 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Improvement of an Additively Regularized Topic Model
Paper and Code
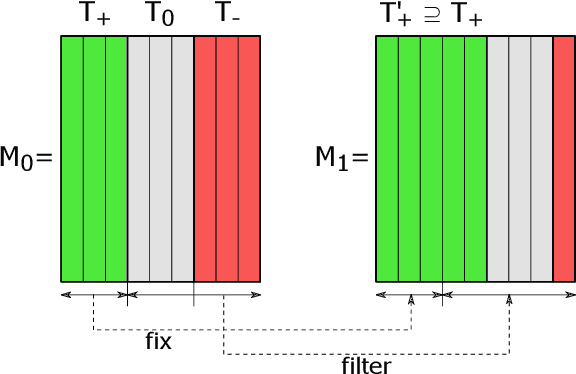
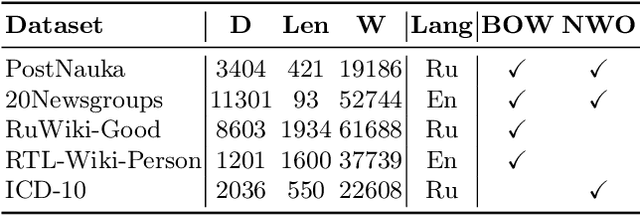
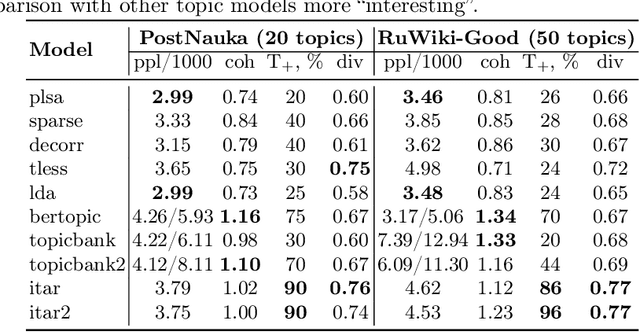

Topic modelling is fundamentally a soft clustering problem (of known objects -- documents, over unknown clusters -- topics). That is, the task is incorrectly posed. In particular, the topic models are unstable and incomplete. All this leads to the fact that the process of finding a good topic model (repeated hyperparameter selection, model training, and topic quality assessment) can be particularly long and labor-intensive. We aim to simplify the process, to make it more deterministic and provable. To this end, we present a method for iterative training of a topic model. The essence of the method is that a series of related topic models are trained so that each subsequent model is at least as good as the previous one, i.e., that it retains all the good topics found earlier. The connection between the models is achieved by additive regularization. The result of this iterative training is the last topic model in the series, which we call the iteratively updated additively regularized topic model (ITAR). Experiments conducted on several collections of natural language texts show that the proposed ITAR model performs better than other popular topic models (LDA, ARTM, BERTopic), its topics are diverse, and its perplexity (ability to "explain" the underlying data) is moderate.