 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayer-Specific Optimization: Sensitivity Based Convolution Layers Basis Search
Aug 13, 2024Deep neural network models have a complex architecture and are overparameterized. The number of parameters is more than the whole dataset, which is highly resource-consuming. This complicates their application and limits its usage on different devices. Reduction in the number of network parameters helps to reduce the size of the model, but at the same time, thoughtlessly applied, can lead to a deterioration in the quality of the network. One way to reduce the number of model parameters is matrix decomposition, where a matrix is represented as a product of smaller matrices. In this paper, we propose a new way of applying the matrix decomposition with respect to the weights of convolutional layers. The essence of the method is to train not all convolutions, but only the subset of convolutions (basis convolutions), and represent the rest as linear combinations of the basis ones. Experiments on models from the ResNet family and the CIFAR-10 dataset demonstrate that basis convolutions can not only reduce the size of the model but also accelerate the forward and backward passes of the network. Another contribution of this work is that we propose a fast method for selecting a subset of network layers in which the use of matrix decomposition does not degrade the quality of the final model.
DDI-100: Dataset for Text Detection and Recognition
Dec 25, 2019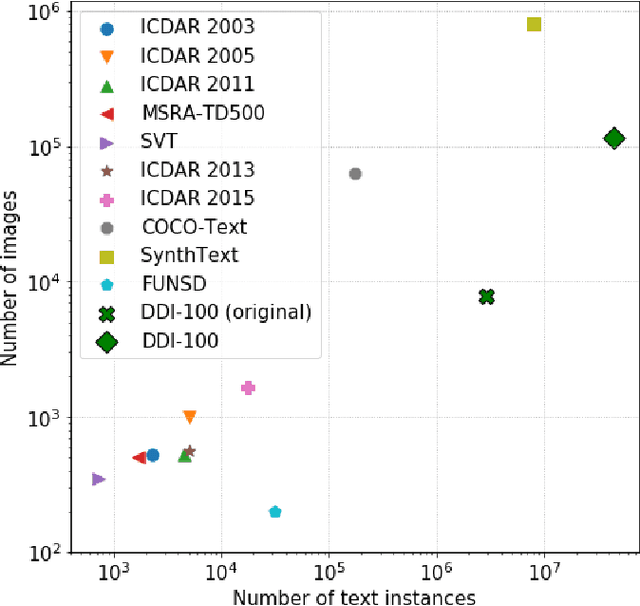
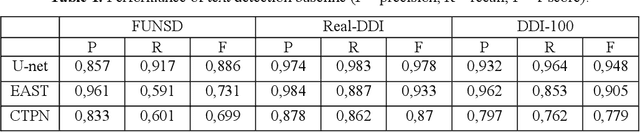


Nowadays document analysis and recognition remain challenging tasks. However, only a few datasets designed for text detection (TD) and optical character recognition (OCR) problems exist. In this paper we present Distorted Document Images dataset (DDI-100) and demonstrate its usefulness in a wide range of document analysis problems. DDI-100 dataset is a synthetic dataset based on 7000 real unique document pages and consists of more than 100000 augmented images. Ground truth comprises text and stamp masks, text and characters bounding boxes with relevant annotations. Validation of DDI-100 dataset was conducted using several TD and OCR models that show high-quality performance on real data.