 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency-Guided DETR for Moment Retrieval and Highlight Detection
Paper and Code
Oct 02, 2024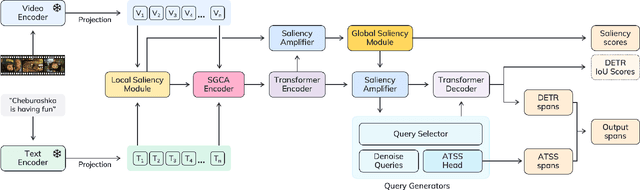
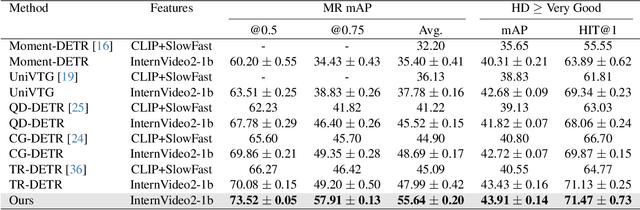
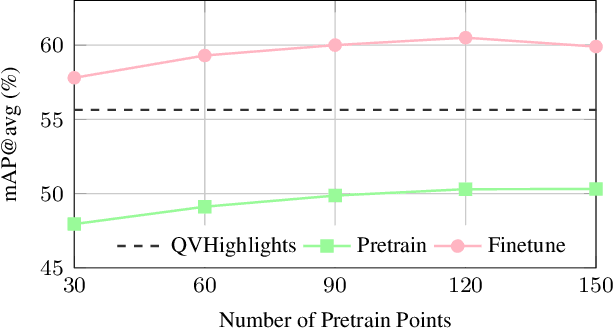

Existing approaches for video moment retrieval and highlight detection are not able to align text and video features efficiently, resulting in unsatisfying performance and limited production usage. To address this, we propose a novel architecture that utilizes recent foundational video models designed for such alignment. Combined with the introduced Saliency-Guided Cross Attention mechanism and a hybrid DETR architecture, our approach significantly enhances performance in both moment retrieval and highlight detection tasks. For even better improvement, we developed InterVid-MR, a large-scale and high-quality dataset for pretraining. Using it, our architecture achieves state-of-the-art results on the QVHighlights, Charades-STA and TACoS benchmarks. The proposed approach provides an efficient and scalable solution for both zero-shot and fine-tuning scenarios in video-language tasks.