 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Visemes for Better Visual Speech Representation and Lip Reading
Jul 19, 2023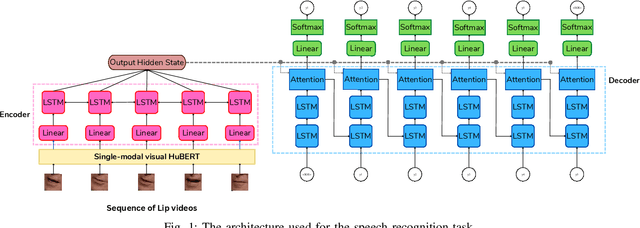
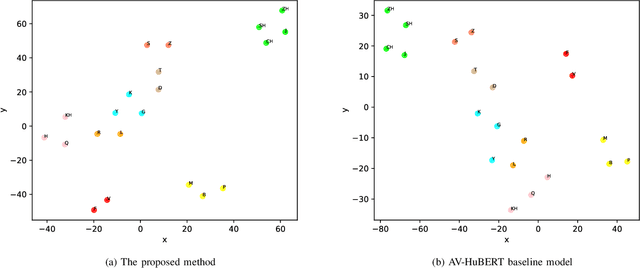
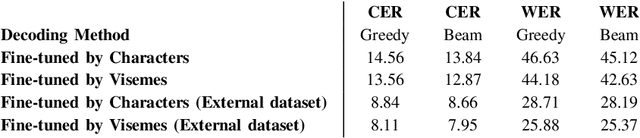
Lip reading is a challenging task that has many potential applications in speech recognition, human-computer interaction, and security systems. However, existing lip reading systems often suffer from low accuracy due to the limitations of video features. In this paper, we propose a novel approach that leverages visemes, which are groups of phonetically similar lip shapes, to extract more discriminative and robust video features for lip reading. We evaluate our approach on various tasks, including word-level and sentence-level lip reading, and audiovisual speech recognition using the Arman-AV dataset, a largescale Persian corpus. Our experimental results show that our viseme based approach consistently outperforms the state-of-theart methods in all these tasks. The proposed method reduces the lip-reading word error rate (WER) by 9.1% relative to the best previous method.
Word-level Persian Lipreading Dataset
Apr 08, 2023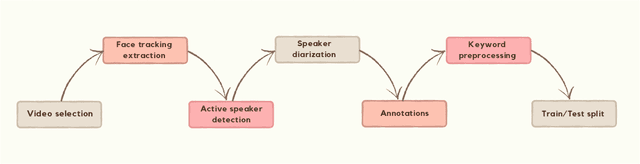

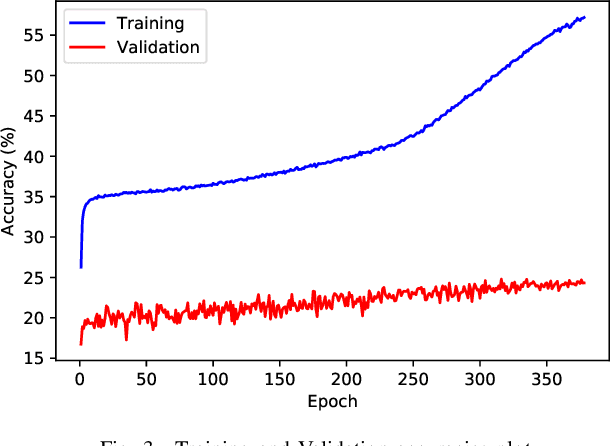
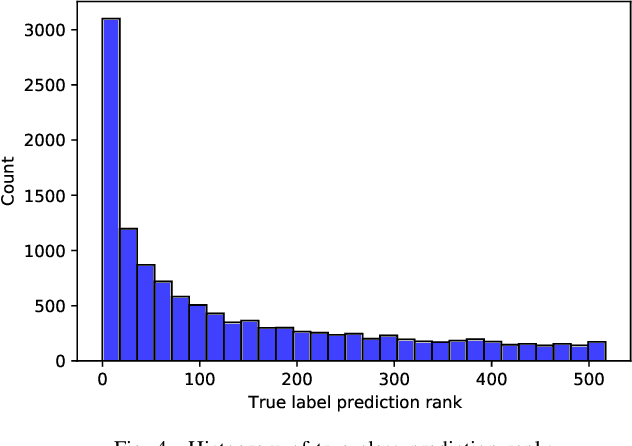
Lip-reading has made impressive progress in recent years, driven by advances in deep learning. Nonetheless, the prerequisite such advances is a suitable dataset. This paper provides a new in-the-wild dataset for Persian word-level lipreading containing 244,000 videos from approximately 1,800 speakers. We evaluated the state-of-the-art method in this field and used a novel approach for word-level lip-reading. In this method, we used the AV-HuBERT model for feature extraction and obtained significantly better performance on our dataset.
