 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElasticVR: Elastic Task Computing in Multi-User Multi-Connectivity Wireless Virtual Reality (VR) Systems
Dec 13, 2025Diverse emerging VR applications integrate streaming of high fidelity 360 video content that requires ample amounts of computation and data rate. Scalable 360 video tiling enables having elastic VR computational tasks that can be scaled adaptively in computation and data rate based on the available user and system resources. We integrate scalable 360 video tiling in an edge-client wireless multi-connectivity architecture for joint elastic task computation offloading across multiple VR users called ElasticVR. To balance the trade-offs in communication, computation, energy consumption, and QoE that arise herein, we formulate a constrained QoE and energy optimization problem that integrates the multi-user/multi-connectivity action space with the elasticity of VR computational tasks. The ElasticVR framework introduces two multi-agent deep reinforcement learning solutions, namely CPPG and IPPG. CPPG adopts a centralized training and centralized execution approach to capture the coupling between users' communication and computational demands. This leads to globally coordinated decisions at the cost of increased computational overheads and limited scalability. To address the latter challenges, we also explore an alternative strategy denoted IPPG that adopts a centralized training with decentralized execution paradigm. IPPG leverages shared information and parameter sharing to learn robust policies; however, during execution, each user takes action independently based on its local state information only. The decentralized execution alleviates the communication and computation overhead of centralized decision-making and improves scalability. We show that the ElasticVR framework improves the PSNR by 43.21%, while reducing the response time and energy consumption by 42.35% and 56.83%, respectively, compared with a case where no elasticity is incorporated into VR computations.
Multi-Task Decision-Making for Multi-User 360 Video Processing over Wireless Networks
Jul 03, 2024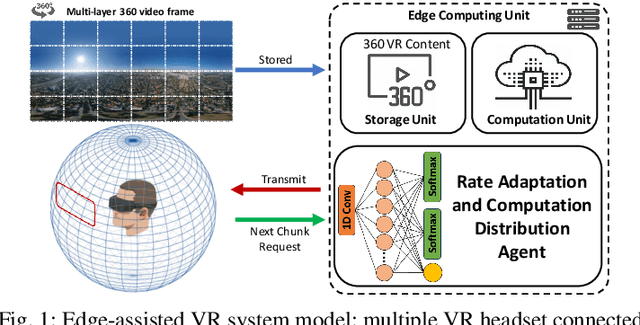
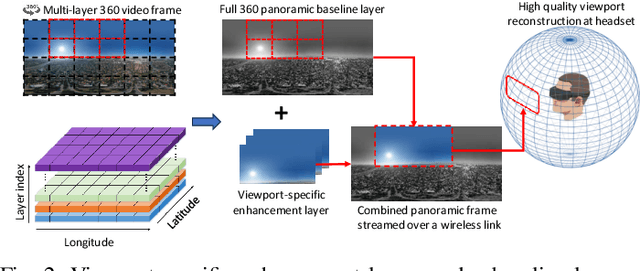
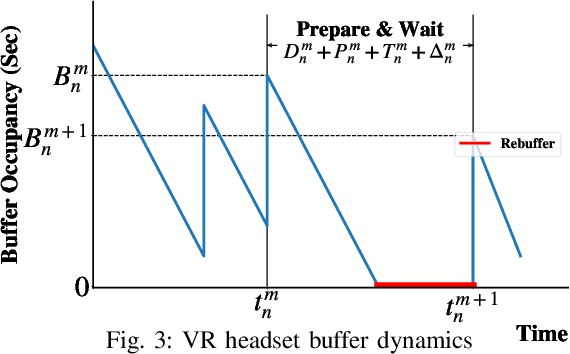
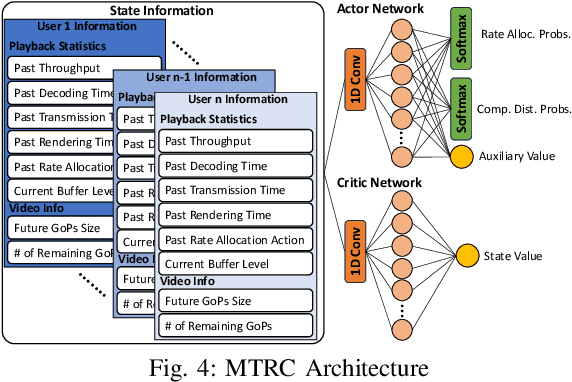
We study a multi-task decision-making problem for 360 video processing in a wireless multi-user virtual reality (VR) system that includes an edge computing unit (ECU) to deliver 360 videos to VR users and offer computing assistance for decoding/rendering of video frames. However, this comes at the expense of increased data volume and required bandwidth. To balance this trade-off, we formulate a constrained quality of experience (QoE) maximization problem in which the rebuffering time and quality variation between video frames are bounded by user and video requirements. To solve the formulated multi-user QoE maximization, we leverage deep reinforcement learning (DRL) for multi-task rate adaptation and computation distribution (MTRC). The proposed MTRC approach does not rely on any predefined assumption about the environment and relies on video playback statistics (i.e., past throughput, decoding time, transmission time, etc.), video information, and the resulting performance to adjust the video bitrate and computation distribution. We train MTRC with real-world wireless network traces and 360 video datasets to obtain evaluation results in terms of the average QoE, peak signal-to-noise ratio (PSNR), rebuffering time, and quality variation. Our results indicate that the MTRC improves the users' QoE compared to state-of-the-art rate adaptation algorithm. Specifically, we show a 5.97 dB to 6.44 dB improvement in PSNR, a 1.66X to 4.23X improvement in rebuffering time, and a 4.21 dB to 4.35 dB improvement in quality variation.
QoE-Centric Multi-User mmWave Scheduling: A Beam Alignment and Buffer Predictive Approach
Jul 01, 2022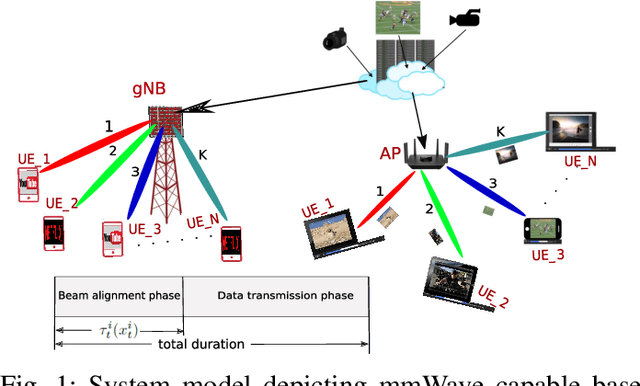
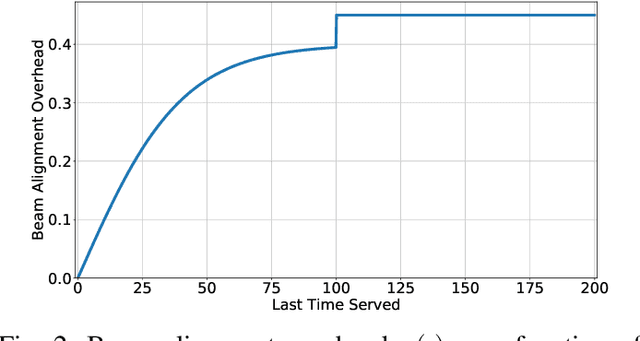
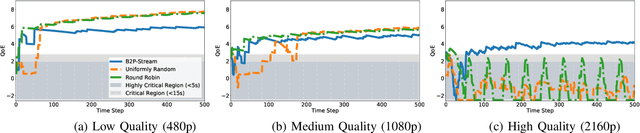
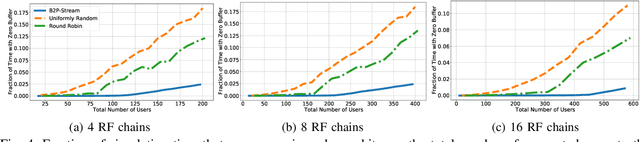
In this paper, we consider the multi-user scheduling problem in millimeter wave (mmWave) video streaming networks, which comprise a streaming server and several users, each requesting a video stream with a different resolution. The main objective is to optimize the long-term average quality of experience (QoE) for all users. We tackle this problem by considering the physical layer characteristics of the mmWave network, including the beam alignment overhead due to pencil-beams. To develop an efficient scheduling policy, we leverage the contextual multi-armed bandit (MAB) models to propose a beam alignment overhead and buffer predictive streaming solution, dubbed B2P-Stream. The proposed B2P-Stream algorithm optimally balances the trade-off between the overhead and users' buffer levels and improves the QoE by reducing the beam alignment overhead for users of higher resolutions. We also provide a theoretical guarantee for our proposed method and prove that it guarantees a sub-linear regret bound. Finally, we examine our proposed framework through extensive simulations. We provide a detailed comparison of the B2P-Stream against uniformly random and Round-robin (RR) policies and show that it outperforms both of them in providing a better QoE and fairness. We also analyze the scalability and robustness of the B2P-Stream algorithm with different network configurations.
