 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Visemes for Better Visual Speech Representation and Lip Reading
Jul 19, 2023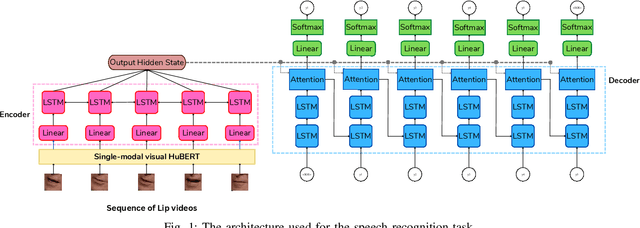
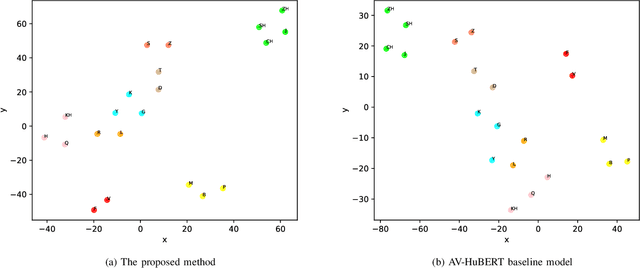
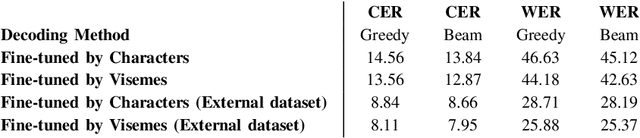
Lip reading is a challenging task that has many potential applications in speech recognition, human-computer interaction, and security systems. However, existing lip reading systems often suffer from low accuracy due to the limitations of video features. In this paper, we propose a novel approach that leverages visemes, which are groups of phonetically similar lip shapes, to extract more discriminative and robust video features for lip reading. We evaluate our approach on various tasks, including word-level and sentence-level lip reading, and audiovisual speech recognition using the Arman-AV dataset, a largescale Persian corpus. Our experimental results show that our viseme based approach consistently outperforms the state-of-theart methods in all these tasks. The proposed method reduces the lip-reading word error rate (WER) by 9.1% relative to the best previous method.
Word-level Persian Lipreading Dataset
Apr 08, 2023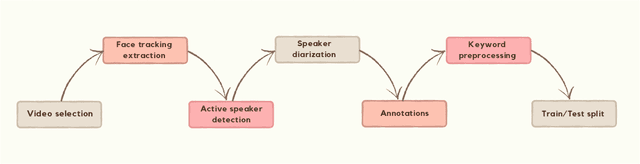

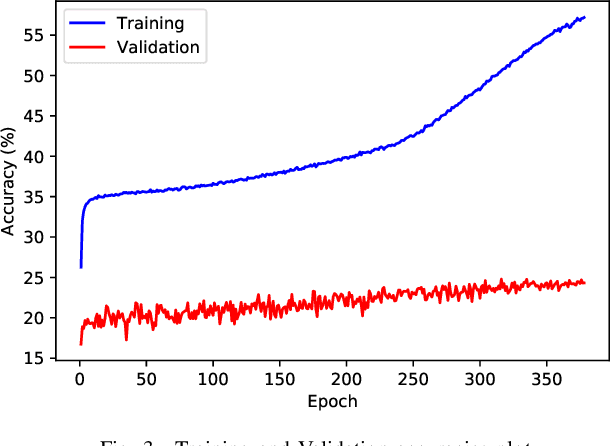
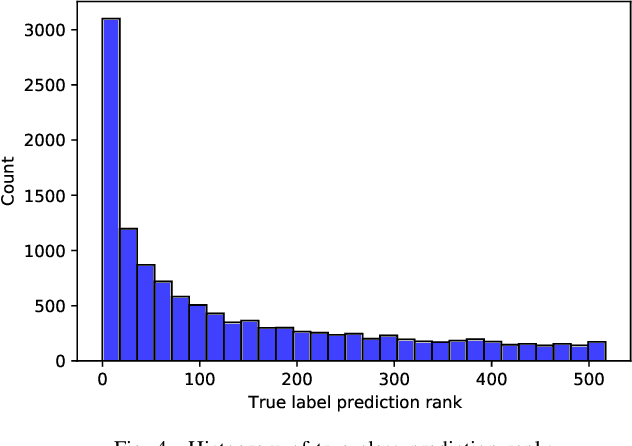
Lip-reading has made impressive progress in recent years, driven by advances in deep learning. Nonetheless, the prerequisite such advances is a suitable dataset. This paper provides a new in-the-wild dataset for Persian word-level lipreading containing 244,000 videos from approximately 1,800 speakers. We evaluated the state-of-the-art method in this field and used a novel approach for word-level lip-reading. In this method, we used the AV-HuBERT model for feature extraction and obtained significantly better performance on our dataset.
