 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIUST_PersonReId: A New Domain in Person Re-Identification Datasets
Dec 25, 2024



Person re-identification (ReID) models often struggle to generalize across diverse cultural contexts, particularly in Islamic regions like Iran, where modest clothing styles are prevalent. Existing datasets predominantly feature Western and East Asian fashion, limiting their applicability in these settings. To address this gap, we introduce IUST_PersonReId, a dataset designed to reflect the unique challenges of ReID in new cultural environments, emphasizing modest attire and diverse scenarios from Iran, including markets, campuses, and mosques. Experiments on IUST_PersonReId with state-of-the-art models, such as Solider and CLIP-ReID, reveal significant performance drops compared to benchmarks like Market1501 and MSMT17, highlighting the challenges posed by occlusion and limited distinctive features. Sequence-based evaluations show improvements by leveraging temporal context, emphasizing the dataset's potential for advancing culturally sensitive and robust ReID systems. IUST_PersonReId offers a critical resource for addressing fairness and bias in ReID research globally. The dataset is publicly available at https://computervisioniust.github.io/IUST_PersonReId/.
Feature Based Methods Domain Adaptation for Object Detection: A Review Paper
Dec 23, 2024



Domain adaptation, a pivotal branch of transfer learning, aims to enhance the performance of machine learning models when deployed in target domains with distinct data distributions. This is particularly critical for object detection tasks, where domain shifts (caused by factors such as lighting conditions, viewing angles, and environmental variations) can lead to significant performance degradation. This review delves into advanced methodologies for domain adaptation, including adversarial learning, discrepancy-based, multi-domain, teacher-student, ensemble, and VLM techniques, emphasizing their efficacy in reducing domain gaps and enhancing model robustness. Feature-based methods have emerged as powerful tools for addressing these challenges by harmonizing feature representations across domains. These techniques, such as Feature