 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating exploration and representation learning with offline pre-training
Paper and Code
Mar 31, 2023

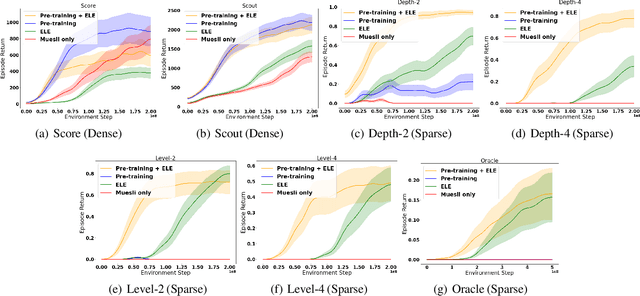
Sequential decision-making agents struggle with long horizon tasks, since solving them requires multi-step reasoning. Most reinforcement learning (RL) algorithms address this challenge by improved credit assignment, introducing memory capability, altering the agent's intrinsic motivation (i.e. exploration) or its worldview (i.e. knowledge representation). Many of these components could be learned from offline data. In this work, we follow the hypothesis that exploration and representation learning can be improved by separately learning two different models from a single offline dataset. We show that learning a state representation using noise-contrastive estimation and a model of auxiliary reward separately from a single collection of human demonstrations can significantly improve the sample efficiency on the challenging NetHack benchmark. We also ablate various components of our experimental setting and highlight crucial insights.