A Multi-Purpose Audio-Visual Corpus for Multi-Modal Persian Speech Recognition: the Arman-AV Dataset
Jan 21, 2023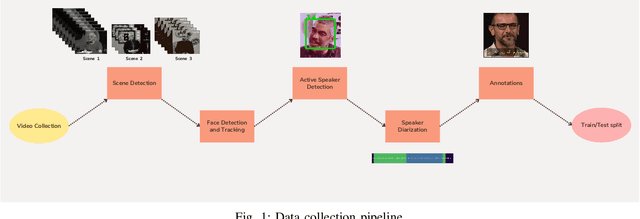

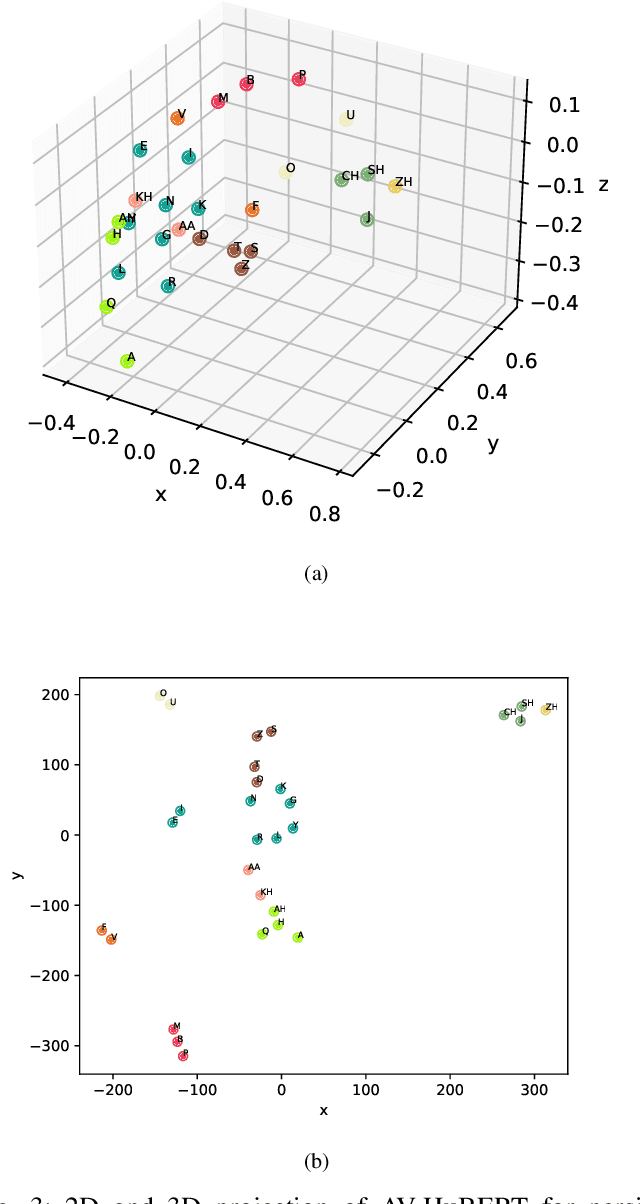
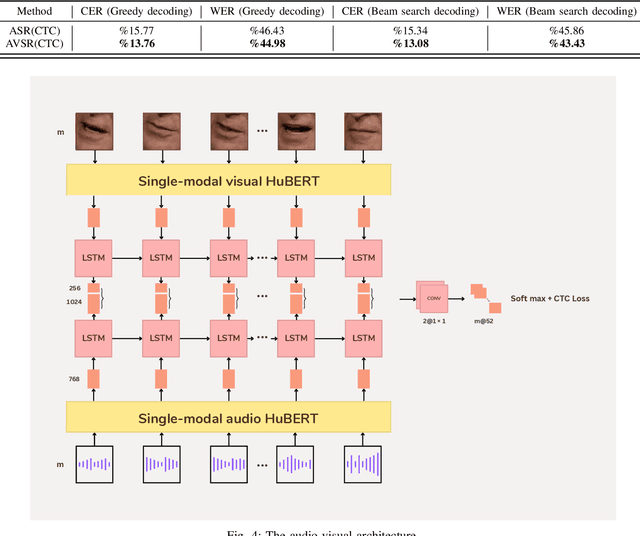
In recent years, significant progress has been made in automatic lip reading. But these methods require large-scale datasets that do not exist for many low-resource languages. In this paper, we have presented a new multipurpose audio-visual dataset for Persian. This dataset consists of almost 220 hours of videos with 1760 corresponding speakers. In addition to lip reading, the dataset is suitable for automatic speech recognition, audio-visual speech recognition, and speaker recognition. Also, it is the first large-scale lip reading dataset in Persian. A baseline method was provided for each mentioned task. In addition, we have proposed a technique to detect visemes (a visual equivalent of a phoneme) in Persian. The visemes obtained by this method increase the accuracy of the lip reading task by 7% relatively compared to the previously proposed visemes, which can be applied to other languages as well.
MAS2HP: A Multi Agent System to predict protein structure in 2D HP model
May 24, 2022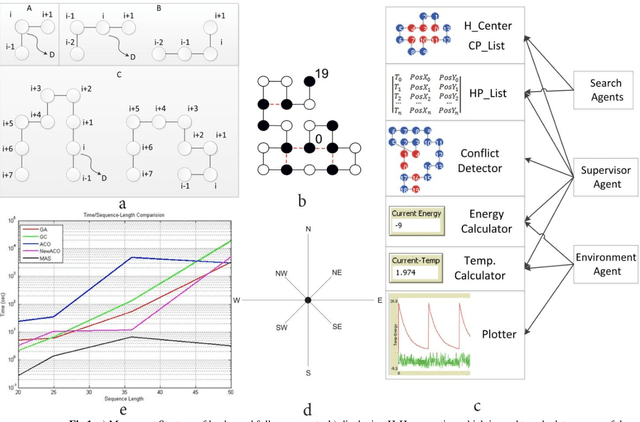
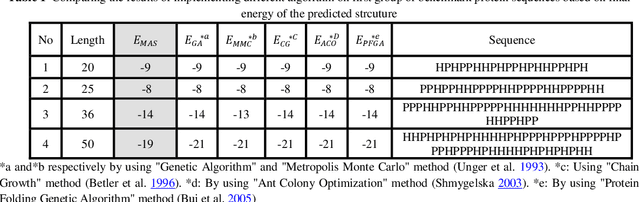
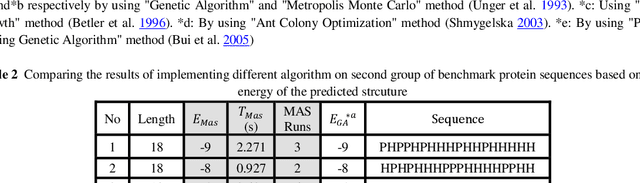