Alignment, Feature Augmentation/Reconstruction, and Feature Transformation, are employed alongside or as integral parts of other domain adaptation strategies to minimize domain gaps and improve model performance. Special attention is given to strategies that minimize the reliance on extensive labeled data and using unlabeled data, particularly in scenarios involving synthetic-to-real domain shifts. Applications in fields such as autonomous driving and medical imaging are explored, showcasing the potential of these methods to ensure reliable object detection in diverse and complex settings. By providing a thorough analysis of state-of-the-art techniques, challenges, and future directions, this work offers a valuable reference for researchers striving to develop resilient and adaptable object detection frameworks, advancing the seamless deployment of artificial intelligence in dynamic environments.
MSDNet: Multi-Scale Decoder for Few-Shot Semantic Segmentation via Transformer-Guided Prototyping
Sep 17, 2024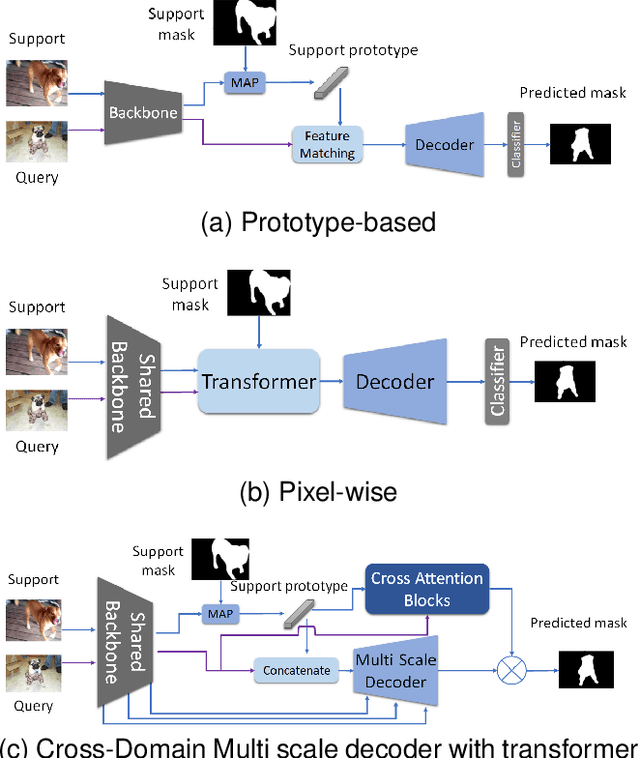
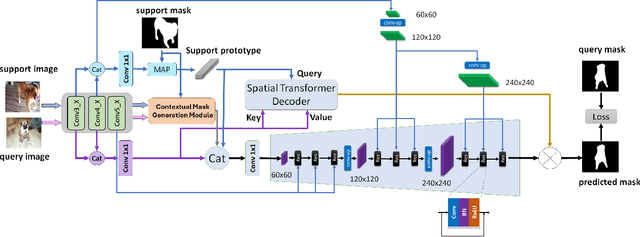
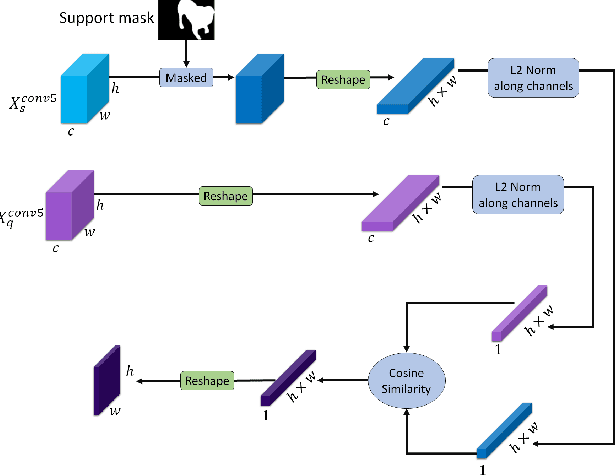
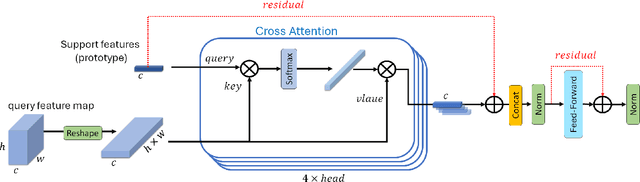
Few-shot Semantic Segmentation addresses the challenge of segmenting objects in query images with only a handful of annotated examples. However, many previous state-of-the-art methods either have to discard intricate local semantic features or suffer from high computational complexity. To address these challenges, we propose a new Few-shot Semantic Segmentation framework based on the transformer architecture. Our approach introduces the spatial transformer decoder and the contextual mask generation module to improve the relational understanding between support and query images. Moreover, we introduce a multi-scale decoder to refine the segmentation mask by incorporating features from different resolutions in a hierarchical manner. Additionally, our approach integrates global features from intermediate encoder stages to improve contextual understanding, while maintaining a lightweight structure to reduce complexity. This balance between performance and efficiency enables our method to achieve state-of-the-art results on benchmark datasets such as $PASCAL-5^i$ and $COCO-20^i$ in both 1-shot and 5-shot settings. Notably, our model with only 1.5 million parameters demonstrates competitive performance while overcoming limitations of existing methodologies. https://github.com/amirrezafateh/MSDNet