Sampling-Based Nonlinear MPC of Neural Network Dynamics with Application to Autonomous Vehicle Motion Planning
May 09, 2022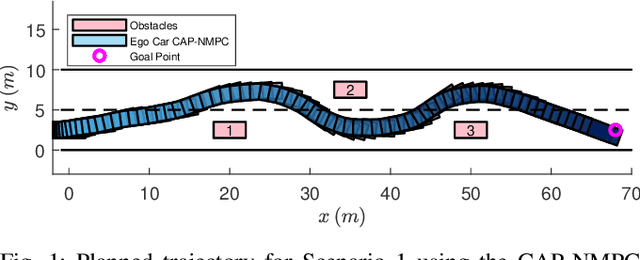
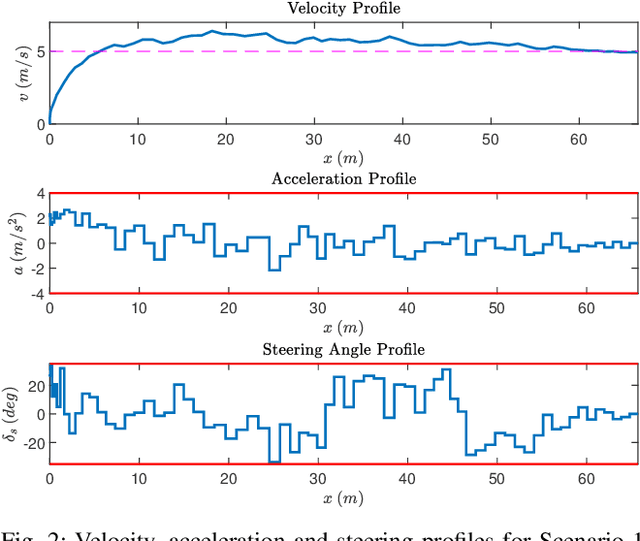
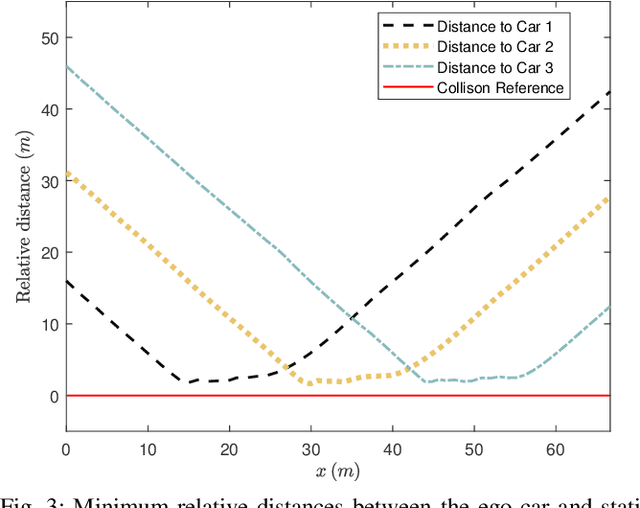
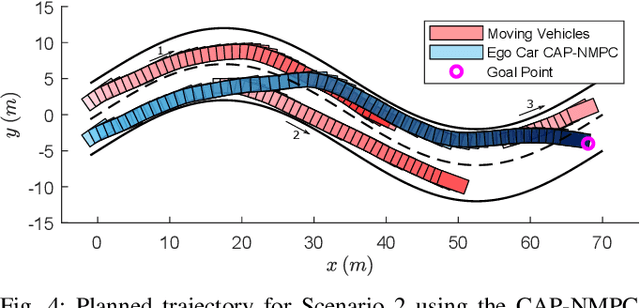
Control of machine learning models has emerged as an important paradigm for a broad range of robotics applications. In this paper, we present a sampling-based nonlinear model predictive control (NMPC) approach for control of neural network dynamics. We show its design in two parts: 1) formulating conventional optimization-based NMPC as a Bayesian state estimation problem, and 2) using particle filtering/smoothing to achieve the estimation. Through a principled sampling-based implementation, this approach can potentially make effective searches in the control action space for optimal control and also facilitate computation toward overcoming the challenges caused by neural network dynamics. We apply the proposed NMPC approach to motion planning for autonomous vehicles. The specific problem considers nonlinear unknown vehicle dynamics modeled as neural networks as well as dynamic on-road driving scenarios. The approach shows significant effectiveness in successful motion planning in case studies.
A new Potential-Based Reward Shaping for Reinforcement Learning Agent
