 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deployable Navigation Policies at Kilometer Scale from a Single Traversal
Paper and Code
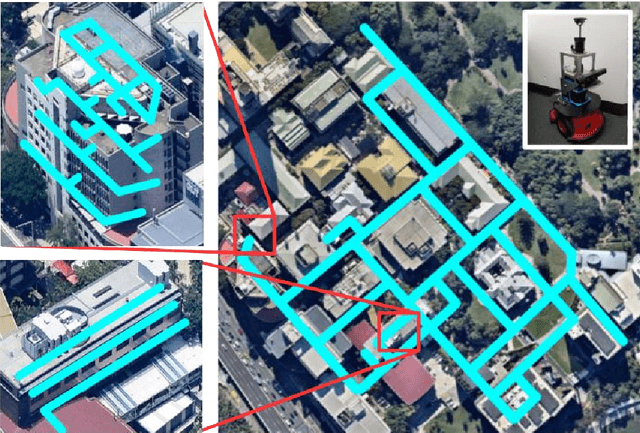
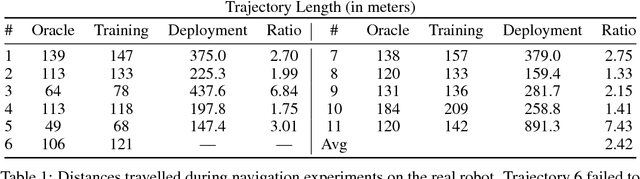

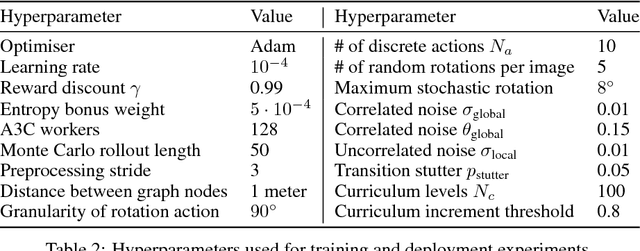
Model-free reinforcement learning has recently been shown to be effective at learning navigation policies from complex image input. However, these algorithms tend to require large amounts of interaction with the environment, which can be prohibitively costly to obtain on robots in the real world. We present an approach for efficiently learning goal-directed navigation policies on a mobile robot, from only a single coverage traversal of recorded data. The navigation agent learns an effective policy over a diverse action space in a large heterogeneous environment consisting of more than 2km of travel, through buildings and outdoor regions that collectively exhibit large variations in visual appearance, self-similarity, and connectivity. We compare pretrained visual encoders that enable precomputation of visual embeddings to achieve a throughput of tens of thousands of transitions per second at training time on a commodity desktop computer, allowing agents to learn from millions of trajectories of experience in a matter of hours. We propose multiple forms of computationally efficient stochastic augmentation to enable the learned policy to generalise beyond these precomputed embeddings, and demonstrate successful deployment of the learned policy on the real robot without fine tuning, despite environmental appearance differences at test time. The dataset and code required to reproduce these results and apply the technique to other datasets and robots is made publicly available at rl-navigation.github.io/deployable.