Enhancing Few-Shot Image Classification through Learnable Multi-Scale Embedding and Attention Mechanisms
Sep 12, 2024
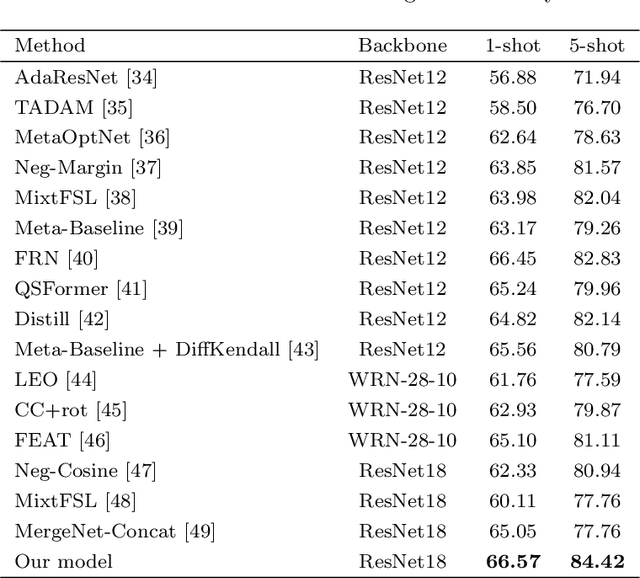
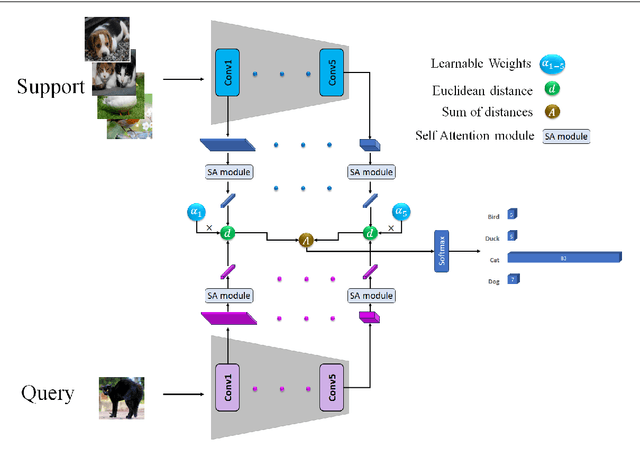
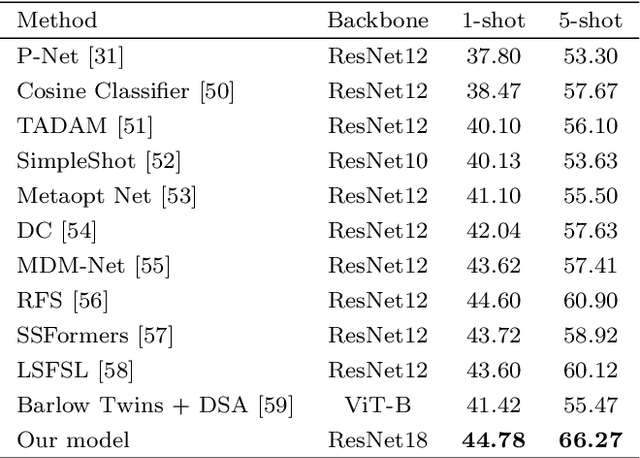
In the context of few-shot classification, the goal is to train a classifier using a limited number of samples while maintaining satisfactory performance. However, traditional metric-based methods exhibit certain limitations in achieving this objective. These methods typically rely on a single distance value between the query feature and support feature, thereby overlooking the contribution of shallow features. To overcome this challenge, we propose a novel approach in this paper. Our approach involves utilizing multi-output embedding network that maps samples into distinct feature spaces. The proposed method extract feature vectors at different stages, enabling the model to capture both global and abstract features. By utilizing these diverse feature spaces, our model enhances its performance. Moreover, employing a self-attention mechanism improves the refinement of features at each stage, leading to even more robust representations and improved overall performance. Furthermore, assigning learnable weights to each stage significantly improved performance and results. We conducted comprehensive evaluations on the MiniImageNet and FC100 datasets, specifically in the 5-way 1-shot and 5-way 5-shot scenarios. Additionally, we performed a cross-domain task from MiniImageNet to the CUB dataset, achieving high accuracy in the testing domain. These evaluations demonstrate the efficacy of our proposed method in comparison to state-of-the-art approaches. https://github.com/FatemehAskari/MSENet
End-to-End assessment of AR-assisted neurosurgery systems
Nov 03, 2023
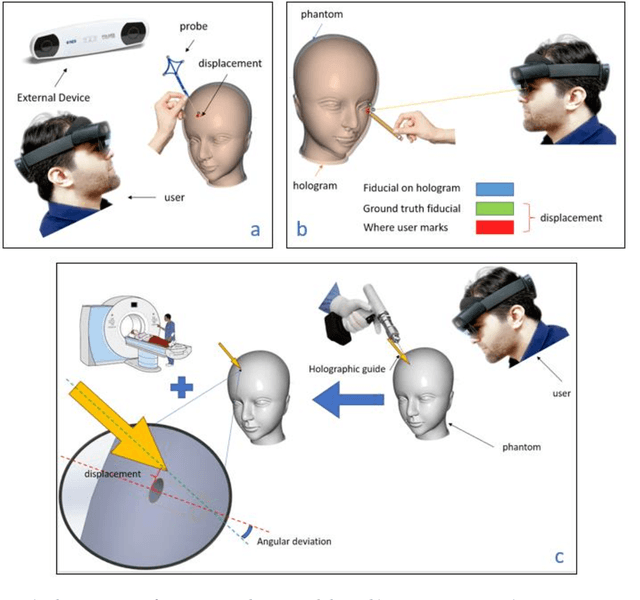

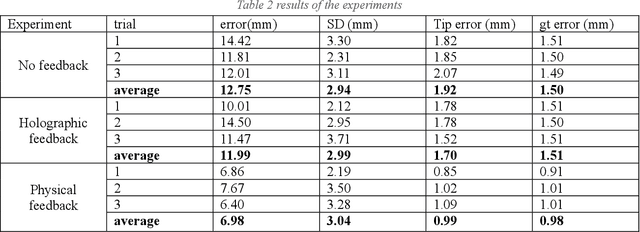
