 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIUST_PersonReId: A New Domain in Person Re-Identification Datasets
Dec 25, 2024



Person re-identification (ReID) models often struggle to generalize across diverse cultural contexts, particularly in Islamic regions like Iran, where modest clothing styles are prevalent. Existing datasets predominantly feature Western and East Asian fashion, limiting their applicability in these settings. To address this gap, we introduce IUST_PersonReId, a dataset designed to reflect the unique challenges of ReID in new cultural environments, emphasizing modest attire and diverse scenarios from Iran, including markets, campuses, and mosques. Experiments on IUST_PersonReId with state-of-the-art models, such as Solider and CLIP-ReID, reveal significant performance drops compared to benchmarks like Market1501 and MSMT17, highlighting the challenges posed by occlusion and limited distinctive features. Sequence-based evaluations show improvements by leveraging temporal context, emphasizing the dataset's potential for advancing culturally sensitive and robust ReID systems. IUST_PersonReId offers a critical resource for addressing fairness and bias in ReID research globally. The dataset is publicly available at https://computervisioniust.github.io/IUST_PersonReId/.
ProAPT: Projection of APT Threats with Deep Reinforcement Learning
Sep 15, 2022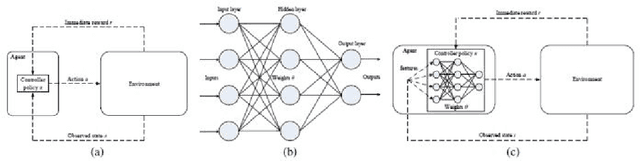
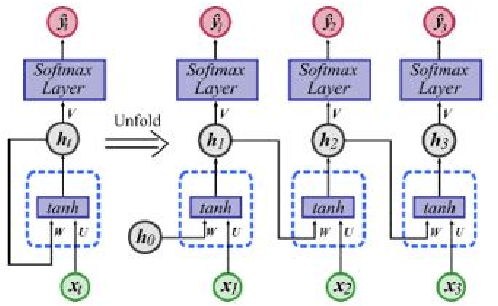
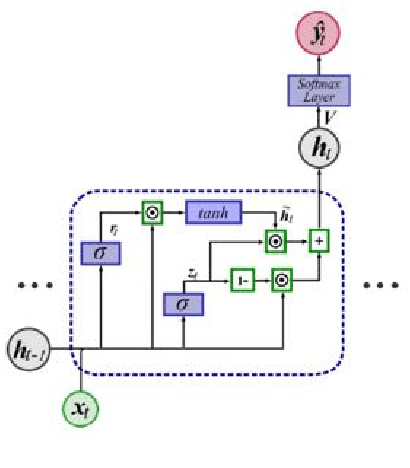
The highest level in the Endsley situation awareness model is called projection when the status of elements in the environment in the near future is predicted. In cybersecurity situation awareness, the projection for an Advanced Persistent Threat (APT) requires predicting the next step of the APT. The threats are constantly changing and becoming more complex. As supervised and unsupervised learning methods require APT datasets for projecting the next step of APTs, they are unable to identify unknown APT threats. In reinforcement learning methods, the agent interacts with the environment, and so it might project the next step of known and unknown APTs. So far, reinforcement learning has not been used to project the next step for APTs. In reinforcement learning, the agent uses the previous states and actions to approximate the best action of the current state. When the number of states and actions is abundant, the agent employs a neural network which is called deep learning to approximate the best action of each state. In this paper, we present a deep reinforcement learning system to project the next step of APTs. As there exists some relation between attack steps, we employ the Long- Short-Term Memory (LSTM) method to approximate the best action of each state. In our proposed system, based on the current situation, we project the next steps of APT threats.