 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Networks: novel framework for collaborative Multi-Agent Reinforcement Learning tasks
Dec 28, 2025Modern AI systems often comprise multiple learnable components that can be naturally organized as graphs. A central challenge is the end-to-end training of such systems without restrictive architectural or training assumptions. Such tasks fit the theory and approaches of the collaborative Multi-Agent Reinforcement Learning (MARL) field. We introduce Reinforcement Networks, a general framework for MARL that organizes agents as vertices in a directed acyclic graph (DAG). This structure extends hierarchical RL to arbitrary DAGs, enabling flexible credit assignment and scalable coordination while avoiding strict topologies, fully centralized training, and other limitations of current approaches. We formalize training and inference methods for the Reinforcement Networks framework and connect it to the LevelEnv concept to support reproducible construction, training, and evaluation. We demonstrate the effectiveness of our approach on several collaborative MARL setups by developing several Reinforcement Networks models that achieve improved performance over standard MARL baselines. Beyond empirical gains, Reinforcement Networks unify hierarchical, modular, and graph-structured views of MARL, opening a principled path toward designing and training complex multi-agent systems. We conclude with theoretical and practical directions - richer graph morphologies, compositional curricula, and graph-aware exploration. That positions Reinforcement Networks as a foundation for a new line of research in scalable, structured MARL.
Iterative Improvement of an Additively Regularized Topic Model
Aug 14, 2024
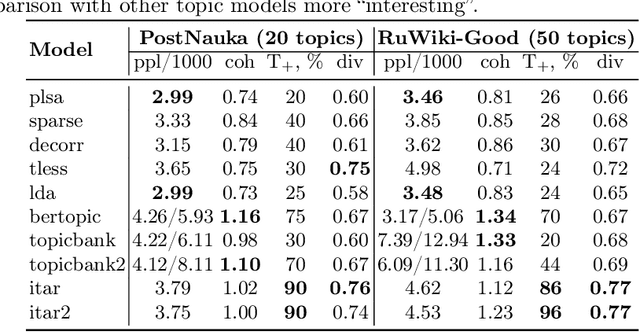

Topic modelling is fundamentally a soft clustering problem (of known objects -- documents, over unknown clusters -- topics). That is, the task is incorrectly posed. In particular, the topic models are unstable and incomplete. All this leads to the fact that the process of finding a good topic model (repeated hyperparameter selection, model training, and topic quality assessment) can be particularly long and labor-intensive. We aim to simplify the process, to make it more deterministic and provable. To this end, we present a method for iterative training of a topic model. The essence of the method is that a series of related topic models are trained so that each subsequent model is at least as good as the previous one, i.e., that it retains all the good topics found earlier. The connection between the models is achieved by additive regularization. The result of this iterative training is the last topic model in the series, which we call the iteratively updated additively regularized topic model (ITAR). Experiments conducted on several collections of natural language texts show that the proposed ITAR model performs better than other popular topic models (LDA, ARTM, BERTopic), its topics are diverse, and its perplexity (ability to "explain" the underlying data) is moderate.
Determination of the Number of Topics Intrinsically: Is It Possible?
Jun 14, 2024The number of topics might be the most important parameter of a topic model. The topic modelling community has developed a set of various procedures to estimate the number of topics in a dataset, but there has not yet been a sufficiently complete comparison of existing practices. This study attempts to partially fill this gap by investigating the performance of various methods applied to several topic models on a number of publicly available corpora. Further analysis demonstrates that intrinsic methods are far from being reliable and accurate tools. The number of topics is shown to be a method- and a model-dependent quantity, as opposed to being an absolute property of a particular corpus. We conclude that other methods for dealing with this problem should be developed and suggest some promising directions for further research.
Interpretable probabilistic embeddings: bridging the gap between topic models and neural networks
Nov 11, 2017
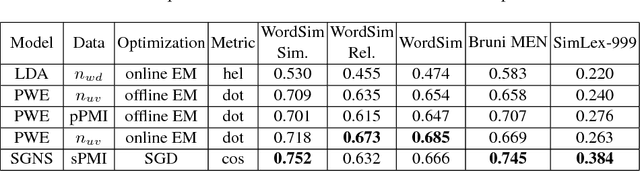
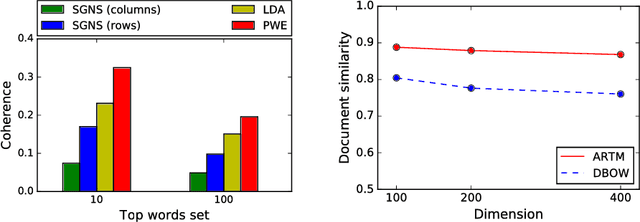
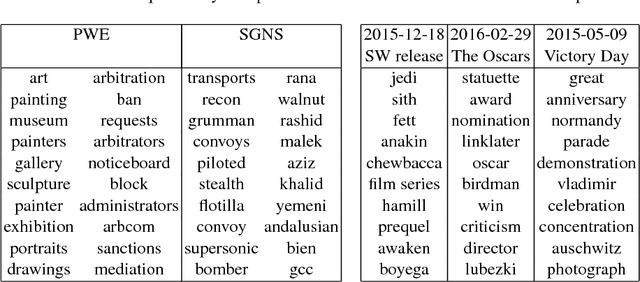
We consider probabilistic topic models and more recent word embedding techniques from a perspective of learning hidden semantic representations. Inspired by a striking similarity of the two approaches, we merge them and learn probabilistic embeddings with online EM-algorithm on word co-occurrence data. The resulting embeddings perform on par with Skip-Gram Negative Sampling (SGNS) on word similarity tasks and benefit in the interpretability of the components. Next, we learn probabilistic document embeddings that outperform paragraph2vec on a document similarity task and require less memory and time for training. Finally, we employ multimodal Additive Regularization of Topic Models (ARTM) to obtain a high sparsity and learn embeddings for other modalities, such as timestamps and categories. We observe further improvement of word similarity performance and meaningful inter-modality similarities.