Augmented Reality (AR) has emerged as a significant advancement in surgical procedures, offering a solution to the challenges posed by traditional neuronavigation methods. These conventional techniques often necessitate surgeons to split their focus between the surgical site and a separate monitor that displays guiding images. Over the years, many systems have been developed to register and track the hologram at the targeted locations, each employed its own evaluation technique. On the other hand, hologram displacement measurement is not a straightforward task because of various factors such as occlusion, Vengence-Accomodation Conflict, and unstable holograms in space. In this study, we explore and classify different techniques for assessing an AR-assisted neurosurgery system and propose a new technique to systematize the assessment procedure. Moreover, we conduct a deeper investigation to assess surgeon error in the pre- and intra-operative phases of the surgery based on the respective feedback given. We found that although the system can undergo registration and tracking errors, physical feedback can significantly reduce the error caused by hologram displacement. However, the lack of visual feedback on the hologram does not have a significant effect on the user 3D perception.
Leveraging Visemes for Better Visual Speech Representation and Lip Reading
Jul 19, 2023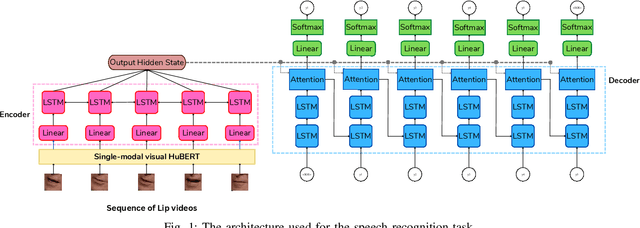
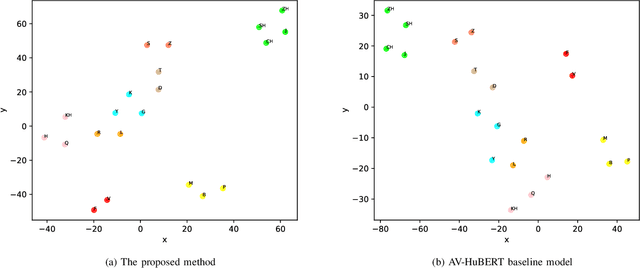
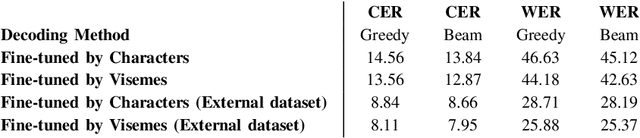
Lip reading is a challenging task that has many potential applications in speech recognition, human-computer interaction, and security systems. However, existing lip reading systems often suffer from low accuracy due to the limitations of video features. In this paper, we propose a novel approach that leverages visemes, which are groups of phonetically similar lip shapes, to extract more discriminative and robust video features for lip reading. We evaluate our approach on various tasks, including word-level and sentence-level lip reading, and audiovisual speech recognition using the Arman-AV dataset, a largescale Persian corpus. Our experimental results show that our viseme based approach consistently outperforms the state-of-theart methods in all these tasks. The proposed method reduces the lip-reading word error rate (WER) by 9.1% relative to the best previous method.
