 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Communication meets Natural Language: Synergies between Functional and Structural Language Learning
May 14, 2020
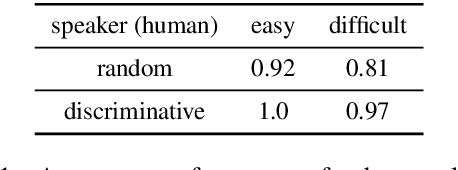
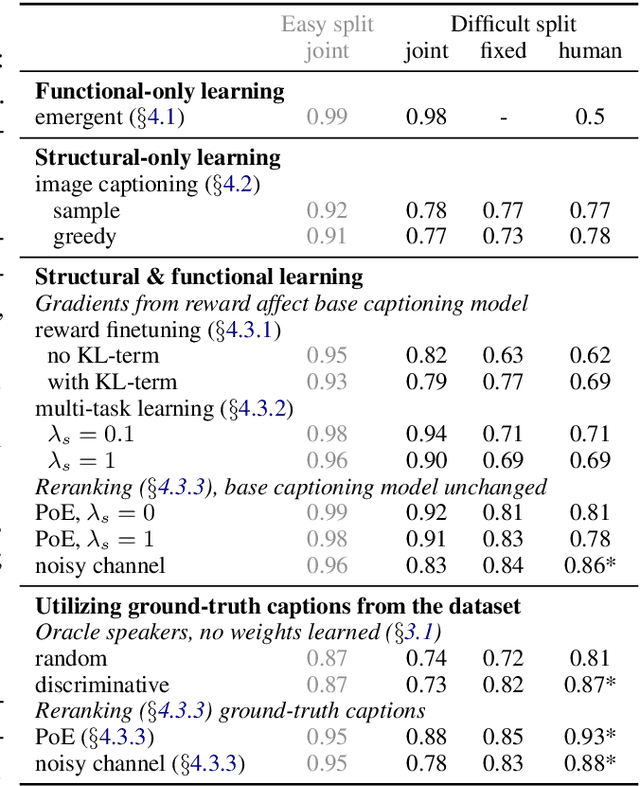
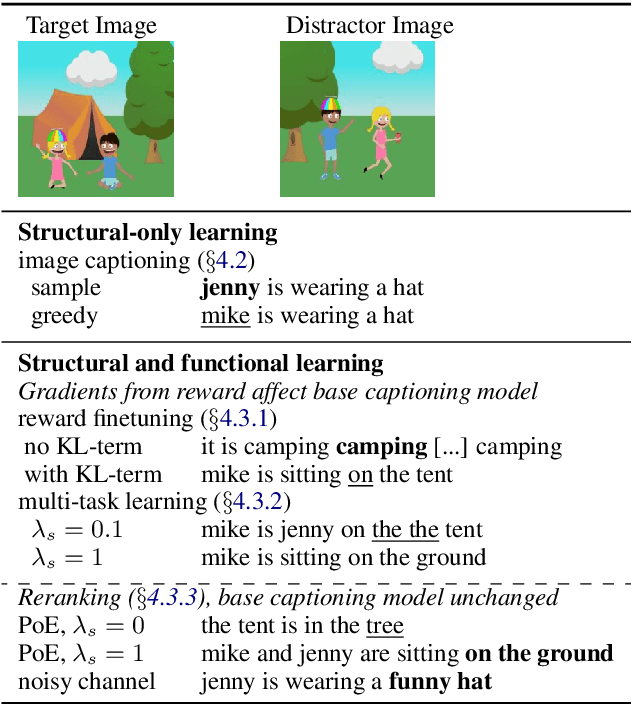
We present a method for combining multi-agent communication and traditional data-driven approaches to natural language learning, with an end goal of teaching agents to communicate with humans in natural language. Our starting point is a language model that has been trained on generic, not task-specific language data. We then place this model in a multi-agent self-play environment that generates task-specific rewards used to adapt or modulate the model, turning it into a task-conditional language model. We introduce a new way for combining the two types of learning based on the idea of reranking language model samples, and show that this method outperforms others in communicating with humans in a visual referential communication task. Finally, we present a taxonomy of different types of language drift that can occur alongside a set of measures to detect them.