Feb 17, 2019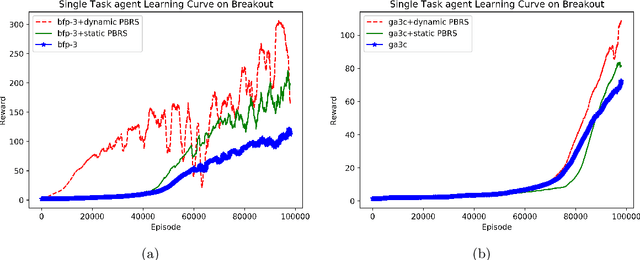
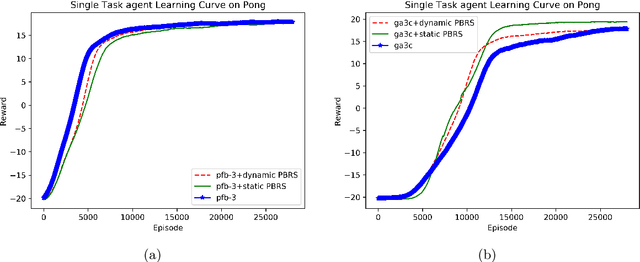

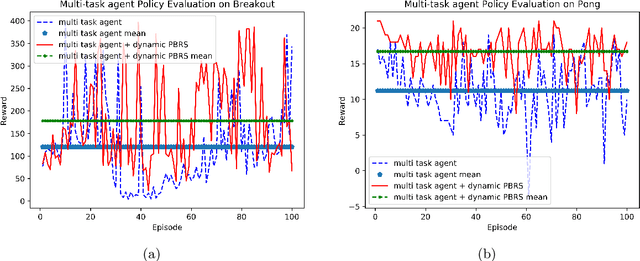
Potential-based reward shaping (PBRS) is a particular category of machine learning methods which aims to improve the learning speed of a reinforcement learning agent by extracting and utilizing extra knowledge while performing a task. There are two steps in the process of transfer learning: extracting knowledge from previously learned tasks and transferring that knowledge to use it in a target task. The latter step is well discussed in the literature with various methods being proposed for it, while the former has been explored less. With this in mind, the type of knowledge that is transmitted is very important and can lead to considerable improvement. Among the literature of both the transfer learning and the potential-based reward shaping, a subject that has never been addressed is the knowledge gathered during the learning process itself. In this paper, we presented a novel potential-based reward shaping method that attempted to extract knowledge from the learning process. The proposed method extracts knowledge from episodes' cumulative rewards. The proposed method has been evaluated in the Arcade learning environment and the results indicate an improvement in the learning process in both the single-task and the multi-task reinforcement learner agents.