A Multi-Purpose Audio-Visual Corpus for Multi-Modal Persian Speech Recognition: the Arman-AV Dataset
Jan 21, 2023

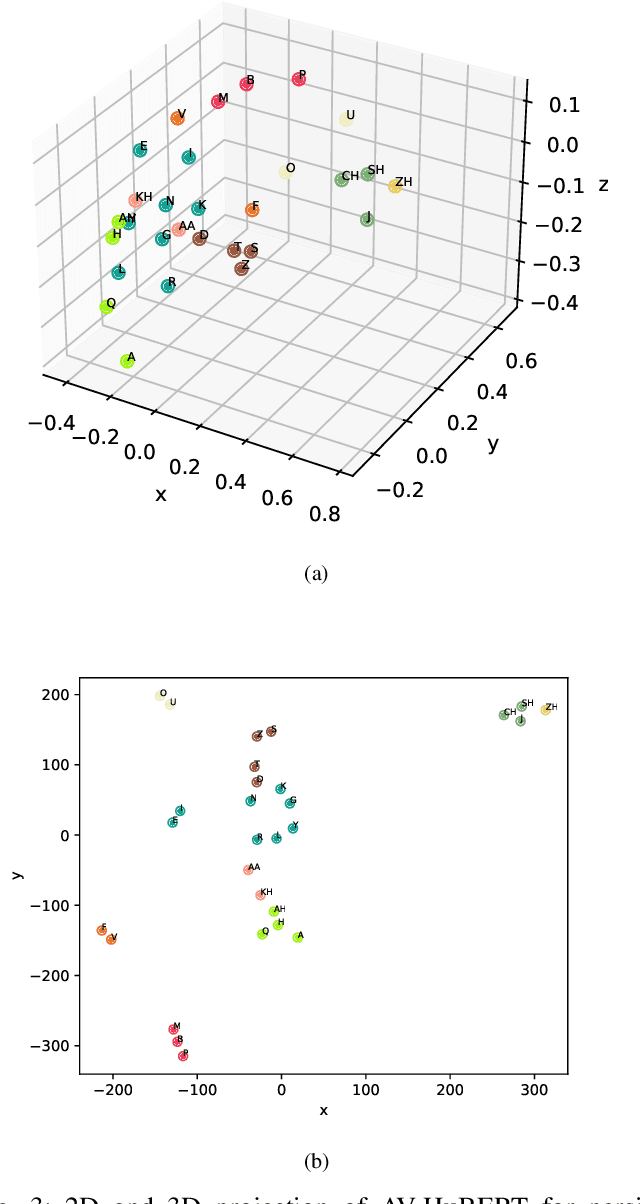
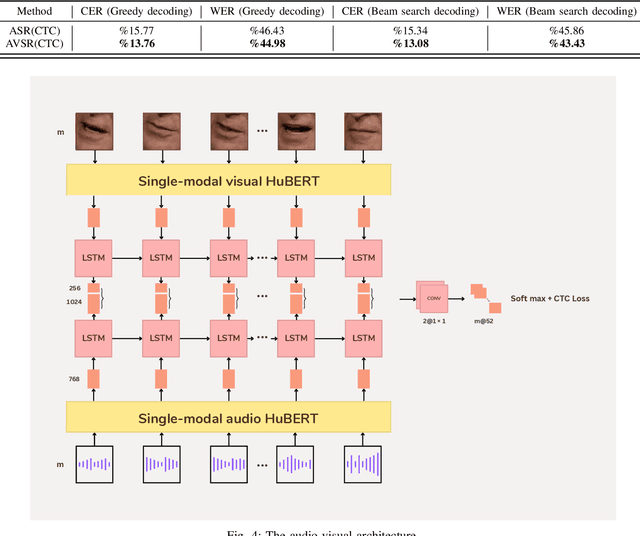
In recent years, significant progress has been made in automatic lip reading. But these methods require large-scale datasets that do not exist for many low-resource languages. In this paper, we have presented a new multipurpose audio-visual dataset for Persian. This dataset consists of almost 220 hours of videos with 1760 corresponding speakers. In addition to lip reading, the dataset is suitable for automatic speech recognition, audio-visual speech recognition, and speaker recognition. Also, it is the first large-scale lip reading dataset in Persian. A baseline method was provided for each mentioned task. In addition, we have proposed a technique to detect visemes (a visual equivalent of a phoneme) in Persian. The visemes obtained by this method increase the accuracy of the lip reading task by 7% relatively compared to the previously proposed visemes, which can be applied to other languages as well.
