 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Improvement of an Additively Regularized Topic Model
Aug 14, 2024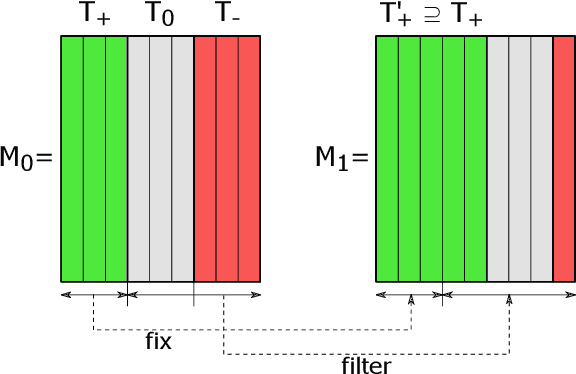
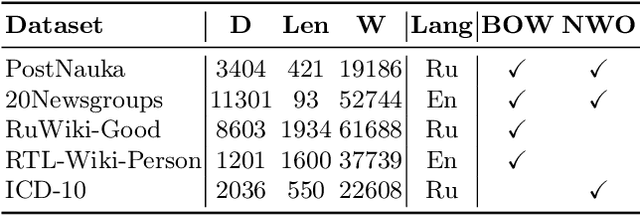
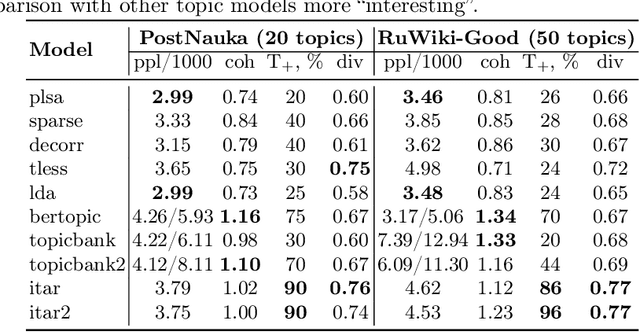

Topic modelling is fundamentally a soft clustering problem (of known objects -- documents, over unknown clusters -- topics). That is, the task is incorrectly posed. In particular, the topic models are unstable and incomplete. All this leads to the fact that the process of finding a good topic model (repeated hyperparameter selection, model training, and topic quality assessment) can be particularly long and labor-intensive. We aim to simplify the process, to make it more deterministic and provable. To this end, we present a method for iterative training of a topic model. The essence of the method is that a series of related topic models are trained so that each subsequent model is at least as good as the previous one, i.e., that it retains all the good topics found earlier. The connection between the models is achieved by additive regularization. The result of this iterative training is the last topic model in the series, which we call the iteratively updated additively regularized topic model (ITAR). Experiments conducted on several collections of natural language texts show that the proposed ITAR model performs better than other popular topic models (LDA, ARTM, BERTopic), its topics are diverse, and its perplexity (ability to "explain" the underlying data) is moderate.
Layer-Specific Optimization: Sensitivity Based Convolution Layers Basis Search
Aug 13, 2024Deep neural network models have a complex architecture and are overparameterized. The number of parameters is more than the whole dataset, which is highly resource-consuming. This complicates their application and limits its usage on different devices. Reduction in the number of network parameters helps to reduce the size of the model, but at the same time, thoughtlessly applied, can lead to a deterioration in the quality of the network. One way to reduce the number of model parameters is matrix decomposition, where a matrix is represented as a product of smaller matrices. In this paper, we propose a new way of applying the matrix decomposition with respect to the weights of convolutional layers. The essence of the method is to train not all convolutions, but only the subset of convolutions (basis convolutions), and represent the rest as linear combinations of the basis ones. Experiments on models from the ResNet family and the CIFAR-10 dataset demonstrate that basis convolutions can not only reduce the size of the model but also accelerate the forward and backward passes of the network. Another contribution of this work is that we propose a fast method for selecting a subset of network layers in which the use of matrix decomposition does not degrade the quality of the final model.
Determination of the Number of Topics Intrinsically: Is It Possible?
Jun 14, 2024The number of topics might be the most important parameter of a topic model. The topic modelling community has developed a set of various procedures to estimate the number of topics in a dataset, but there has not yet been a sufficiently complete comparison of existing practices. This study attempts to partially fill this gap by investigating the performance of various methods applied to several topic models on a number of publicly available corpora. Further analysis demonstrates that intrinsic methods are far from being reliable and accurate tools. The number of topics is shown to be a method- and a model-dependent quantity, as opposed to being an absolute property of a particular corpus. We conclude that other methods for dealing with this problem should be developed and suggest some promising directions for further research.