines GNNs with the Transformer mechanism and introduces an edge information enhancement channel to facilitate interactive learning of node and edge features, enabling the capture of robust and global structural characteristics of targets. Additionally, the GTR constructs a hierarchical topology-aware system through global node encoding and edge position encoding, fully exploiting the hierarchical structural information of targets. Finally, the effectiveness of the algorithm is validated using the ATRNet-STAR large-scale vehicle dataset.
Sparse Tensor PCA via Tensor Decomposition for Unsupervised Feature Selection
Jul 24, 2024
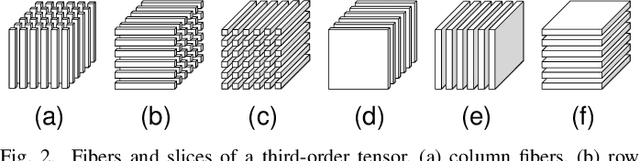
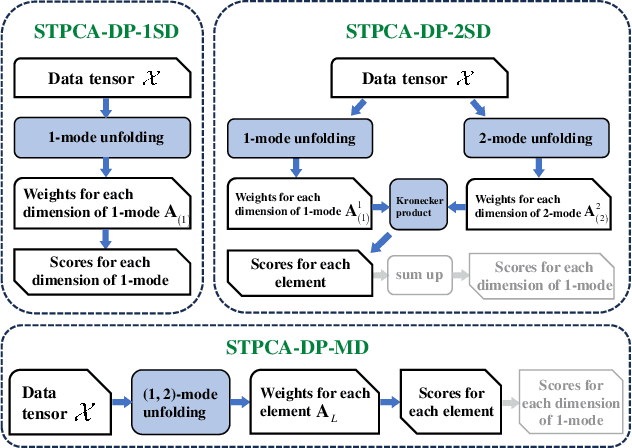
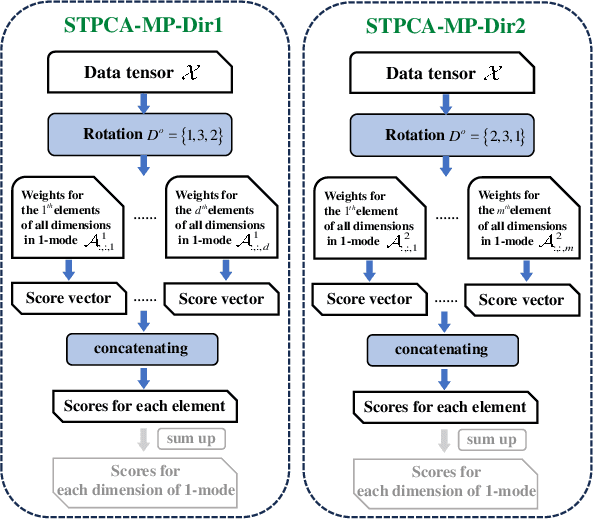
Recently, introducing Tensor Decomposition (TD) methods into unsupervised feature selection (UFS) has been a rising research point. A tensor structure is beneficial for mining the relations between different modes and helps relieve the computation burden. However, while existing methods exploit TD to minimize the reconstruction error of a data tensor, they don't fully utilize the interpretable and discriminative information in the factor matrices. Moreover, most methods require domain knowledge to perform feature selection. To solve the above problems, we develop two Sparse Tensor Principal Component Analysis (STPCA) models that utilize the projection directions in the factor matrices to perform UFS. The first model extends Tucker Decomposition to a multiview sparse regression form and is transformed into several alternatively solved convex subproblems. The second model formulates a sparse version of the family of Tensor Singular Value Decomposition (T-SVDs) and is transformed into individual convex subproblems. For both models, we prove the optimal solution of each subproblem falls onto the Hermitian Positive Semidefinite Cone (HPSD). Accordingly, we design two fast algorithms based on HPSD projection and prove their convergence. According to the experimental results on two original synthetic datasets (Orbit and Array Signal) and five real-world datasets, the two proposed methods are suitable for handling different data tensor scenarios and outperform the state-of-the-art UFS methods.
