 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Learnable Keyframe Extraction in Videos and its Application with Semantic Word Vector in Action Recognition
Sep 25, 2020
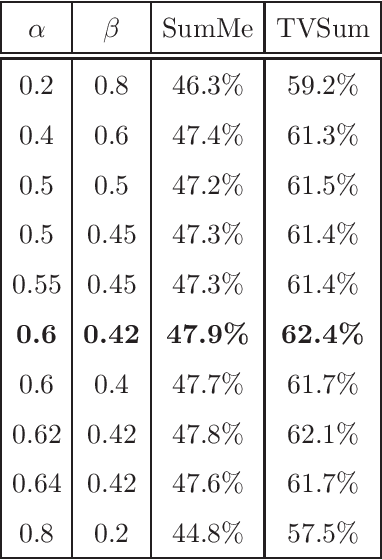
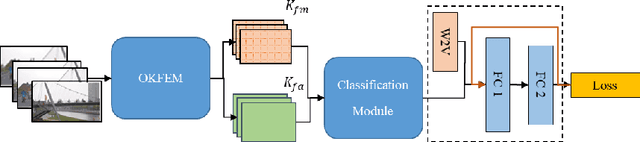

Video processing has become a popular research direction in computer vision due to its various applications such as video summarization, action recognition, etc. Recently, deep learning-based methods have achieved impressive results in action recognition. However, these methods need to process a full video sequence to recognize the action, even though most of these frames are similar and non-essential to recognizing a particular action. Additionally, these non-essential frames increase the computational cost and can confuse a method in action recognition. Instead, the important frames called keyframes not only are helpful in the recognition of an action but also can reduce the processing time of each video sequence for classification or in other applications, e.g. summarization. As well, current methods in video processing have not yet been demonstrated in an online fashion. Motivated by the above, we propose an online learnable module for keyframe extraction. This module can be used to select key-shots in video and thus can be applied to video summarization. The extracted keyframes can be used as input to any deep learning-based classification model to recognize action. We also propose a plugin module to use the semantic word vector as input along with keyframes and a novel train/test strategy for the classification models. To our best knowledge, this is the first time such an online module and train/test strategy have been proposed. The experimental results on many commonly used datasets in video summarization and in action recognition have shown impressive results using the proposed module.
Texture Classification of MR Images of the Brain in ALS using CoHOG
Sep 25, 2017
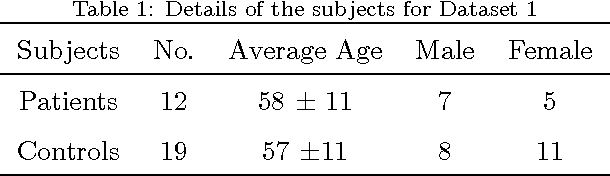
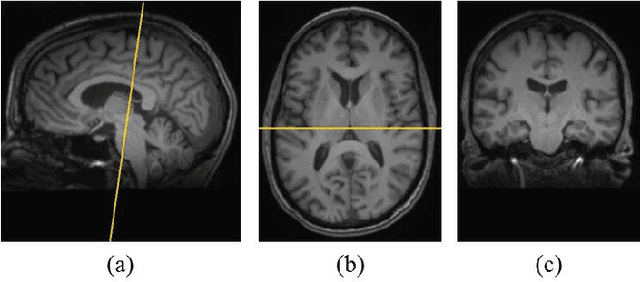

Texture analysis is a well-known research topic in computer vision and image processing and has many applications. Gradient-based texture methods have become popular in classification problems. For the first time we extend a well-known gradient-based method, Co-occurrence Histograms of Oriented Gradients (CoHOG) to extract texture features from 2D Magnetic Resonance Images (MRI). Unlike the original CoHOG method, we use the whole image instead of sub-regions for feature calculation. Also, we use a larger neighborhood size. Gradient orientations of the image pixels are calculated using Sobel, Gaussian Derivative (GD) and Local Frequency Descriptor Gradient (LFDG) operators. The extracted feature vector size is very large and classification using a large number of similar features does not provide the best results. In our proposed method, for the first time to our best knowledge, only a minimum number of significant features are selected using area under the receiver operator characteristic (ROC) curve (AUC) thresholds with <= 0.01. In this paper, we apply the proposed method to classify Amyotrophic Lateral Sclerosis (ALS) patients from the controls. It is observed that selected texture features from downsampled images are significantly different between patients and controls. These features are used in a linear support vector machine (SVM) classifier to determine the classification accuracy. Optimal sensitivity and specificity are also calculated. Three different cohort datasets are used in the experiments. The performance of the proposed method using three gradient operators and two different neighborhood sizes is analyzed. Region based analysis is performed to demonstrate that significant changes between patients and controls are limited to the motor cortex.