 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Gasoline Consumption Forecasting: A Novel Hybrid Model Integrating Transformers, LSTM, and CNN
Oct 20, 2024



Iran, endowed with abundant hydrocarbon resources, plays a crucial role in the global energy landscape. Gasoline, as a critical fuel, significantly supports the nation's transportation sector. Accurate forecasting of gasoline consumption is essential for strategic resource management and environmental planning. This research introduces a novel approach to predicting monthly gasoline consumption using a hybrid Transformer-LSTM-CNN model, which integrates the strengths of Transformer networks, Long Short-Term Memory (LSTM) networks, and Convolutional Neural Networks (CNN). This advanced architecture offers a superior alternative to conventional methods such as artificial neural networks and regression models by capturing both short- and long-term dependencies in time series data. By leveraging the self-attention mechanism of Transformers, the temporal memory of LSTMs, and the local pattern detection of CNNs, our hybrid model delivers improved prediction accuracy. Implemented using Python, the model provides precise future gasoline consumption forecasts and evaluates the environmental impact through the analysis of greenhouse gas emissions. This study examines gasoline consumption trends from 2007 to 2021, which rose from 64.5 million liters per day in 2007 to 99.80 million liters per day in 2021. Our proposed model forecasts consumption levels up to 2031, offering a valuable tool for policymakers and energy analysts. The results highlight the superiority of this hybrid model in improving the accuracy of gasoline consumption forecasts, reinforcing the need for advanced machine learning techniques to optimize resource management and mitigate environmental risks in the energy sector.
ROCT-Net: A new ensemble deep convolutional model with improved spatial resolution learning for detecting common diseases from retinal OCT images
Mar 03, 2022



Optical coherence tomography (OCT) imaging is a well-known technology for visualizing retinal layers and helps ophthalmologists to detect possible diseases. Accurate and early diagnosis of common retinal diseases can prevent the patients from suffering critical damages to their vision. Computer-aided diagnosis (CAD) systems can significantly assist ophthalmologists in improving their examinations. This paper presents a new enhanced deep ensemble convolutional neural network for detecting retinal diseases from OCT images. Our model generates rich and multi-resolution features by employing the learning architectures of two robust convolutional models. Spatial resolution is a critical factor in medical images, especially the OCT images that contain tiny essential points. To empower our model, we apply a new post-architecture model to our ensemble model for enhancing spatial resolution learning without increasing computational costs. The introduced post-architecture model can be deployed to any feature extraction model to improve the utilization of the feature map's spatial values. We have collected two open-source datasets for our experiments to make our models capable of detecting six crucial retinal diseases: Age-related Macular Degeneration (AMD), Central Serous Retinopathy (CSR), Diabetic Retinopathy (DR), Choroidal Neovascularization (CNV), Diabetic Macular Edema (DME), and Drusen alongside the normal cases. Our experiments on two datasets and comparing our model with some other well-known deep convolutional neural networks have proven that our architecture can increase the classification accuracy up to 5%. We hope that our proposed methods create the next step of CAD systems development and help future researches. The code of this paper is shared at https://github.com/mr7495/OCT-classification.
Wise-SrNet: A Novel Architecture for Enhancing Image Classification by Learning Spatial Resolution of Feature Maps
Apr 26, 2021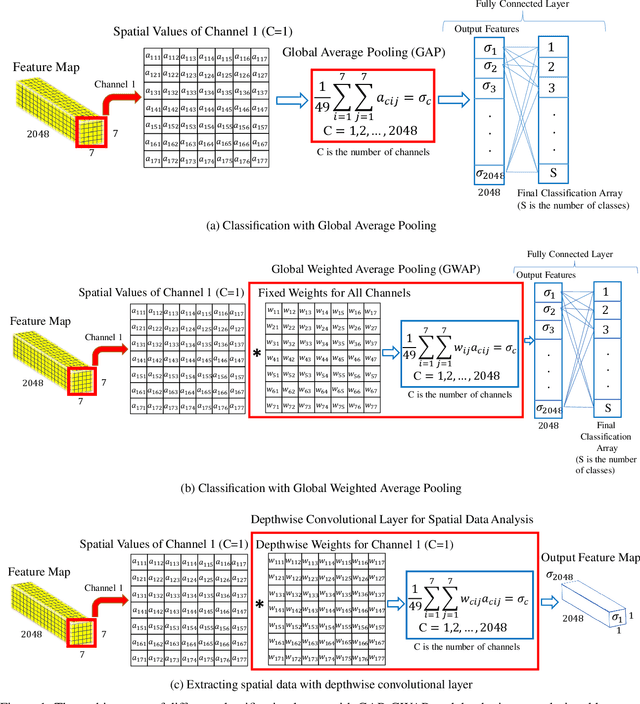
