 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDataset Cleaning -- A Cross Validation Methodology for Large Facial Datasets using Face Recognition
Paper and Code
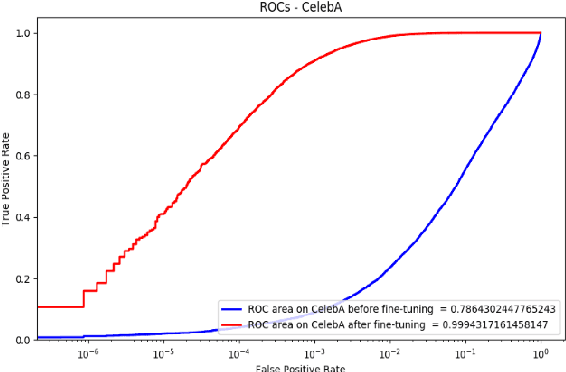
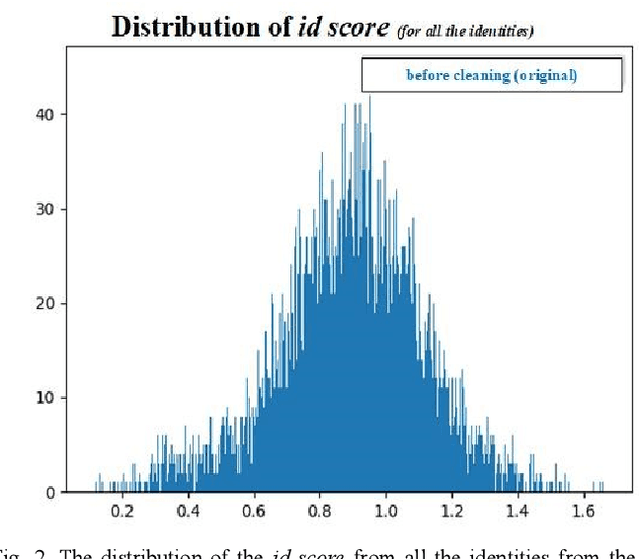


In recent years, large "in the wild" face datasets have been released in an attempt to facilitate progress in tasks such as face detection, face recognition, and other tasks. Most of these datasets are acquired from webpages with automatic procedures. As a consequence, noisy data are often found. Furthermore, in these large face datasets, the annotation of identities is important as they are used for training face recognition algorithms. But due to the automatic way of gathering these datasets and due to their large size, many identities folder contain mislabeled samples which deteriorates the quality of the datasets. In this work, it is presented a semi-automatic method for cleaning the noisy large face datasets with the use of face recognition. This methodology is applied to clean the CelebA dataset and show its effectiveness. Furthermore, the list with the mislabelled samples in the CelebA dataset is made available.