 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Kanerva Machine: A Generative Distributed Memory
Paper and Code
Jun 18, 2018
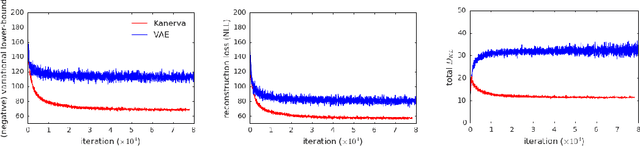


We present an end-to-end trained memory system that quickly adapts to new data and generates samples like them. Inspired by Kanerva's sparse distributed memory, it has a robust distributed reading and writing mechanism. The memory is analytically tractable, which enables optimal on-line compression via a Bayesian update-rule. We formulate it as a hierarchical conditional generative model, where memory provides a rich data-dependent prior distribution. Consequently, the top-down memory and bottom-up perception are combined to produce the code representing an observation. Empirically, we demonstrate that the adaptive memory significantly improves generative models trained on both the Omniglot and CIFAR datasets. Compared with the Differentiable Neural Computer (DNC) and its variants, our memory model has greater capacity and is significantly easier to train.