 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWise-SrNet: A Novel Architecture for Enhancing Image Classification by Learning Spatial Resolution of Feature Maps
Apr 26, 2021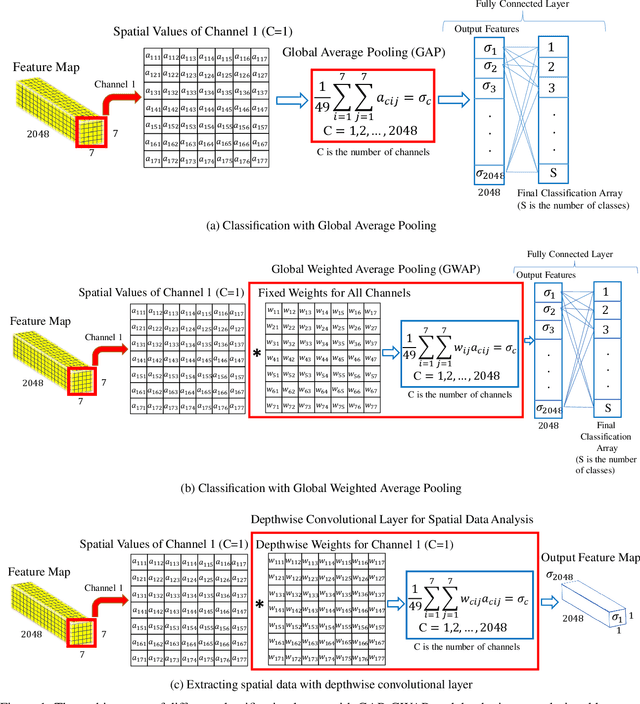
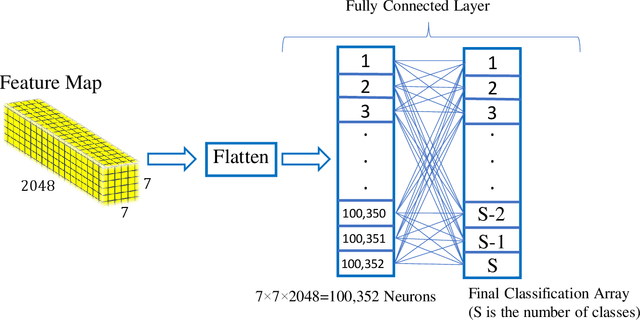

One of the main challenges since the advancement of convolutional neural networks is how to connect the extracted feature map to the final classification layer. VGG models used two sets of fully connected layers for the classification part of their architectures, which significantly increases the number of models' weights. ResNet and next deep convolutional models used the Global Average Pooling (GAP) layer to compress the feature map and feed it to the classification layer. Although using the GAP layer reduces the computational cost, but also causes losing spatial resolution of the feature map, which results in decreasing learning efficiency. In this paper, we aim to tackle this problem by replacing the GAP layer with a new architecture called Wise-SrNet. It is inspired by the depthwise convolutional idea and is designed for processing spatial resolution and also not increasing computational cost. We have evaluated our method using three different datasets: Intel Image Classification Challenge, MIT Indoors Scenes, and a part of the ImageNet dataset. We investigated the implementation of our architecture on several models of Inception, ResNet and DensNet families. Applying our architecture has revealed a significant effect on increasing convergence speed and accuracy. Our Experiments on images with 224x224 resolution increased the Top-1 accuracy between 2% to 8% on different datasets and models. Running our models on 512x512 resolution images of the MIT Indoors Scenes dataset showed a notable result of improving the Top-1 accuracy within 3% to 26%. We will also demonstrate the GAP layer's disadvantage when the input images are large and the number of classes is not few. In this circumstance, our proposed architecture can do a great help in enhancing classification results. The code is shared at https://github.com/mr7495/image-classification-spatial.