ArmanTTS single-speaker Persian dataset
Apr 07, 2023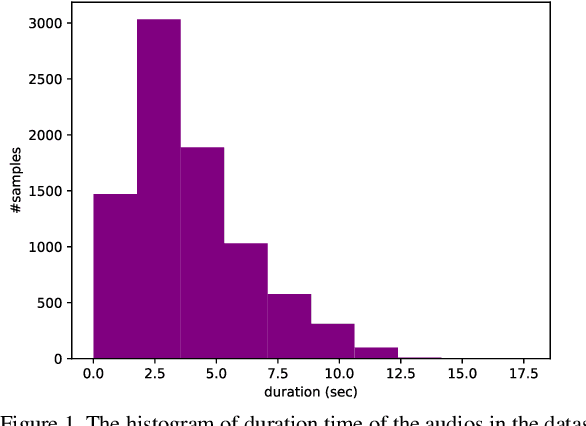
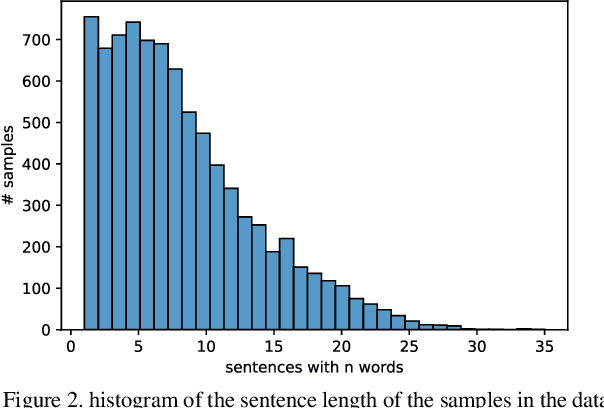
TTS, or text-to-speech, is a complicated process that can be accomplished through appropriate modeling using deep learning methods. In order to implement deep learning models, a suitable dataset is required. Since there is a scarce amount of work done in this field for the Persian language, this paper will introduce the single speaker dataset: ArmanTTS. We compared the characteristics of this dataset with those of various prevalent datasets to prove that ArmanTTS meets the necessary standards for teaching a Persian text-to-speech conversion model. We also combined the Tacotron 2 and HiFi GAN to design a model that can receive phonemes as input, with the output being the corresponding speech. 4.0 value of MOS was obtained from real speech, 3.87 value was obtained by the vocoder prediction and 2.98 value was reached with the synthetic speech generated by the TTS model.