Wise-SrNet: A Novel Architecture for Enhancing Image Classification by Learning Spatial Resolution of Feature Maps
Apr 26, 2021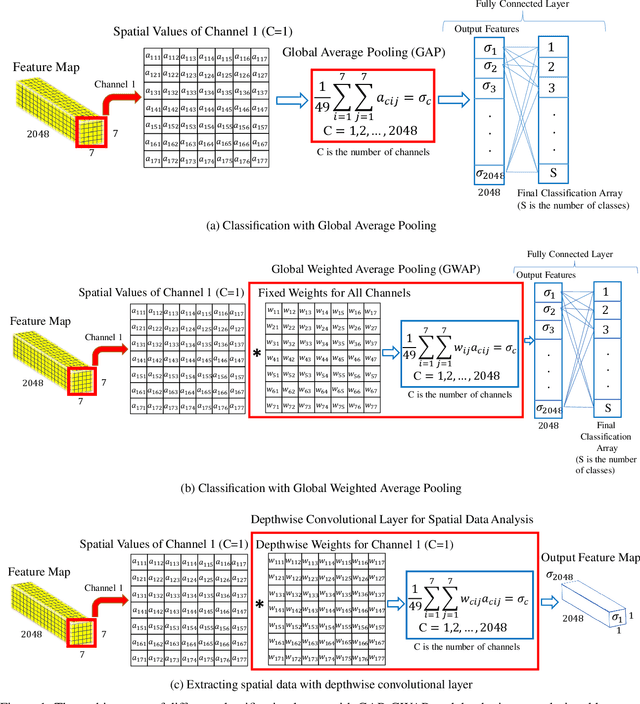
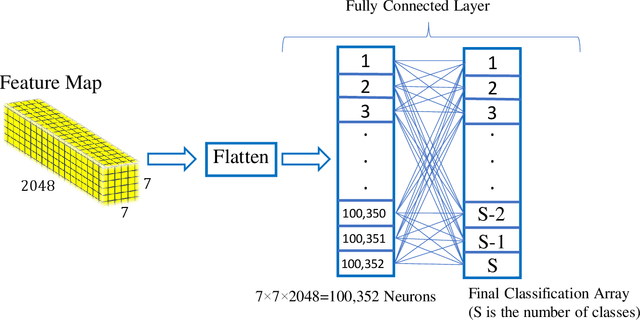

One of the main challenges since the advancement of convolutional neural networks is how to connect the extracted feature map to the final classification layer. VGG models used two sets of fully connected layers for the classification part of their architectures, which significantly increases the number of models' weights. ResNet and next deep convolutional models used the Global Average Pooling (GAP) layer to compress the feature map and feed it to the classification layer. Although using the GAP layer reduces the computational cost, but also causes losing spatial resolution of the feature map, which results in decreasing learning efficiency. In this paper, we aim to tackle this problem by replacing the GAP layer with a new architecture called Wise-SrNet. It is inspired by the depthwise convolutional idea and is designed for processing spatial resolution and also not increasing computational cost. We have evaluated our method using three different datasets: Intel Image Classification Challenge, MIT Indoors Scenes, and a part of the ImageNet dataset. We investigated the implementation of our architecture on several models of Inception, ResNet and DensNet families. Applying our architecture has revealed a significant effect on increasing convergence speed and accuracy. Our Experiments on images with 224x224 resolution increased the Top-1 accuracy between 2% to 8% on different datasets and models. Running our models on 512x512 resolution images of the MIT Indoors Scenes dataset showed a notable result of improving the Top-1 accuracy within 3% to 26%. We will also demonstrate the GAP layer's disadvantage when the input images are large and the number of classes is not few. In this circumstance, our proposed architecture can do a great help in enhancing classification results. The code is shared at https://github.com/mr7495/image-classification-spatial.