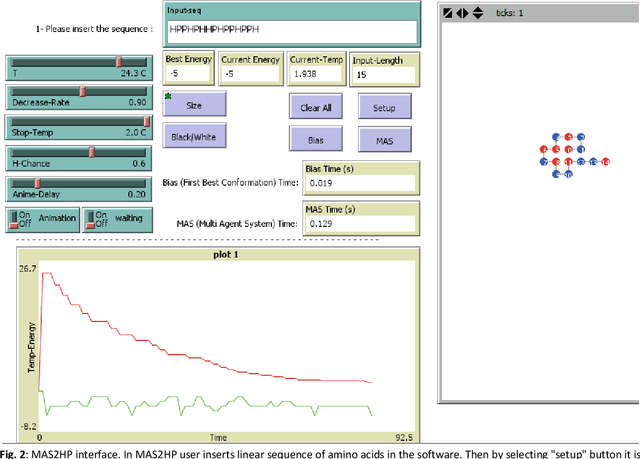
Protein Structure Prediction (PSP) is an unsolved problem in the field of computational biology. The problem of protein structure prediction is about predicting the native conformation of a protein, while its sequence of amino acids is known. Regarding processing limitations of current computer systems, all-atom simulations for proteins are typically unpractical; several reduced models of proteins have been proposed. Additionally, due to intrinsic hardness of calculations even in reduced models, many computational methods mainly based on artificial intelligence have been proposed to solve the problem. Agent-based modeling is a relatively new method for modeling systems composed of interacting items. In this paper we proposed a new approach for protein structure prediction by using agent-based modeling (ABM) in two dimensional hydrophobic-hydrophilic model. We broke the whole process of protein structure prediction into two steps: the first step, which was introduced in our previous paper, is about biasing the linear sequence to gain a primary energy, and the next step, which will be explained in this paper, is about using ABM with a predefined set of rules, to find the best conformation in the least possible amount of time and steps. This method was implemented in NETLOGO. We have tested