Worst-Case Riemannian Optimization with Uncertain Target Steering Vector for Slow-Time Transmit Sequence of Cognitive Radar
Apr 16, 2024



Optimization of slow-time transmit sequence endows cognitive radar with the ability to suppress strong clutter in the range-Doppler domain. However, in practice, inaccurate target velocity information or random phase error would induce uncertainty about the actual target steering vector, which would in turn severely deteriorate the the performance of the slow-time matched filter. In order to solve this problem, we propose a new optimization method for slow-time transmit sequence design. The proposed method transforms the original non-convex optimization with an uncertain target steering vector into a two-step worst-case optimization problem. For each sub-problem, we develop a corresponding trust-region Riemannian optimization algorithm. By iteratively solving the two sub-problems, a sub-optimal solution can be reached without accurate information about the target steering vector. Furthermore, the convergence property of the proposed algorithms has been analyzed and detailed proof of the convergence is given. Unlike the traditional waveform optimization method, the proposed method is designed to work with an uncertain target steering vector and therefore, is more robust in practical radar systems. Numerical simulation results in different scenarios verify the effectiveness of the proposed method in suppressing the clutter and show its advantages in terms of the output signal-to-clutter plus noise ratio (SCNR) over traditional methods.
LDSF: Lightweight Dual-Stream Framework for SAR Target Recognition by Coupling Local Electromagnetic Scattering Features and Global Visual Features
Mar 06, 2024



Mainstream DNN-based SAR-ATR methods still face issues such as easy overfitting of a few training data, high computational overhead, and poor interpretability of the black-box model. Integrating physical knowledge into DNNs to improve performance and achieve a higher level of physical interpretability becomes the key to solving the above problems. This paper begins by focusing on the electromagnetic (EM) backscattering mechanism. We extract the EM scattering (EMS) information from the complex SAR data and integrate the physical properties of the target into the network through a dual-stream framework to guide the network to learn physically meaningful and discriminative features. Specifically, one stream is the local EMS feature (LEMSF) extraction net. It is a heterogeneous graph neural network (GNN) guided by a multi-level multi-head attention mechanism. LEMSF uses the EMS information to obtain topological structure features and high-level physical semantic features. The other stream is a CNN-based global visual features (GVF) extraction net that captures the visual features of SAR pictures from the image domain. After obtaining the two-stream features, a feature fusion subnetwork is proposed to adaptively learn the fusion strategy. Thus, the two-stream features can maximize the performance. Furthermore, the loss function is designed based on the graph distance measure to promote intra-class aggregation. We discard overly complex design ideas and effectively control the model size while maintaining algorithm performance. Finally, to better validate the performance and generalizability of the algorithms, two more rigorous evaluation protocols, namely once-for-all (OFA) and less-for-more (LFM), are used to verify the superiority of the proposed algorithm on the MSTAR.
Fast Sparse PCA via Positive Semidefinite Projection for Unsupervised Feature Selection
Sep 12, 2023In the field of unsupervised feature selection, sparse principal component analysis (SPCA) methods have attracted more and more attention recently. Compared to spectral-based methods, SPCA methods don't rely on the construction of a similarity matrix and show better feature selection ability on real-world data. The original SPCA formulates a nonconvex optimization problem. Existing convex SPCA methods reformulate SPCA as a convex model by regarding the reconstruction matrix as an optimization variable. However, they are lack of constraints equivalent to the orthogonality restriction in SPCA, leading to larger solution space. In this paper, it's proved that the optimal solution to a convex SPCA model falls onto the Positive Semidefinite (PSD) cone. A standard convex SPCA-based model with PSD constraint for unsupervised feature selection is proposed. Further, a two-step fast optimization algorithm via PSD projection is presented to solve the proposed model. Two other existing convex SPCA-based models are also proven to have their solutions optimized on the PSD cone in this paper. Therefore, the PSD versions of these two models are proposed to accelerate their convergence as well. We also provide a regularization parameter setting strategy for our proposed method. Experiments on synthetic and real-world datasets demonstrate the effectiveness and efficiency of the proposed methods.