A Multi-Purpose Audio-Visual Corpus for Multi-Modal Persian Speech Recognition: the Arman-AV Dataset
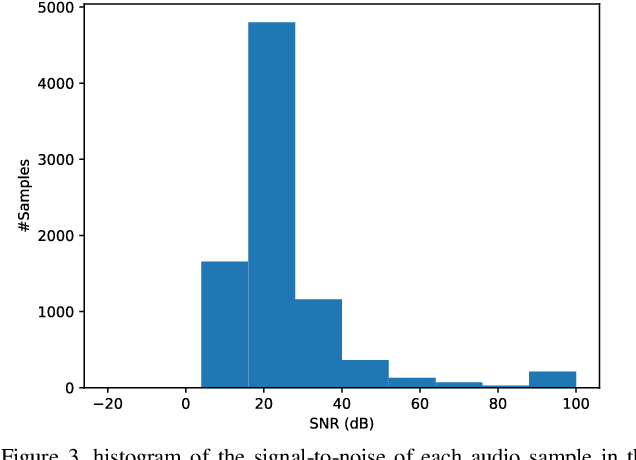
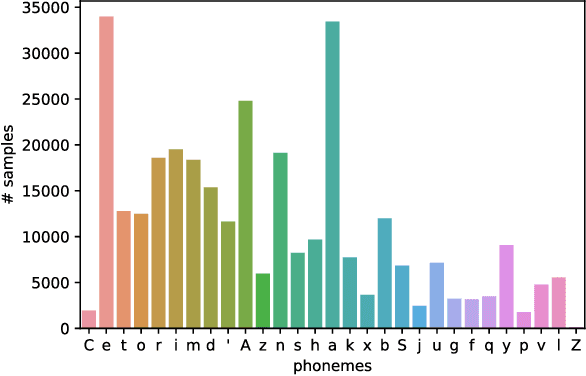
Jan 21, 2023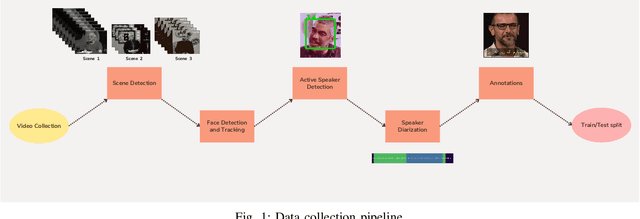

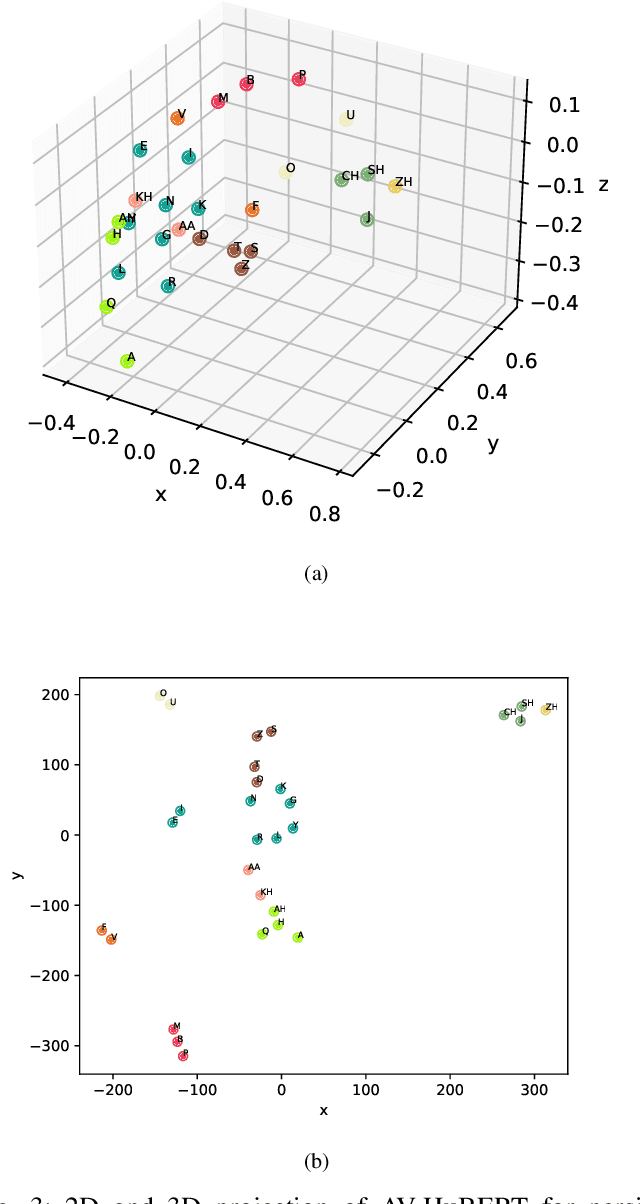
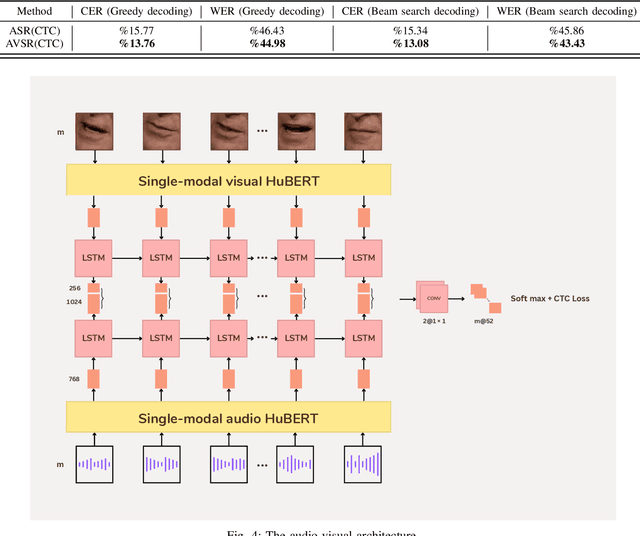
In recent years, significant progress has been made in automatic lip reading. But these methods require large-scale datasets that do not exist for many low-resource languages. In this paper, we have presented a new multipurpose audio-visual dataset for Persian. This dataset consists of almost 220 hours of videos with 1760 corresponding speakers. In addition to lip reading, the dataset is suitable for automatic speech recognition, audio-visual speech recognition, and speaker recognition. Also, it is the first large-scale lip reading dataset in Persian. A baseline method was provided for each mentioned task. In addition, we have proposed a technique to detect visemes (a visual equivalent of a phoneme) in Persian. The visemes obtained by this method increase the accuracy of the lip reading task by 7% relatively compared to the previously proposed visemes, which can be applied to other languages as well.