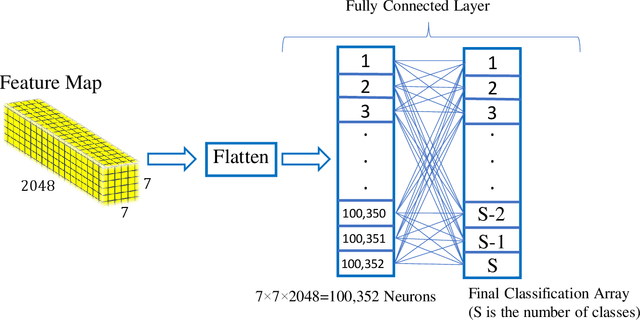

One of the main challenges since the advancement of convolutional neural networks is how to connect the extracted feature map to the final classification layer. VGG models used two sets of fully connected layers for the classification part of their architectures, which significantly increases the number of models' weights. ResNet and next deep convolutional models used the Global Average Pooling (GAP) layer to compress the feature map and feed it to the classification layer. Although using the GAP layer reduces the computational cost, but also causes losing spatial resolution of the feature map, which results in decreasing learning efficiency. In this paper, we aim to tackle this problem by replacing the GAP layer with a new architecture called Wise-SrNet. It is inspired by the depthwise convolutional idea and is designed for processing spatial resolution and also not increasing computational cost. We have evaluated our method using three different datasets: Intel Image Classification Challenge, MIT Indoors Scenes, and a part of the ImageNet dataset. We investigated the implementation of our architecture on several models of Inception, ResNet and DensNet families. Applying our architecture has revealed a significant effect on increasing convergence speed and accuracy. Our Experiments on images with 224x224 resolution increased the Top-1 accuracy between 2% to 8% on different datasets and models. Running our models on 512x512 resolution images of the MIT Indoors Scenes dataset showed a notable result of improving the Top-1 accuracy within 3% to 26%. We will also demonstrate the GAP layer's disadvantage when the input images are large and the number of classes is not few. In this circumstance, our proposed architecture can do a great help in enhancing classification results. The code is shared at https://github.com/mr7495/image-classification-spatial.
Introduction of a new Dataset and Method for Detecting and Counting the Pistachios based on Deep Learning
May 08, 2020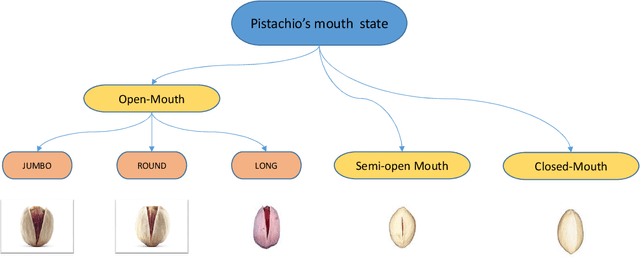

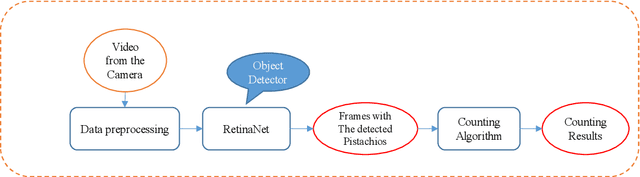
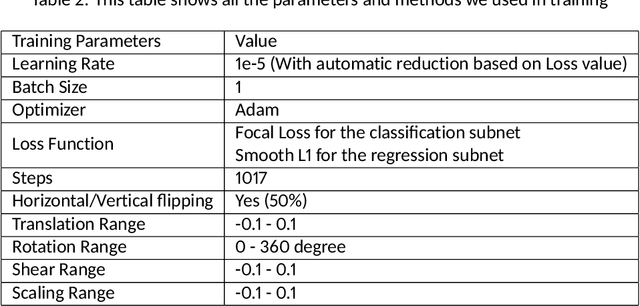
Pistachio is a nutritious nut that has many uses in the food industry. Iran is one of its largest producers, and pistachio is considered as a strategic export product for this country. Pistachios are sorted based on the shape of their shell into two categories: Open-mouth and Closed-mouth. The open-mouth pistachios are higher in price, value, and demand than the closed-mouth pistachios. In the countries that are famous in pistachio production and exporting, there are companies that pack the picked pistachios from the trees and make them ready for exporting. As there are differences between the price and the demand of the open-mouth and closed-mouth pistachios, it is considerable for these companies to know precisely how much of these two kinds of pistachios exist in each packed package. In this paper, we have introduced and shared a new dataset of pistachios, which is called Pesteh-Set. Pesteh-Set includes 6 videos with a total length of 164 seconds and 561 moving pistachios. It also contains 423 labeled images that totally include 3927 labeled pistachios. At the first stage, we have used RetinaNet, the deep fully convolutional object detector for detecting the pistachios in the video frames. In the second stage, we introduce our method for counting the open-mouth and closed-mouth pistachios in the videos. Pistachios that move and roll on the transportation line may appear as closed-mouth in some frames and as open-mouth in other frames. With this circumstance, the main challenge of our work is to count these two kinds of pistachios correctly and fast. Our introduced method performs very fast with no need for GPU, and it also achieves good counting results. The computed accuracy of our counting method is 94.75%. Our proposed methods can be remotely performed by using the videos taken from the implemented cameras that could monitor the pistachios.