Compressive Transformers for Long-Range Sequence Modelling
Nov 13, 2019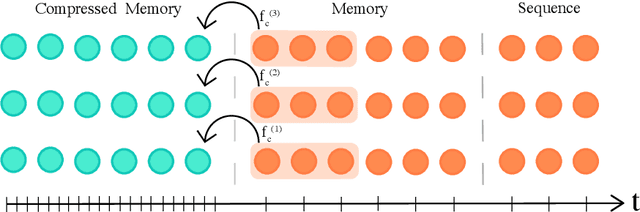
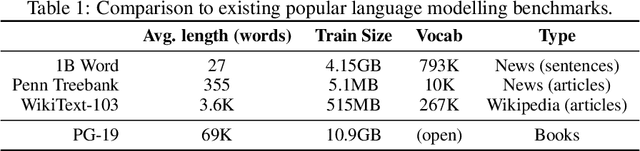
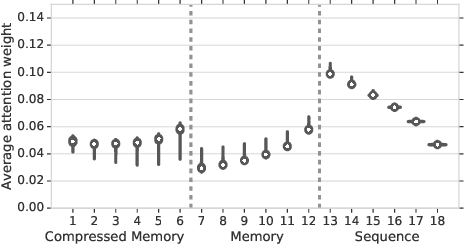
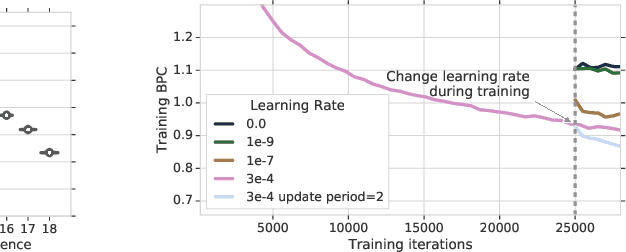
We present the Compressive Transformer, an attentive sequence model which compresses past memories for long-range sequence learning. We find the Compressive Transformer obtains state-of-the-art language modelling results in the WikiText-103 and Enwik8 benchmarks, achieving 17.1 ppl and 0.97 bpc respectively. We also find it can model high-frequency speech effectively and can be used as a memory mechanism for RL, demonstrated on an object matching task. To promote the domain of long-range sequence learning, we propose a new open-vocabulary language modelling benchmark derived from books, PG-19.
Learning and Evaluating Sparse Interpretable Sentence Embeddings
Sep 25, 2018

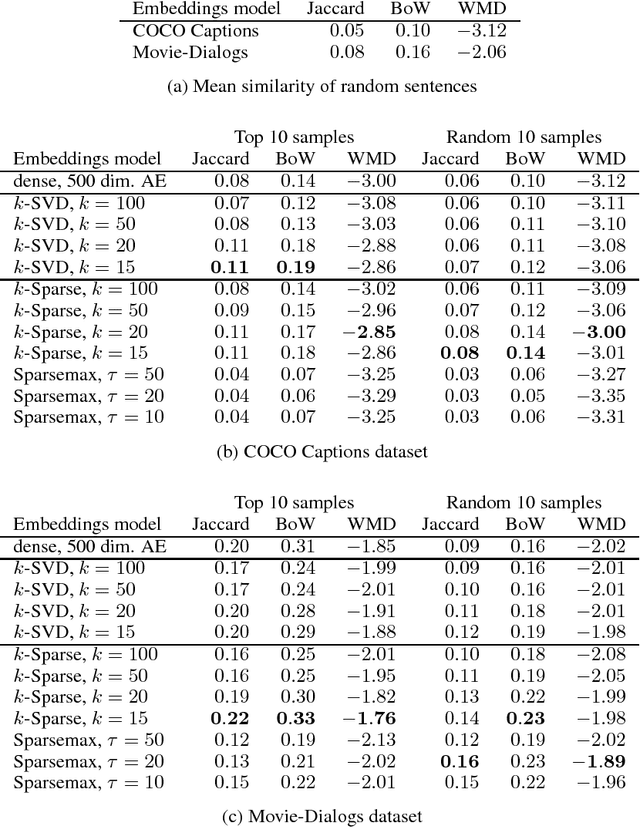
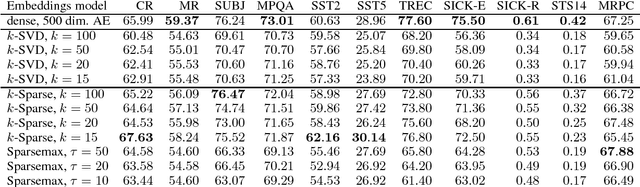
Previous research on word embeddings has shown that sparse representations, which can be either learned on top of existing dense embeddings or obtained through model constraints during training time, have the benefit of increased interpretability properties: to some degree, each dimension can be understood by a human and associated with a recognizable feature in the data. In this paper, we transfer this idea to sentence embeddings and explore several approaches to obtain