 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCARL-GT: Evaluating Causal Reasoning Capabilities of Large Language Models
Paper and Code
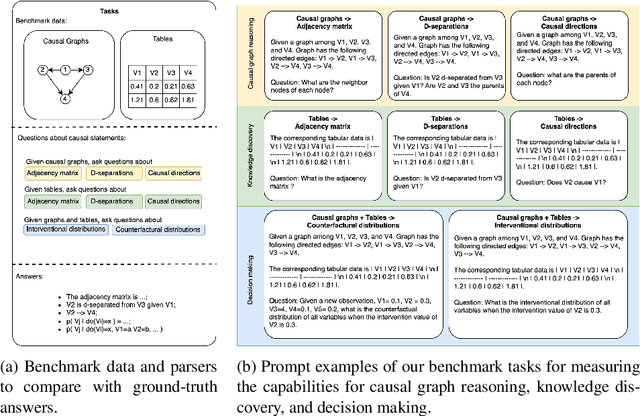


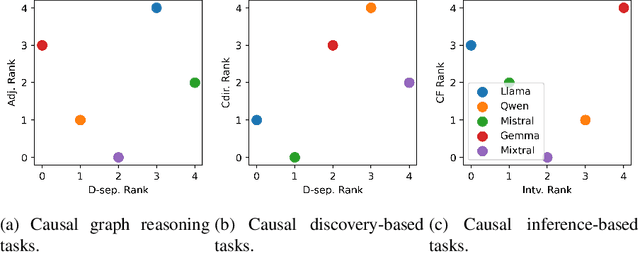
Causal reasoning capabilities are essential for large language models (LLMs) in a wide range of applications, such as education and healthcare. But there is still a lack of benchmarks for a better understanding of such capabilities. Current LLM benchmarks are mainly based on conversational tasks, academic math tests, and coding tests. Such benchmarks evaluate LLMs in well-regularized settings, but they are limited in assessing the skills and abilities to solve real-world problems. In this work, we provide a benchmark, named by CARL-GT, which evaluates CAusal Reasoning capabilities of large Language models using Graphs and Tabular data. The benchmark has a diverse range of tasks for evaluating LLMs from causal graph reasoning, knowledge discovery, and decision-making aspects. In addition, effective zero-shot learning prompts are developed for the tasks. In our experiments, we leverage the benchmark for evaluating open-source LLMs and provide a detailed comparison of LLMs for causal reasoning abilities. We found that LLMs are still weak in casual reasoning, especially with tabular data to discover new insights. Furthermore, we investigate and discuss the relationships of different benchmark tasks by analyzing the performance of LLMs. The experimental results show that LLMs have different strength over different tasks and that their performance on tasks in different categories, i.e., causal graph reasoning, knowledge discovery, and decision-making, shows stronger correlation than tasks in the same category.