 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord-level Persian Lipreading Dataset
Apr 08, 2023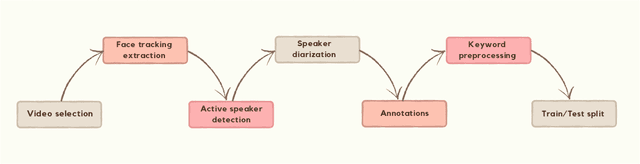

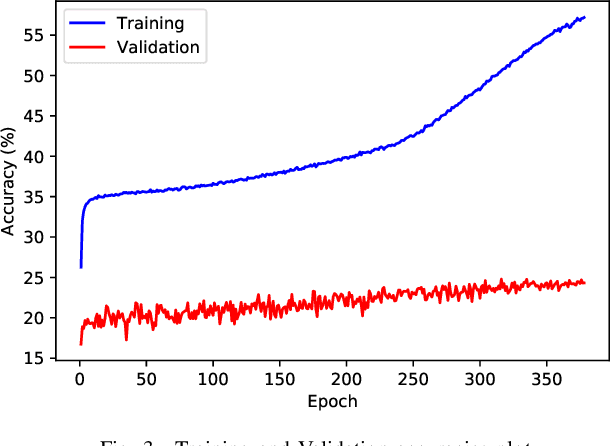
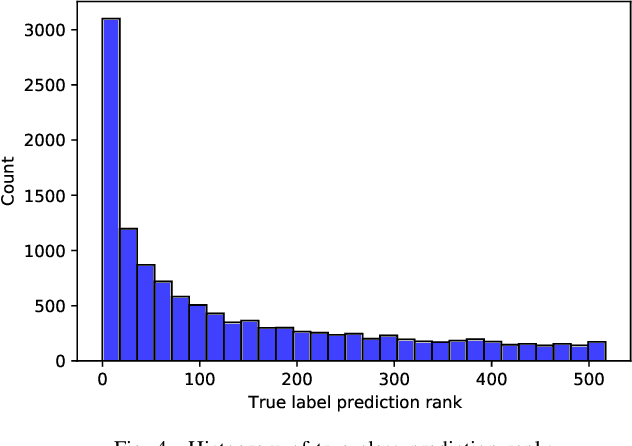
Lip-reading has made impressive progress in recent years, driven by advances in deep learning. Nonetheless, the prerequisite such advances is a suitable dataset. This paper provides a new in-the-wild dataset for Persian word-level lipreading containing 244,000 videos from approximately 1,800 speakers. We evaluated the state-of-the-art method in this field and used a novel approach for word-level lip-reading. In this method, we used the AV-HuBERT model for feature extraction and obtained significantly better performance on our dataset.
A Multi-Purpose Audio-Visual Corpus for Multi-Modal Persian Speech Recognition: the Arman-AV Dataset
Jan 21, 2023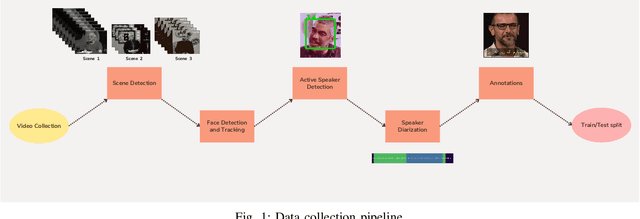

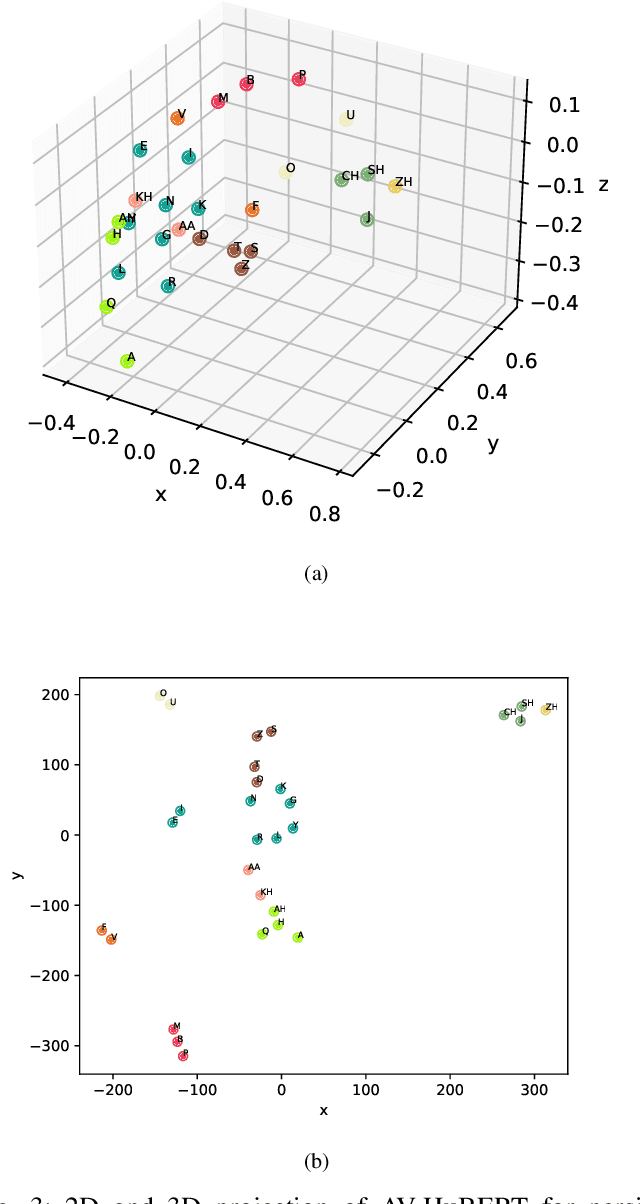
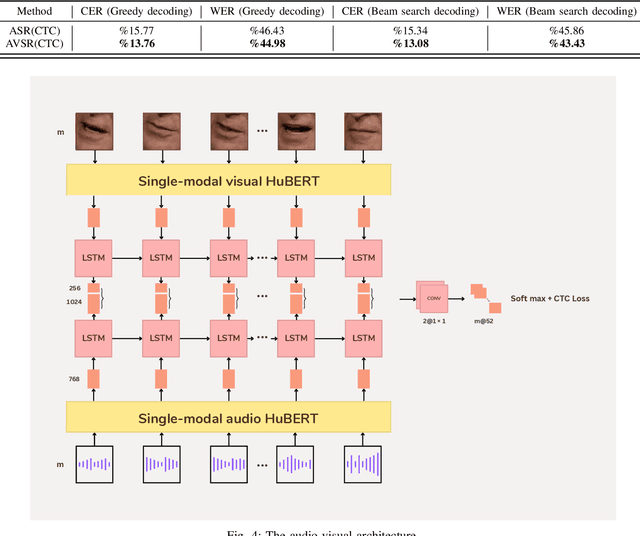
In recent years, significant progress has been made in automatic lip reading. But these methods require large-scale datasets that do not exist for many low-resource languages. In this paper, we have presented a new multipurpose audio-visual dataset for Persian. This dataset consists of almost 220 hours of videos with 1760 corresponding speakers. In addition to lip reading, the dataset is suitable for automatic speech recognition, audio-visual speech recognition, and speaker recognition. Also, it is the first large-scale lip reading dataset in Persian. A baseline method was provided for each mentioned task. In addition, we have proposed a technique to detect visemes (a visual equivalent of a phoneme) in Persian. The visemes obtained by this method increase the accuracy of the lip reading task by 7% relatively compared to the previously proposed visemes, which can be applied to other languages as well.