 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Visemes for Better Visual Speech Representation and Lip Reading
Jul 19, 2023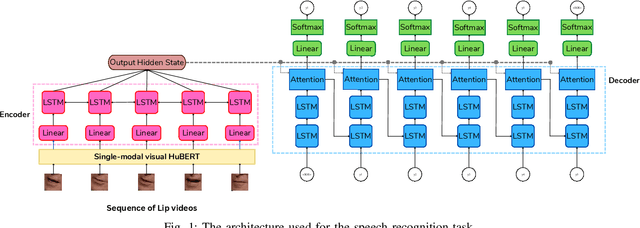
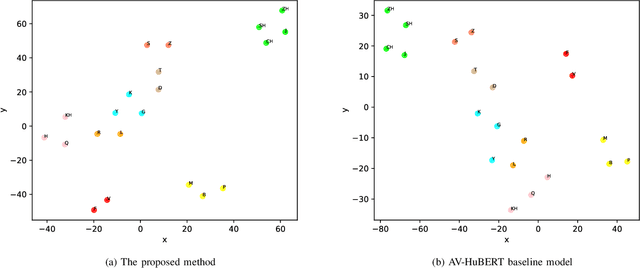
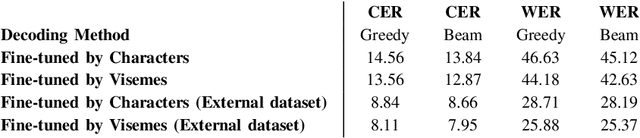
Lip reading is a challenging task that has many potential applications in speech recognition, human-computer interaction, and security systems. However, existing lip reading systems often suffer from low accuracy due to the limitations of video features. In this paper, we propose a novel approach that leverages visemes, which are groups of phonetically similar lip shapes, to extract more discriminative and robust video features for lip reading. We evaluate our approach on various tasks, including word-level and sentence-level lip reading, and audiovisual speech recognition using the Arman-AV dataset, a largescale Persian corpus. Our experimental results show that our viseme based approach consistently outperforms the state-of-theart methods in all these tasks. The proposed method reduces the lip-reading word error rate (WER) by 9.1% relative to the best previous method.
ArmanTTS single-speaker Persian dataset
Apr 07, 2023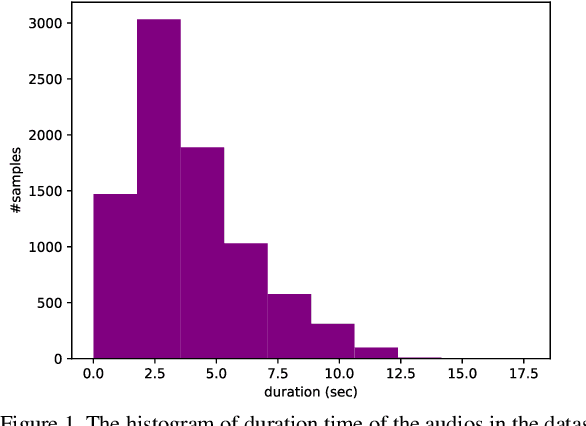
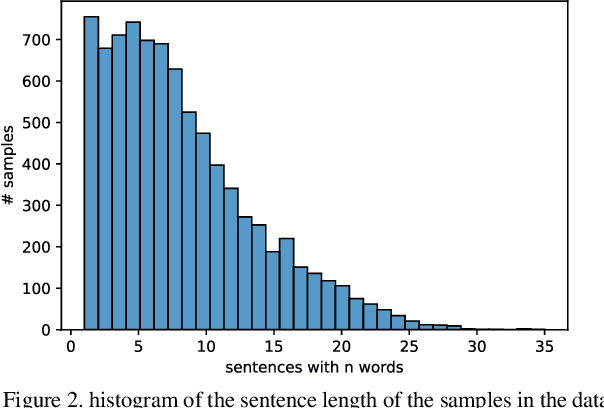
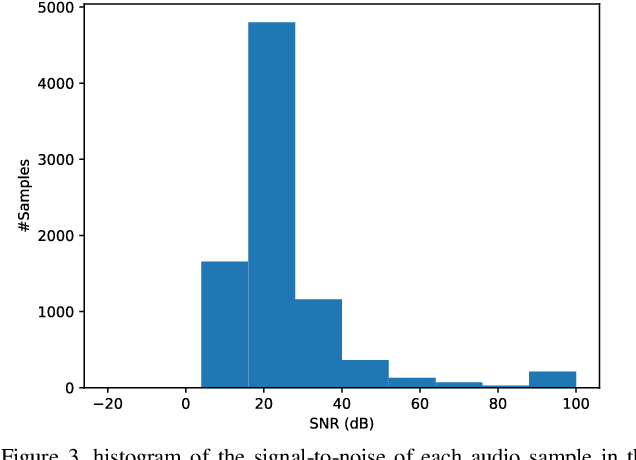
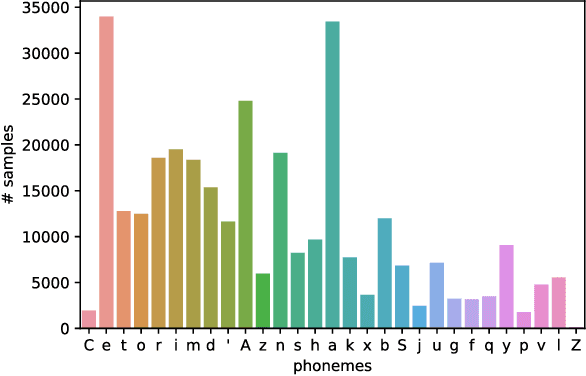
TTS, or text-to-speech, is a complicated process that can be accomplished through appropriate modeling using deep learning methods. In order to implement deep learning models, a suitable dataset is required. Since there is a scarce amount of work done in this field for the Persian language, this paper will introduce the single speaker dataset: ArmanTTS. We compared the characteristics of this dataset with those of various prevalent datasets to prove that ArmanTTS meets the necessary standards for teaching a Persian text-to-speech conversion model. We also combined the Tacotron 2 and HiFi GAN to design a model that can receive phonemes as input, with the output being the corresponding speech. 4.0 value of MOS was obtained from real speech, 3.87 value was obtained by the vocoder prediction and 2.98 value was reached with the synthetic speech generated by the TTS model.