A New Modified Deep Convolutional Neural Network for Detecting COVID-19 from X-ray Images
Apr 17, 2020
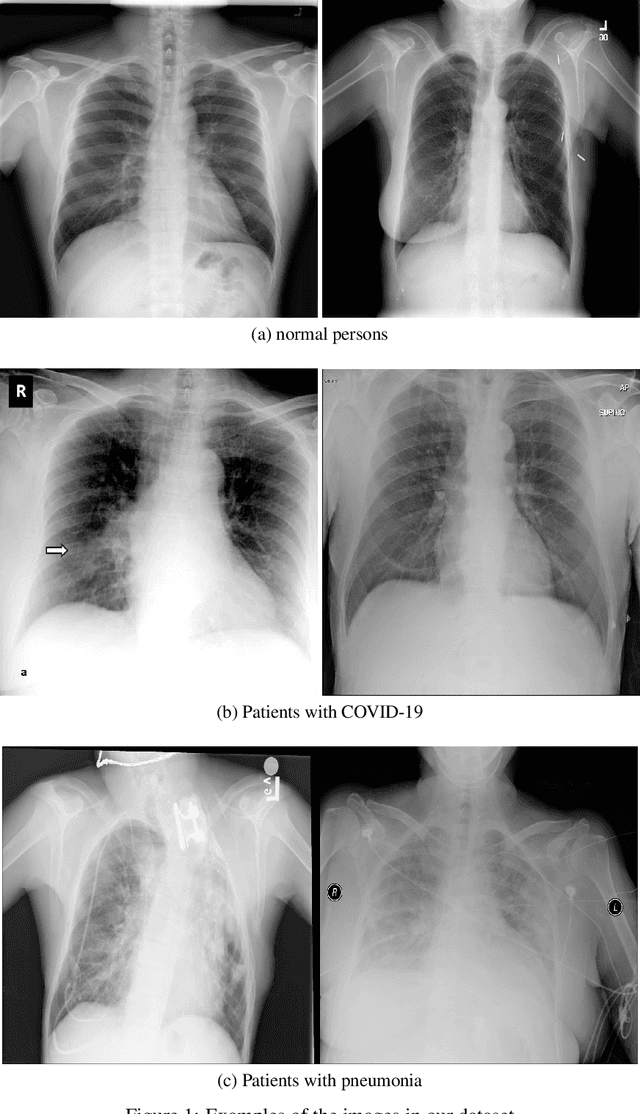
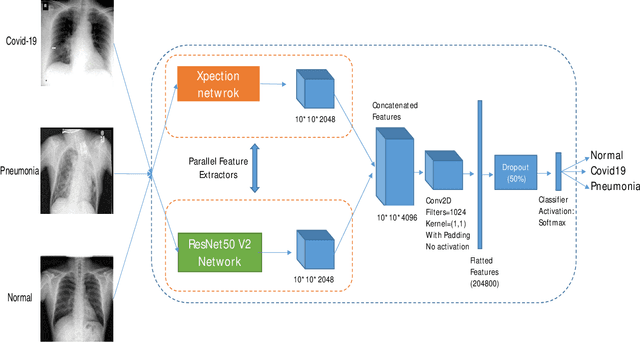

COVID-19 has become a serious health problem all around the world. It is confirmed that this virus has taken over 126,607 lives until today. Since the beginning of its spreading, many Artificial Intelligence researchers developed systems and methods for predicting the virus's behavior or detecting the infection. One of the possible ways of determining the patient infection to COVID-19 is through analyzing the chest X-ray images. As there are a large number of patients in hospitals, it would be time-consuming and difficult to examine lots of X-ray images, so it can be very useful to develop an AI network that does this job automatically. In this paper, we have trained several deep convolutional networks with the introduced training techniques for classifying X-ray images into three classes: normal, pneumonia, and COVID-19, based on two open-source datasets. Unfortunately, most of the previous works on this subject have not shared their dataset, and we had to deal with few data on covid19 cases. Our data contains 180 X-ray images that belong to persons infected to COVID-19, so we tried to apply methods to achieve the best possible results. In this research, we introduce some training techniques that help the network learn better when we have few cases of COVID-19, and also we propose a neural network that is a concatenation of Xception and ResNet50V2 networks. This network achieved the best accuracy by utilizing multiple features extracted by two robust networks. In this paper, despite some other researches, we have tested our network on 11302 images to report the actual accuracy our network can achieve in real circumstances. The average accuracy of the proposed network for detecting COVID-19 cases is 99.56%, and the overall average accuracy for all classes is 91.4%.