Lip reading using external viseme decoding
Apr 10, 2021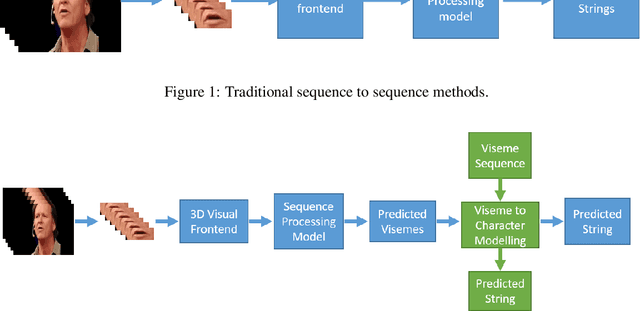


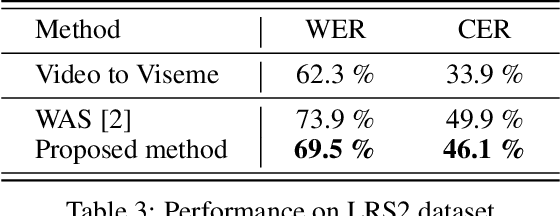
Lip-reading is the operation of recognizing speech from lip movements. This is a difficult task because the movements of the lips when pronouncing the words are similar for some of them. Viseme is used to describe lip movements during a conversation. This paper aims to show how to use external text data (for viseme-to-character mapping) by dividing video-to-character into two stages, namely converting video to viseme, and then converting viseme to character by using separate models. Our proposed method improves word error rate by 4\% compared to the normal sequence to sequence lip-reading model on the BBC-Oxford Lip Reading Sentences 2 (LRS2) dataset.
Cloud removal in remote sensing images using generative adversarial networks and SAR-to-optical image translation
Dec 22, 2020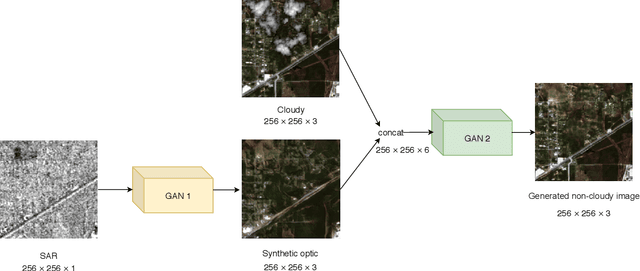
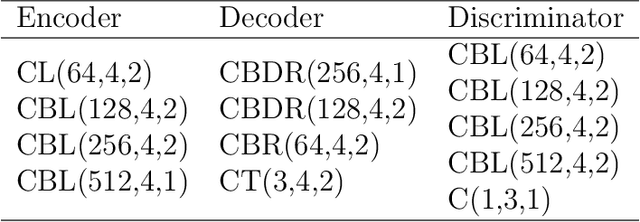

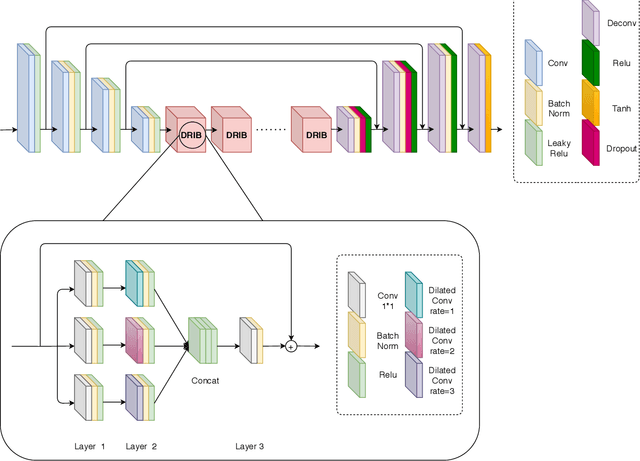
Satellite images are often contaminated by clouds. Cloud removal has received much attention due to the wide range of satellite image applications. As the clouds thicken, the process of removing the clouds becomes more challenging. In such cases, using auxiliary images such as near-infrared or synthetic aperture radar (SAR) for reconstructing is common. In this study, we attempt to solve the problem using two generative adversarial networks (GANs). The first translates SAR images into optical images, and the second removes clouds using the translated images of prior GAN. Also, we propose dilated residual inception blocks (DRIBs) instead of vanilla U-net in the generator networks and use structural similarity index measure (SSIM) in addition to the L1 Loss function. Reducing the number of downsamplings and expanding receptive fields by dilated convolutions increase the quality of output images. We used the SEN1-2 dataset to train and test both GANs, and we made cloudy images by adding synthetic clouds to optical images. The restored images are evaluated with PSNR and SSIM. We compare the proposed method with state-of-the-art deep learning models and achieve more accurate results in both SAR-to-optical translation and cloud removal parts.