Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDDI-100: Dataset for Text Detection and Recognition
Dec 25, 2019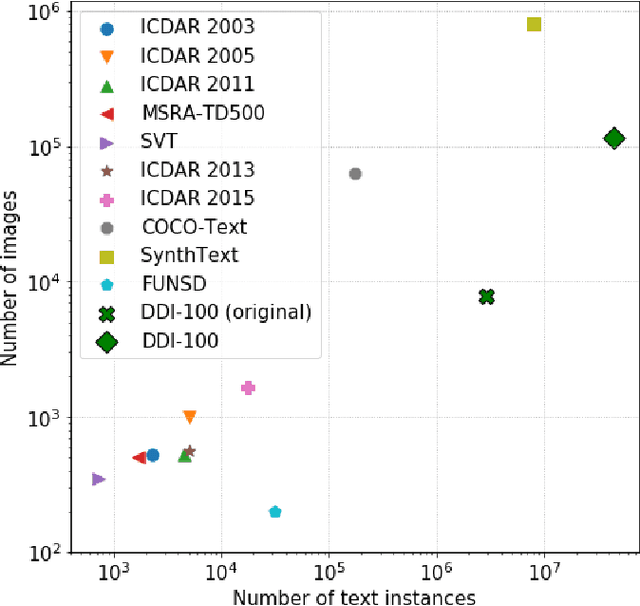
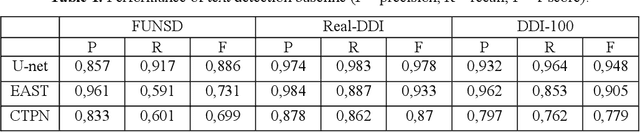


Nowadays document analysis and recognition remain challenging tasks. However, only a few datasets designed for text detection (TD) and optical character recognition (OCR) problems exist. In this paper we present Distorted Document Images dataset (DDI-100) and demonstrate its usefulness in a wide range of document analysis problems. DDI-100 dataset is a synthetic dataset based on 7000 real unique document pages and consists of more than 100000 augmented images. Ground truth comprises text and stamp masks, text and characters bounding boxes with relevant annotations. Validation of DDI-100 dataset was conducted using several TD and OCR models that show high-quality performance on real data.
* Accepted by CCVPR 2019. Dataset is available here:
https://github.com/machine-intelligence-laboratory/DDI-100
Via