ArmanEmo: A Persian Dataset for Text-based Emotion Detection
Jul 24, 2022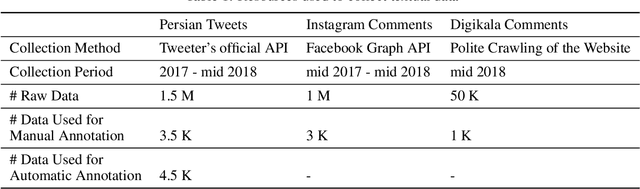
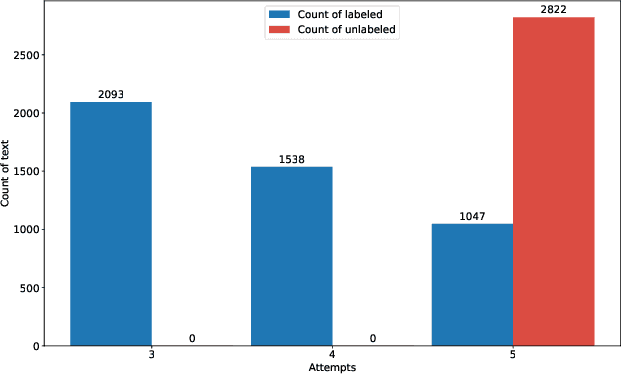
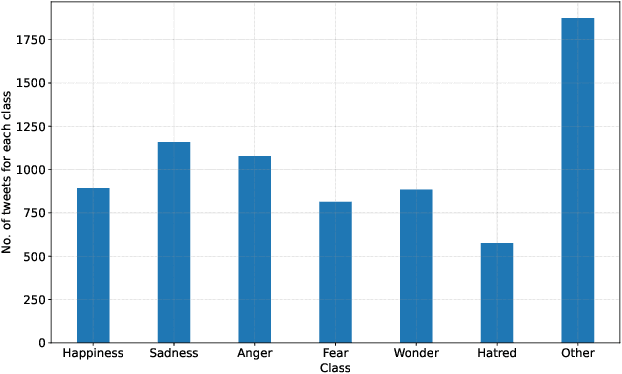
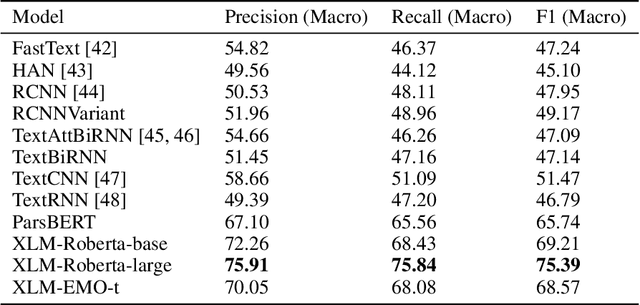
With the recent proliferation of open textual data on social media platforms, Emotion Detection (ED) from Text has received more attention over the past years. It has many applications, especially for businesses and online service providers, where emotion detection techniques can help them make informed commercial decisions by analyzing customers/users' feelings towards their products and services. In this study, we introduce ArmanEmo, a human-labeled emotion dataset of more than 7000 Persian sentences labeled for seven categories. The dataset has been collected from different resources, including Twitter, Instagram, and Digikala (an Iranian e-commerce company) comments. Labels are based on Ekman's six basic emotions (Anger, Fear, Happiness, Hatred, Sadness, Wonder) and another category (Other) to consider any other emotion not included in Ekman's model. Along with the dataset, we have provided several baseline models for emotion classification focusing on the state-of-the-art transformer-based language models. Our best model achieves