this algorithm on several benchmark sequences ranging from 20 to 50-mers in two dimensional Hydrophobic-Hydrophilic lattice models. Comparing to the result of the other algorithms, our method is capable of finding the best known conformations in a significantly shorter time. A major problem in PSP simulation is that as the sequence length increases the time consumed to predict a valid structure will exponentially increase. In contrast, by using MAS2HP the effect of increase in sequence length on spent time has changed from exponentially to linear.
Lip reading using external viseme decoding
Apr 10, 2021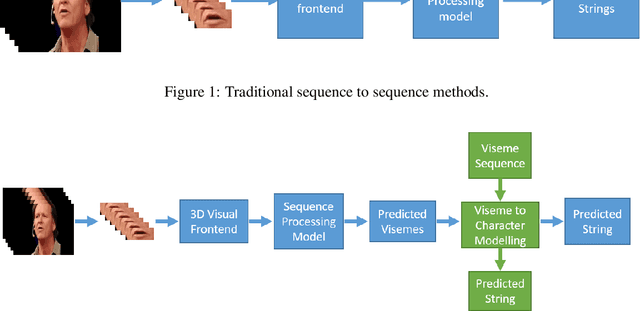


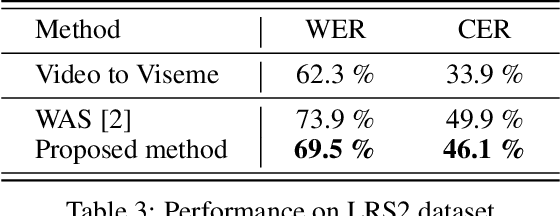
Lip-reading is the operation of recognizing speech from lip movements. This is a difficult task because the movements of the lips when pronouncing the words are similar for some of them. Viseme is used to describe lip movements during a conversation. This paper aims to show how to use external text data (for viseme-to-character mapping) by dividing video-to-character into two stages, namely converting video to viseme, and then converting viseme to character by using separate models. Our proposed method improves word error rate by 4\% compared to the normal sequence to sequence lip-reading model on the BBC-Oxford Lip Reading Sentences 2 (LRS2) dataset.