a sparse representation. We further introduce a novel, quantitative and automated evaluation metric for sentence embedding interpretability, based on topic coherence methods. We observe an increase in interpretability compared to dense models, on a dataset of movie dialogs and on the scene descriptions from the MS COCO dataset.
Interpretable probabilistic embeddings: bridging the gap between topic models and neural networks
Nov 11, 2017
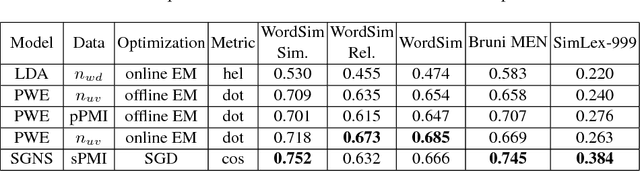
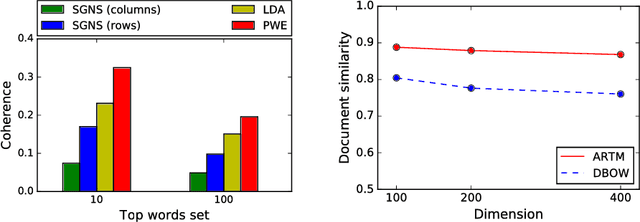
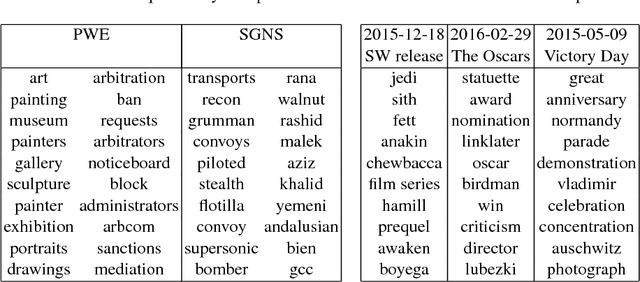
We consider probabilistic topic models and more recent word embedding techniques from a perspective of learning hidden semantic representations. Inspired by a striking similarity of the two approaches, we merge them and learn probabilistic embeddings with online EM-algorithm on word co-occurrence data. The resulting embeddings perform on par with Skip-Gram Negative Sampling (SGNS) on word similarity tasks and benefit in the interpretability of the components. Next, we learn probabilistic document embeddings that outperform paragraph2vec on a document similarity task and require less memory and time for training. Finally, we employ multimodal Additive Regularization of Topic Models (ARTM) to obtain a high sparsity and learn embeddings for other modalities, such as timestamps and categories. We observe further improvement of word similarity performance and meaningful inter-modality similarities.