Sperm Detection and Tracking in Phase-Contrast Microscopy Image Sequences using Deep Learning and Modified CSR-DCF
Feb 19, 2020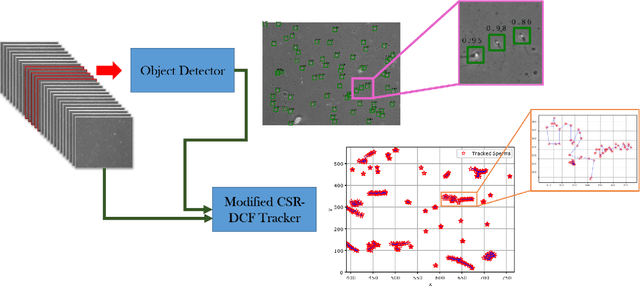


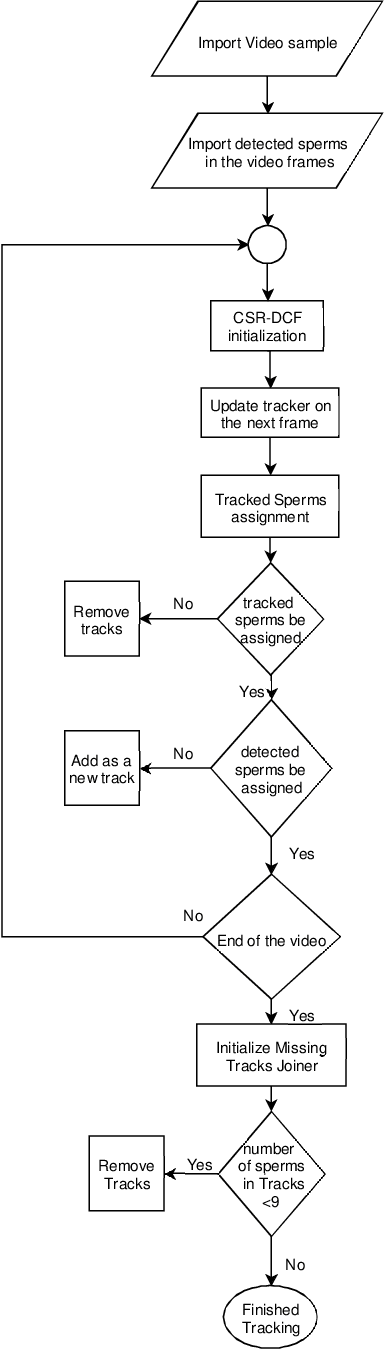
Nowadays, computer-aided sperm analysis (CASA) systems have made a big leap in extracting the characteristics of spermatozoa for studies or measuring human fertility. The first step in sperm characteristics analysis is sperm detection in the frames of the video sample. In this article, we used a deep fully convolutional network, as the object detector. Sperms are small objects with few attributes, that makes the detection more difficult in high-density samples and especially when there are other particles in semen, which could be like sperm heads. One of the main attributes of sperms is their movement, but this attribute cannot be extracted when only one frame would be fed to the network. To improve the performance of the sperm detection network, we concatenated some consecutive frames to use as the input of the network. With this method, the motility attribute has also been extracted, and then with the help of deep convolutional layers, we have achieved high accuracy in sperm detection. In the tracking phase, we modify the CSR-DCF algorithm. This method also has shown excellent results in sperm tracking even in high-density sperm samples, occlusions, sperm colliding, and when sperms exit from a frame and re-enter in the next frames. The average precision of the detection phase is 99.1%, and the F1 score of the tracking method evaluation is 96.46%. These results can be a great help in studies investigating sperm behavior and analyzing fertility possibility.