ROFusion: Efficient Object Detection using Hybrid Point-wise Radar-Optical Fusion
Jul 17, 2023



Radars, due to their robustness to adverse weather conditions and ability to measure object motions, have served in autonomous driving and intelligent agents for years. However, Radar-based perception suffers from its unintuitive sensing data, which lack of semantic and structural information of scenes. To tackle this problem, camera and Radar sensor fusion has been investigated as a trending strategy with low cost, high reliability and strong maintenance. While most recent works explore how to explore Radar point clouds and images, rich contextual information within Radar observation are discarded. In this paper, we propose a hybrid point-wise Radar-Optical fusion approach for object detection in autonomous driving scenarios. The framework benefits from dense contextual information from both the range-doppler spectrum and images which are integrated to learn a multi-modal feature representation. Furthermore, we propose a novel local coordinate formulation, tackling the object detection task in an object-centric coordinate. Extensive results show that with the information gained from optical images, we could achieve leading performance in object detection (97.69\% recall) compared to recent state-of-the-art methods FFT-RadNet (82.86\% recall). Ablation studies verify the key design choices and practicability of our approach given machine generated imperfect detections. The code will be available at https://github.com/LiuLiu-55/ROFusion.
A classification performance evaluation measure considering data separability
Nov 10, 2022Machine learning and deep learning classification models are data-driven, and the model and the data jointly determine their classification performance. It is biased to evaluate the model's performance only based on the classifier accuracy while ignoring the data separability. Sometimes, the model exhibits excellent accuracy, which might be attributed to its testing on highly separable data. Most of the current studies on data separability measures are defined based on the distance between sample points, but this has been demonstrated to fail in several circumstances. In this paper, we propose a new separability measure--the rate of separability (RS), which is based on the data coding rate. We validate its effectiveness as a supplement to the separability measure by comparing it to four other distance-based measures on synthetic datasets. Then, we demonstrate the positive correlation between the proposed measure and recognition accuracy in a multi-task scenario constructed from a real dataset. Finally, we discuss the methods for evaluating the classification performance of machine learning and deep learning models considering data separability.
Ambiguity Function Shaping based on Alternating Direction Riemannian Optimal Algorithm
Sep 08, 2022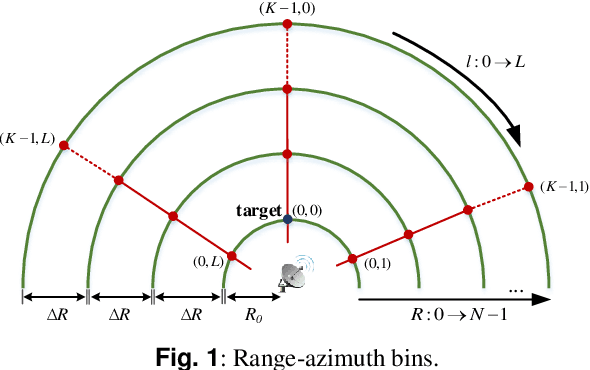

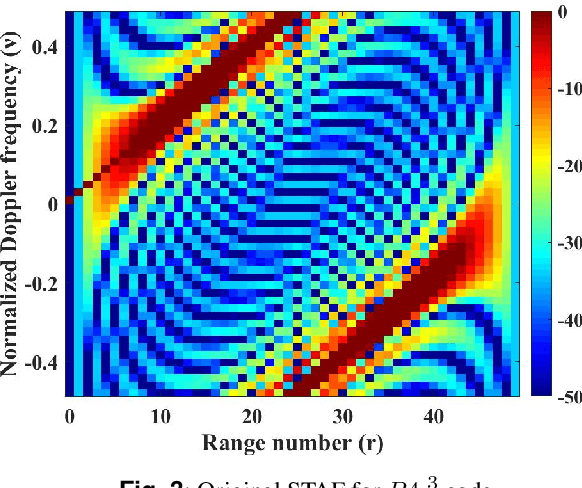
In order to improve the ability of cognitive radar (CR) to adapt to the environment, the required ambiguity function (AF) can be synthesized by designing the waveform. The key to this problem is how to minimize the interference power. Suppressing the interference power is equivalent to minimize the expectation of slow-time ambiguity function (STAF) over range-Doppler bins. From a technical point of view, this is actually an optimization problem of a non-convex quartic function with constant modulus constraints (CMC). In this paper, we proposed a novel method to design a waveform to synthesize the STAF based on suppressing the interference power. We put forward an iterative algorithm within an alternating direction penalty method (ADPM) framework. In each iteration, this problem is split into two sub-problems by introducing auxiliary variables. In the first sub-problem, we solved the convex problem directly with a closed-form solution, then utilized the Riemannian trust region (RTR) algorithm in the second sub-problem. Simulation results demonstrate that the proposed algorithm outperforms other advanced algorithms in the aspects of STAF, range-cut and signal-to-interference-ratio (SIR) value.