 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust model training and generalisation with Studentising flows
Paper and Code

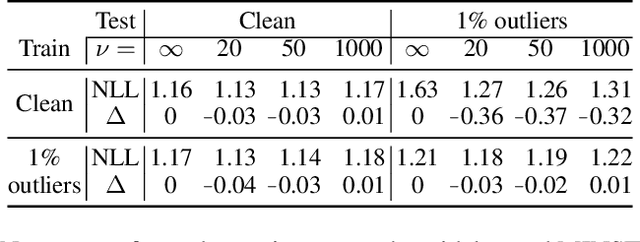
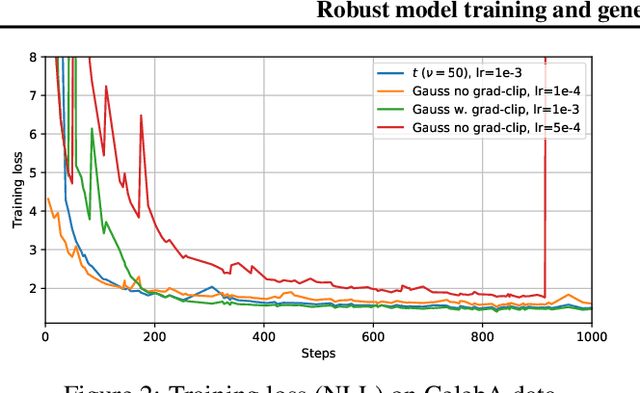

Normalising flows are tractable probabilistic models that leverage the power of deep learning to describe a wide parametric family of distributions, all while remaining trainable using maximum likelihood. We discuss how these methods can be further improved based on insights from robust (in particular, resistant) statistics. Specifically, we propose to endow flow-based models with fat-tailed latent distributions such as multivariate Student's $t$, as a simple drop-in replacement for the Gaussian distribution used by conventional normalising flows. While robustness brings many advantages, this paper explores two of them: 1) We describe how using fatter-tailed base distributions can give benefits similar to gradient clipping, but without compromising the asymptotic consistency of the method. 2) We also discuss how robust ideas lead to models with reduced generalisation gap and improved held-out data likelihood. Experiments on several different datasets confirm the efficacy of the proposed approach in both regards.