 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVIBE: Visual Instruction Based Editor
Jan 05, 2026Instruction-based image editing is among the fastest developing areas in generative AI. Over the past year, the field has reached a new level, with dozens of open-source models released alongside highly capable commercial systems. However, only a limited number of open-source approaches currently achieve real-world quality. In addition, diffusion backbones, the dominant choice for these pipelines, are often large and computationally expensive for many deployments and research settings, with widely used variants typically containing 6B to 20B parameters. This paper presents a compact, high-throughput instruction-based image editing pipeline that uses a modern 2B-parameter Qwen3-VL model to guide the editing process and the 1.6B-parameter diffusion model Sana1.5 for image generation. Our design decisions across architecture, data processing, training configuration, and evaluation target low-cost inference and strict source consistency while maintaining high quality across the major edit categories feasible at this scale. Evaluated on the ImgEdit and GEdit benchmarks, the proposed method matches or exceeds the performance of substantially heavier baselines, including models with several times as many parameters and higher inference cost, and is particularly strong on edits that require preserving the input image, such as an attribute adjustment, object removal, background edits, and targeted replacement. The model fits within 24 GB of GPU memory and generates edited images at up to 2K resolution in approximately 4 seconds on an NVIDIA H100 in BF16, without additional inference optimizations or distillation.
NoHumansRequired: Autonomous High-Quality Image Editing Triplet Mining
Jul 18, 2025



Recent advances in generative modeling enable image editing assistants that follow natural language instructions without additional user input. Their supervised training requires millions of triplets: original image, instruction, edited image. Yet mining pixel-accurate examples is hard. Each edit must affect only prompt-specified regions, preserve stylistic coherence, respect physical plausibility, and retain visual appeal. The lack of robust automated edit-quality metrics hinders reliable automation at scale. We present an automated, modular pipeline that mines high-fidelity triplets across domains, resolutions, instruction complexities, and styles. Built on public generative models and running without human intervention, our system uses a task-tuned Gemini validator to score instruction adherence and aesthetics directly, removing any need for segmentation or grounding models. Inversion and compositional bootstrapping enlarge the mined set by approximately 2.2x, enabling large-scale high-fidelity training data. By automating the most repetitive annotation steps, the approach allows a new scale of training without human labeling effort. To democratize research in this resource-intensive area, we release NHR-Edit: an open dataset of 358k high-quality triplets. In the largest cross-dataset evaluation, it surpasses all public alternatives. We also release Bagel-NHR-Edit, an open-source fine-tuned Bagel model, which achieves state-of-the-art metrics in our experiments.
GigaCheck: Detecting LLM-generated Content
Oct 31, 2024



With the increasing quality and spread of LLM-based assistants, the amount of artificially generated content is growing rapidly. In many cases and tasks, such texts are already indistinguishable from those written by humans, and the quality of generation tends to only increase. At the same time, detection methods are developing more slowly, making it challenging to prevent misuse of these technologies. In this work, we investigate the task of generated text detection by proposing the GigaCheck. Our research explores two approaches: (i) distinguishing human-written texts from LLM-generated ones, and (ii) detecting LLM-generated intervals in Human-Machine collaborative texts. For the first task, our approach utilizes a general-purpose LLM, leveraging its extensive language abilities to fine-tune efficiently for the downstream task of LLM-generated text detection, achieving high performance even with limited data. For the second task, we propose a novel approach that combines computer vision and natural language processing techniques. Specifically, we use a fine-tuned general-purpose LLM in conjunction with a DETR-like detection model, adapted from computer vision, to localize artificially generated intervals within text. We evaluate the GigaCheck on five classification datasets with English texts and three datasets designed for Human-Machine collaborative text analysis. Our results demonstrate that GigaCheck outperforms previous methods, even in out-of-distribution settings, establishing a strong baseline across all datasets.
Saliency-Guided DETR for Moment Retrieval and Highlight Detection
Oct 02, 2024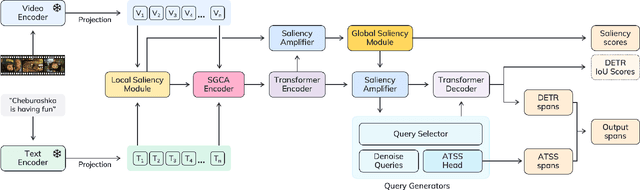
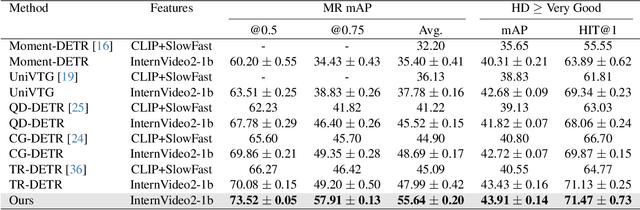
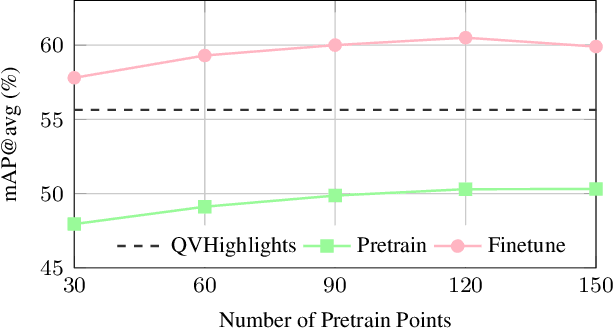