A new Potential-Based Reward Shaping for Reinforcement Learning Agent
Feb 17, 2019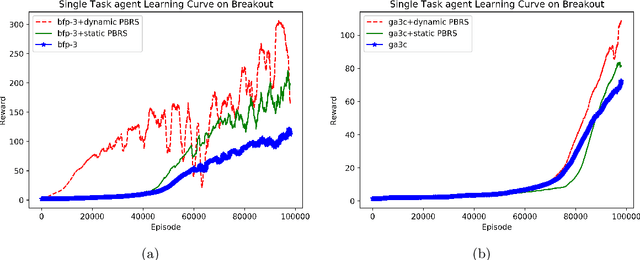
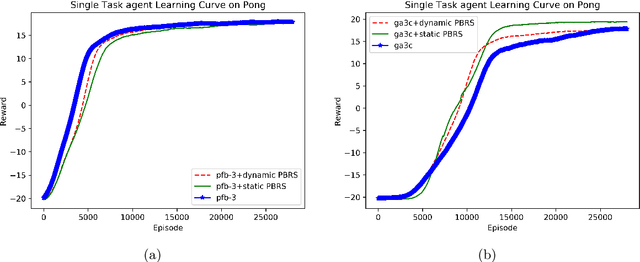

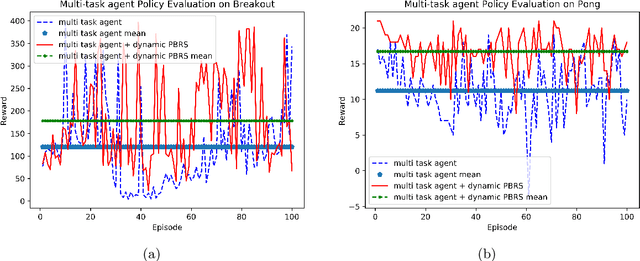
Potential-based reward shaping (PBRS) is a particular category of machine learning methods which aims to improve the learning speed of a reinforcement learning agent by extracting and utilizing extra knowledge while performing a task. There are two steps in the process of transfer learning: extracting knowledge from previously learned tasks and transferring that knowledge to use it in a target task. The latter step is well discussed in the literature with various methods being proposed for it, while the former has been explored less. With this in mind, the type of knowledge that is transmitted is very important and can lead to considerable improvement. Among the literature of both the transfer learning and the potential-based reward shaping, a subject that has never been addressed is the knowledge gathered during the learning process itself. In this paper, we presented a novel potential-based reward shaping method that attempted to extract knowledge from the learning process. The proposed method extracts knowledge from episodes' cumulative rewards. The proposed method has been evaluated in the Arcade learning environment and the results indicate an improvement in the learning process in both the single-task and the multi-task reinforcement learner agents.
Learning to predict where to look in interactive environments using deep recurrent q-learning
Feb 18, 2017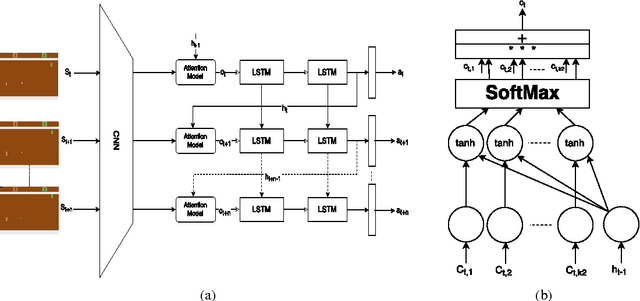
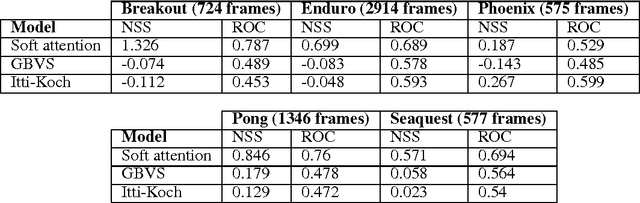


Bottom-Up (BU) saliency models do not perform well in complex interactive environments where humans are actively engaged in tasks (e.g., sandwich making and playing the video games). In this paper, we leverage Reinforcement Learning (RL) to highlight task-relevant locations of input frames. We propose a soft attention mechanism combined with the Deep Q-Network (DQN) model to teach an RL agent how to play a game and where to look by focusing on the most pertinent parts of its visual input. Our evaluations on several Atari 2600 games show that the soft attention based model could predict fixation locations significantly better than bottom-up models such as Itti-Kochs saliency and Graph-Based Visual Saliency (GBVS) models.