Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLip reading using external viseme decoding
Paper and Code
Apr 10, 2021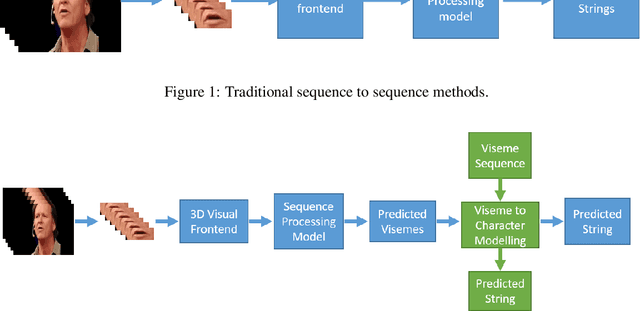


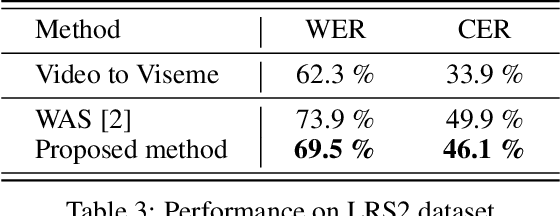
Lip-reading is the operation of recognizing speech from lip movements. This is a difficult task because the movements of the lips when pronouncing the words are similar for some of them. Viseme is used to describe lip movements during a conversation. This paper aims to show how to use external text data (for viseme-to-character mapping) by dividing video-to-character into two stages, namely converting video to viseme, and then converting viseme to character by using separate models. Our proposed method improves word error rate by 4\% compared to the normal sequence to sequence lip-reading model on the BBC-Oxford Lip Reading Sentences 2 (LRS2) dataset.
View paper on