 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new Potential-Based Reward Shaping for Reinforcement Learning Agent
Paper and Code
Feb 17, 2019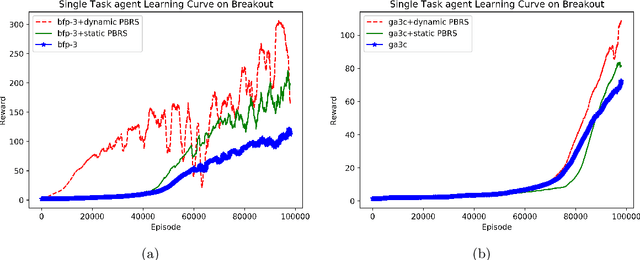
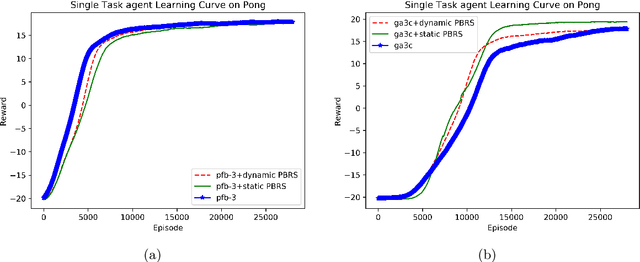

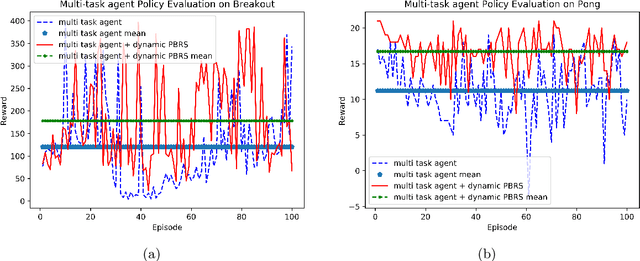
Potential-based reward shaping (PBRS) is a particular category of machine learning methods which aims to improve the learning speed of a reinforcement learning agent by extracting and utilizing extra knowledge while performing a task. There are two steps in the process of transfer learning: extracting knowledge from previously learned tasks and transferring that knowledge to use it in a target task. The latter step is well discussed in the literature with various methods being proposed for it, while the former has been explored less. With this in mind, the type of knowledge that is transmitted is very important and can lead to considerable improvement. Among the literature of both the transfer learning and the potential-based reward shaping, a subject that has never been addressed is the knowledge gathered during the learning process itself. In this paper, we presented a novel potential-based reward shaping method that attempted to extract knowledge from the learning process. The proposed method extracts knowledge from episodes' cumulative rewards. The proposed method has been evaluated in the Arcade learning environment and the results indicate an improvement in the learning process in both the single-task and the multi-task reinforcement learner agents.