Existing approaches for video moment retrieval and highlight detection are not able to align text and video features efficiently, resulting in unsatisfying performance and limited production usage. To address this, we propose a novel architecture that utilizes recent foundational video models designed for such alignment. Combined with the introduced Saliency-Guided Cross Attention mechanism and a hybrid DETR architecture, our approach significantly enhances performance in both moment retrieval and highlight detection tasks. For even better improvement, we developed InterVid-MR, a large-scale and high-quality dataset for pretraining. Using it, our architecture achieves state-of-the-art results on the QVHighlights, Charades-STA and TACoS benchmarks. The proposed approach provides an efficient and scalable solution for both zero-shot and fine-tuning scenarios in video-language tasks.
DDI-100: Dataset for Text Detection and Recognition
Dec 25, 2019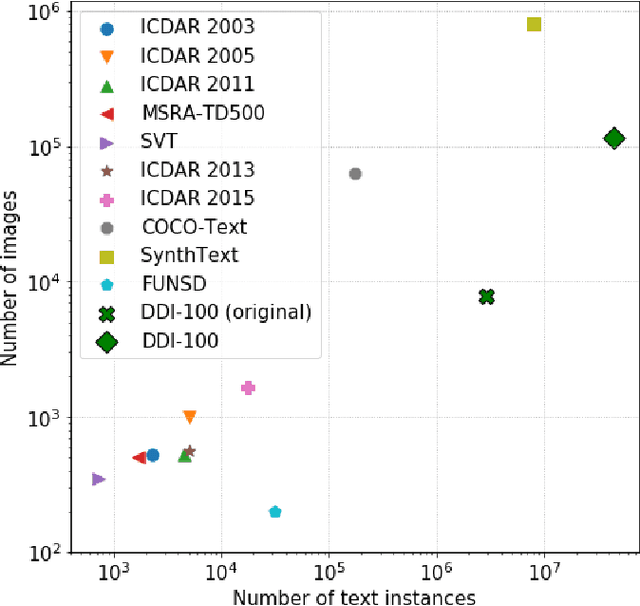
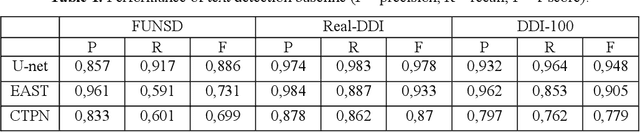


Nowadays document analysis and recognition remain challenging tasks. However, only a few datasets designed for text detection (TD) and optical character recognition (OCR) problems exist. In this paper we present Distorted Document Images dataset (DDI-100) and demonstrate its usefulness in a wide range of document analysis problems. DDI-100 dataset is a synthetic dataset based on 7000 real unique document pages and consists of more than 100000 augmented images. Ground truth comprises text and stamp masks, text and characters bounding boxes with relevant annotations. Validation of DDI-100 dataset was conducted using several TD and OCR models that show high-quality performance on real data.