a macro-averaged F1 score of 75.39 percent across our test dataset. Moreover, we also conduct transfer learning experiments to compare our proposed dataset's generalization against other Persian emotion datasets. Results of these experiments suggest that our dataset has superior generalizability among the existing Persian emotion datasets. ArmanEmo is publicly available for non-commercial use at https://github.com/Arman-Rayan-Sharif/arman-text-emotion.
Lip reading using external viseme decoding
Apr 10, 2021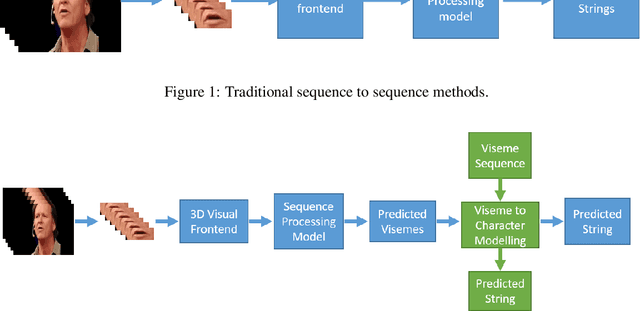


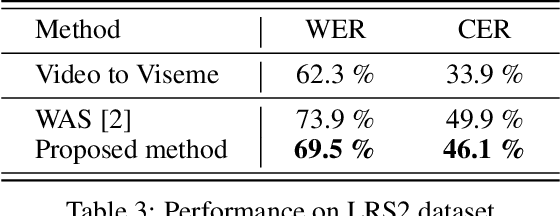
Lip-reading is the operation of recognizing speech from lip movements. This is a difficult task because the movements of the lips when pronouncing the words are similar for some of them. Viseme is used to describe lip movements during a conversation. This paper aims to show how to use external text data (for viseme-to-character mapping) by dividing video-to-character into two stages, namely converting video to viseme, and then converting viseme to character by using separate models. Our proposed method improves word error rate by 4\% compared to the normal sequence to sequence lip-reading model on the BBC-Oxford Lip Reading Sentences 2 (LRS2) dataset.